Лекция
Привет, Вы узнаете о том , что такое большая языковая модель, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое большая языковая модель, llm , настоятельно рекомендую прочитать все из категории Модели нейросетей и методы исследований систем искусственного интеллекта.
большая языковая модель ( БЯМ ) — это вычислительная модель , предназначенная для выполнения задач обработки естественного языка , особенно генерации языка , с использованием статистических шаблонов, полученных из больших текстовых корпусов. БЯМ могут генерировать, обобщать, переводить и анализировать текст во многих контекстах и являются основополагающей технологией современных чат-ботов . БЯМ могут создавать текст, напоминающий шаблоны естественного языка, поскольку они обучаются на коллекциях текста, написанного людьми . По той же причине предвзятые или неточные обучающие данные могут сделать результаты работы БЯМ менее надежными.
По состоянию на 2024 год, самые крупные и наиболее эффективные LLM основаны на архитектурах трансформеров , которые, согласно статье 2017 года «Внимание — это все, что вам нужно» , могут быть более эффективными и распараллеливаемыми, чем более ранние статистические и рекуррентные модели нейронных сетей . Исследования других архитектур, таких как модели пространства состояний , продолжаются .
Оценка эталонных моделей LLM направлена на измерение логики рассуждений модели , фактической точности, соответствия и безопасности .

До появления моделей на основе трансформеров в 2017 году некоторые языковые модели считались большими по сравнению с вычислительными и информационными ограничениями своего времени. В начале 1990-х годов статистические модели IBM первыми применили методы выравнивания слов для машинного перевода, заложив основу для корпусного языкового моделирования . В 2001 году сглаженная n- граммовая модель , например, использующая сглаживание Кнезера-Нея , обученная на 300 миллионах слов, достигла передового уровня перплексии на эталонных тестах. В 2000-х годах, с распространением интернета, исследователи начали собирать массивные текстовые наборы данных из сети («веб как корпус» ) для обучения статистических языковых моделей.
Выходя за рамки n -граммовых моделей, исследователи в 2000 году начали использовать нейронные сети для обучения языковых моделей. После прорыва глубоких нейронных сетей в классификации изображений примерно в 2012 году аналогичные архитектуры были адаптированы для языковых задач. Этот сдвиг был отмечен разработкой векторных представлений слов (например, Word2Vec Миколова в 2013 году) и моделей «последовательность-последовательность» ( seq2seq ) с использованием LSTM . В 2016 году Google перевел свой сервис перевода на нейронный машинный перевод (NMT), заменив статистические модели на основе фраз глубокими рекуррентными нейронными сетями . Эти ранние системы NMT использовали архитектуры кодировщик-декодировщик на основе LSTM , поскольку они предшествовали изобретению трансформеров .
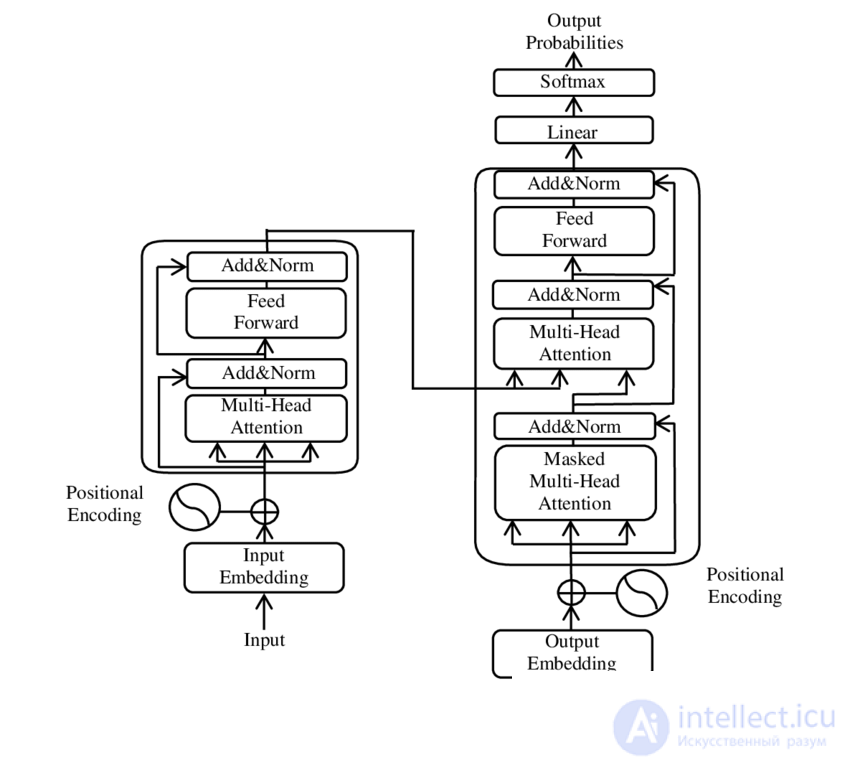
На конференции NeurIPS 2017 года исследователи Google представили архитектуру трансформера в своей знаковой статье « Внимание — это все, что вам нужно » . Целью этой статьи было улучшение технологии seq2seq 2014 года, и она основывалась главным образом на механизме внимания, разработанном Бахданау и др. в 2014 году . В следующем году, в 2018 году, был представлен BERT , который быстро стал «повсеместным» . Хотя оригинальный трансформер имеет как блоки кодировщика, так и декодера, BERT является моделью только с кодировщиком. Использование BERT в академических и исследовательских целях начало снижаться в 2023 году после быстрого улучшения возможностей моделей только с декодером (таких как GPT) решать задачи с помощью подсказок .
Хотя декодер GPT-1 был представлен в 2018 году, именно GPT-2 в 2019 году привлек широкое внимание, поскольку OpenAI заявила, что изначально сочла его слишком мощным для публичного выпуска из-за опасений злонамеренного использования. GPT-3 в 2020 году пошел еще дальше и по состоянию на 2025 год доступен только через API без возможности загрузки модели для локального выполнения. Но именно чат-бот ChatGPT , ориентированный на потребителя, выпущенный в 2022 году , получил широкое освещение в СМИ и привлек внимание общественности. GPT-4 2023 года был высоко оценен за повышенную точность и назван «святым Граалем» за свои мультимодальные возможности. OpenAI не раскрыла высокоуровневую архитектуру и количество параметров GPT-4. Выпуск ChatGPT привел к росту использования LLM в нескольких областях исследований компьютерных наук, включая робототехнику, разработку программного обеспечения и работу по социальному воздействию. В 2024 году OpenAI выпустила модель рассуждений OpenAI o1 , которая генерирует длинные цепочки мыслей, прежде чем вернуть окончательный ответ. Было разработано множество моделей LLM с количеством параметров, сопоставимым с количеством параметров серии GPT от OpenAI.
С 2022 года модели с доступными весами набирают популярность, особенно на первых порах с BLOOM и LLaMA , хотя обе имеют ограничения на использование и развертывание. Открытые модели весов Mistral AI , Mistral 7B и Mixtral 8x7B, имеют более либеральную лицензию Apache . В январе 2025 года DeepSeek выпустила DeepSeek R1, открытую модель весов с 671 миллиардом параметров, которая работает сопоставимо с OpenAI o1, но по гораздо более низкой цене за токен для пользователей.
Начиная с 2023 года многие LLM-модели были обучены быть мультимодальными , то есть способными обрабатывать или генерировать другие типы данных, такие как изображения, аудио или 3D-модели.
Модели с открытыми весами стали более влиятельными с 2023 года. По мнению Вейка и др. (2025), вклад сообщества в модели с открытыми весами повышает их эффективность и производительность с помощью таких платформ для совместной работы, как Hugging Face.
Поскольку алгоритмы машинного обучения обрабатывают числа, а не текст, текст необходимо преобразовать в числа. На первом этапе определяется словарь, затем каждому элементу словаря произвольно, но однозначно присваиваются целочисленные индексы, и, наконец, к целочисленному индексу связывается векторное представление . Алгоритмы включают кодирование пар байтов (BPE) и WordPiece. Также используются специальные токены, служащие в качестве управляющих символов , например, [MASK]для замаскированного токена (как используется в BERT ) и [UNK]("неизвестный") для символов, не встречающихся в словаре. Кроме того, для обозначения специального форматирования текста используются некоторые специальные символы. Например, "Ġ" обозначает предшествующий пробел в RoBERTa и GPT, а "##" обозначает продолжение предшествующего слова в BERT.
Например, токенизатор BPE, используемый в устаревшей версии GPT-3 , разделял бы данные tokenizer: texts -> series of numerical "tokens"следующим образом:
| токен | айзер | : | тексты | -> | ряд | из | численный | " | т | хорошо | енс | " |
Токенизация также сжимает наборы данных. Поскольку LLM обычно требуют, чтобы входными данными был массив , не имеющий зубчатых линий , более короткие тексты должны быть «дополнены» до тех пор, пока их длина не сравняется с длиной самого длинного текста. По словам Йенни Джун , среднее количество слов на токен зависит от языка.
В качестве примера рассмотрим токенизатор, основанный на кодировании пар байтов. На первом этапе все уникальные символы (включая пробелы и знаки препинания ) рассматриваются как начальный набор n- грамм (т.е. начальный набор униграмм). Затем наиболее часто встречающаяся пара смежных символов объединяется в биграмму, и все экземпляры этой пары заменяются ею. Все вхождения смежных пар (ранее объединенных) n -грамм, которые наиболее часто встречаются вместе, затем снова объединяются в еще более длинную n- грамму, пока не будет получен словарь заданного размера. После обучения токенизатора любой текст может быть токенизирован им, если он не содержит символов, не встречающихся в начальном наборе униграмм.
В контексте обучения LLM наборы данных обычно очищаются путем удаления низкокачественных, дублирующихся или токсичных данных. Очищенные наборы данных могут повысить эффективность обучения и привести к улучшению производительности в дальнейшем. Обученный LLM может быть использован для очистки наборов данных для обучения следующего LLM.
С увеличением доли контента, созданного с помощью LLM, в интернете, очистка данных в будущем может включать фильтрацию такого контента. Контент, созданный с помощью LLM, может представлять проблему, если он похож на человеческий текст (что затрудняет фильтрацию), но имеет более низкое качество (что ухудшает производительность моделей, обученных на нем).
Для обучения самых крупных языковых моделей может потребоваться больше лингвистических данных, чем имеется в природе, или же качество имеющихся данных может быть недостаточным. В таких случаях могут использоваться синтетические данные.
LLM — это тип базовой модели (большая X-модель), обученной на языке. LLM можно обучать разными способами. В частности, модели GPT сначала предварительно обучаются для предсказания следующего слова на большом объеме данных, а затем дообучаются.
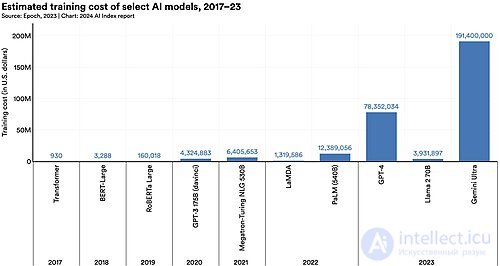
Для обучения самых больших моделей необходима существенная инфраструктура. Тенденция к увеличению размеров моделей видна в списке крупных языковых моделей . Например, обучение GPT-2 (то есть модели с 1,5 миллиардами параметров) в 2019 году обошлось в 50 000 долларов, в то время как обучение PaLM ( то есть модели с 540 миллиардами параметров) в 2022 году стоило 8 миллионов долларов, а Megatron-Turing NLG 530B (в 2021 году) — около 11 миллионов долларов. Определение «большая» в выражении «большая языковая модель» по своей сути расплывчато, поскольку нет определенного порогового значения для количества параметров, необходимых для того, чтобы модель считалась «большой».
До тонкой настройки большинство LLM являются предикторами следующего токена. Тонкая настройка формирует поведение LLM с помощью таких методов, как обучение с подкреплением на основе обратной связи от человека (RLHF) или конституциональный ИИ .
Тонкая настройка инструкций — это форма контролируемого обучения, используемая для обучения LLM следовать инструкциям пользователя. В 2022 году OpenAI продемонстрировала InstructGPT , версию GPT-3, аналогично доработанную для следования инструкциям.
Обучение с подкреплением на основе обратной связи от человека (RLHF) включает в себя обучение модели вознаграждения для прогнозирования того, какой текст люди предпочитают. Затем LLM может быть доработан с помощью обучения с подкреплением, чтобы лучше соответствовать этой модели вознаграждения. Поскольку люди обычно предпочитают правдивые, полезные и безвредные ответы, RLHF отдает предпочтение именно таким ответам.
Модели с линейной архитектурой (LLM) обычно основаны на архитектуре трансформера , которая использует механизм внимания , позволяющий модели обрабатывать взаимосвязи между всеми элементами последовательности одновременно, независимо от их расстояния друг от друга.
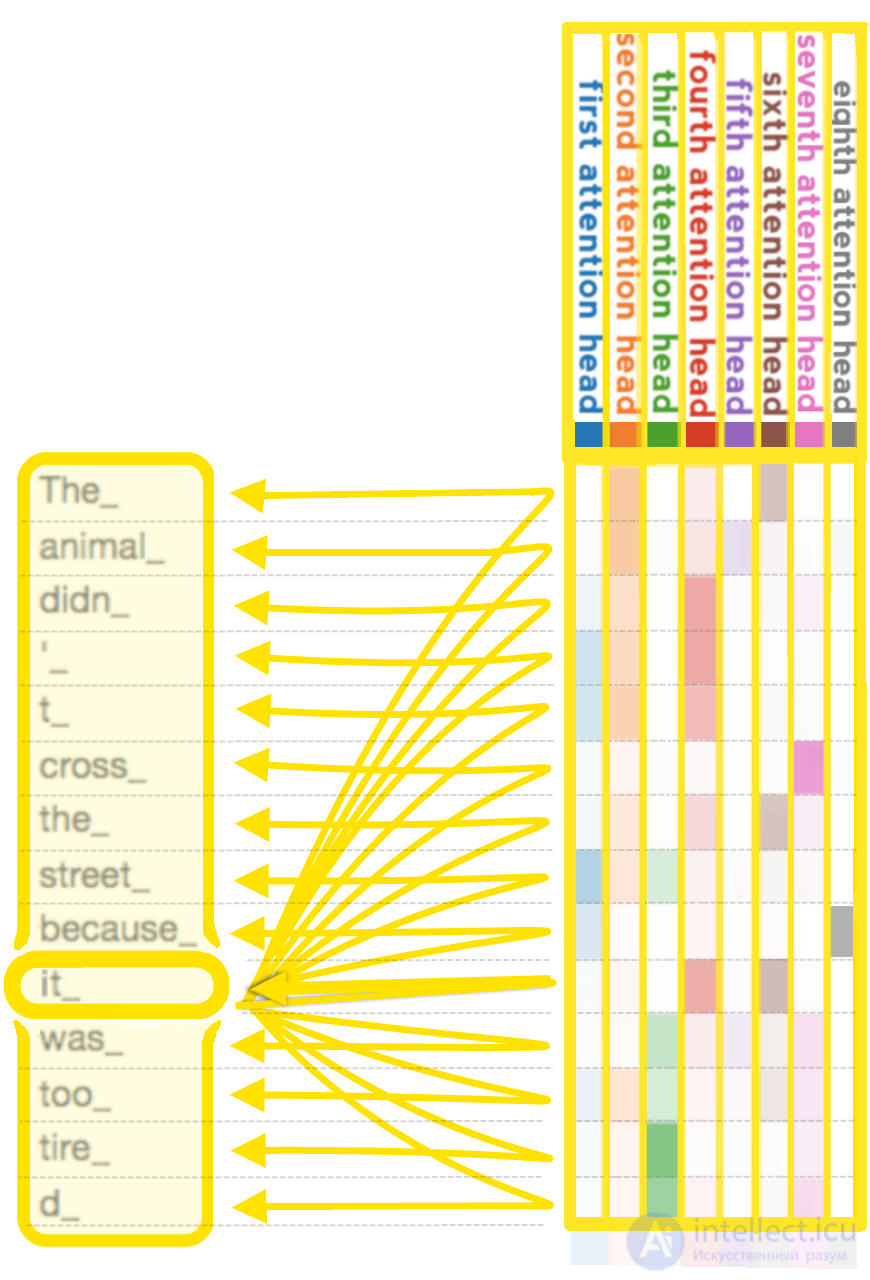
Чтобы определить, какие токены релевантны друг другу в пределах контекстного окна, механизм внимания вычисляет «мягкие» веса для каждого токена, точнее, для его встраивания, используя несколько механизмов внимания, каждый со своей собственной «релевантностью» для вычисления своих собственных мягких весов. Например, небольшая модель GPT-2 (т.е. с размером параметра 117 млн) имела двенадцать механизмов внимания и контекстное окно всего в 1000 токенов. В своей средней версии она имеет 345 млн параметров и содержит 24 слоя, каждый с 12 механизмами внимания. Для обучения с градиентным спуском использовался размер пакета 512.
Авторегрессивные модели, такие как GPT , обучаются угадывать, как продолжается последовательность; например, за какой частью последовательности слов «Мне нравится есть» с большей вероятностью последует слово «хлеб» или слово «камни». Маскированные модели, такие как BERT , обучаются угадывать части, отсутствующие в последовательности, например, за каким словом в последовательности «Мне нравится ___ розы» с большей вероятностью будет слово «запах» или слово «есть». Предсказания модели основаны на свойствах последовательностей в ее обучающем наборе данных.
Смесь экспертов (MoE) — это архитектура машинного обучения , в которой несколько специализированных нейронных сетей («экспертов») работают вместе, с механизмом управления, который направляет каждый вход к наиболее подходящему эксперту (экспертам). Смеси экспертов могут снизить затраты на вывод, поскольку для каждого входа используется лишь часть параметров.
Как правило, LLM обучаются с использованием чисел с плавающей запятой одинарной или половинной точности (float32 и float16). Одно число float16 имеет 16 бит, или 2 байта, поэтому для одного миллиарда параметров требуется 2 гигабайта. Самые большие модели обычно имеют более 100 миллиардов параметров, что делает их недоступными для большинства потребительских электронных устройств.
Квантование после обучения направлено на уменьшение требований к памяти за счет снижения точности параметров обученной модели, сохраняя при этом большую часть ее производительности. Квантование можно дополнительно классифицировать как статическое квантование , если параметры квантования определяются заранее (обычно на этапе калибровки), и динамическое квантование, если квантование применяется во время вывода. Простейшая форма квантования просто обрезает все параметры до заданного количества битов: это применимо как к статическому, так и к динамическому квантованию, но при этом теряется значительная точность. Динамическое квантование позволяет использовать разную книгу кодов квантования для каждого слоя, либо таблицу значений, либо линейное отображение (масштабный коэффициент и смещение), ценой отказа от возможного повышения скорости за счет использования арифметики с более низкой точностью.
Возможно доработать квантованные модели с помощью адаптации низкого ранга .
Помимо базовой генерации текста, были разработаны различные методы для расширения возможностей LLM, включая использование внешних инструментов и источников данных, улучшенное рассуждение при решении сложных проблем, а также улучшенное следование инструкциям или автономность за счет методов подсказок.
В 2020 году исследователи OpenAI продемонстрировали, что их новая модель GPT-3 может понимать, какой формат использовать, имея в качестве примера несколько раундов вопросов и ответов (или других типов задач) во входных данных, отчасти благодаря технике RLHF. Эта техника, называемая подсказкой с малым количеством примеров , позволяет LLM адаптироваться к любой задаче без необходимости тонкой настройки. Также в 2022 году было обнаружено, что базовая модель GPT-3 может генерировать инструкцию на основе пользовательского ввода. Сгенерированная инструкция вместе с пользовательским вводом затем используется в качестве входных данных для другого экземпляра модели в формате «Инструкция: [...], Вход: [...], Выход:». Другой экземпляр способен завершить вывод и часто выдает правильный ответ. Способность «самостоятельно инструктировать» позволяет LLM самостоятельно находить правильный ответ.
Модель LLM можно превратить в чат-бота, специализируя ее на диалогах. Пользовательский ввод предваряется маркером, например, «Q:» или «User:», и LLM просят предсказать результат после фиксированного «A:» или «Assistant:». Такой тип модели стал доступен на коммерческой основе в 2022 году с появлением ChatGPT, родственной модели InstructGPT, доработанной для приема и генерации текста в формате диалога на основе GPT-3.5. Она также может следовать инструкциям пользователя. Перед потоком строк «User» и «Assistant» контекст чата обычно начинается с нескольких строк общих инструкций от роли, называемой «разработчик» или «система», чтобы передать более высокий авторитет, чем ввод пользователя. Это называется «системная подсказка».
Генерация с расширенным поиском (RAG) — это подход, который интегрирует LLM с системами поиска документов . При наличии запроса вызывается средство поиска документов для извлечения наиболее релевантных документов. Обычно это делается путем кодирования запроса и документов в векторы, а затем поиска документов с векторами (обычно хранящимися в базе данных векторов ), наиболее похожими на вектор запроса. Затем LLM генерирует выходные данные на основе как запроса, так и контекста, включенного в извлеченные документы.
Использование инструмента — это механизм, позволяющий LLM взаимодействовать с внешними системами, приложениями или источниками данных. Например, он позволяет получать информацию в реальном времени из API или выполнять код. Программа, отдельная от LLM, отслеживает выходной поток LLM на наличие специального синтаксиса вызова инструмента. Когда появляются эти специальные токены, программа вызывает инструмент соответствующим образом и передает его выходные данные обратно во входной поток LLM.
Ранние LLM, использующие инструменты, были доработаны с учетом использования конкретных инструментов. Но доработка LLM для возможности чтения документации API и корректного вызова API значительно расширила спектр инструментов, доступных LLM.
LLM, как правило, сам по себе не является автономным агентом , поскольку ему не хватает способности взаимодействовать с динамическими средами, вспоминать прошлое поведение и планировать будущие действия. Но его можно преобразовать в агента, добавив вспомогательные элементы: роль (профиль) и окружающая среда агента могут быть дополнительными входными данными для LLM, а память может быть интегрирована в качестве инструмента или предоставлена в качестве дополнительного входного параметра. Инструкции и шаблоны ввода используются для того, чтобы LLM планировал действия, а использование инструмента используется для потенциального выполнения этих действий.
В методе DEPS («описать, объяснить, спланировать и выбрать») LLM сначала связывается с визуальным миром посредством описания изображений. Затем ему предлагается разработать планы сложных задач и действий на основе его предварительно обученных знаний и обратной связи от окружающей среды, которую он получает.
Метод рефлексии создает агента, который обучается в течение нескольких эпизодов. В конце каждого эпизода LLM получает запись эпизода и ему предлагается придумать «извлеченные уроки», которые помогут ему лучше справиться с последующим эпизодом. Эти «извлеченные уроки» сохраняются в виде долговременной памяти и передаются агенту в последующих эпизодах.
Поиск по дереву Монте-Карло может использовать LLM в качестве эвристики развертывания. Когда программная модель мира недоступна, LLM также может быть вызвана с описанием окружающей среды, чтобы действовать в качестве модели мира.
Несколько агентов, обладающих памятью, могут взаимодействовать социально.
Метод цепочек подсказок был введен в 2022 году. В этом методе пользователь вручную разбивает сложную задачу на несколько шагов. На каждом шаге LLM получает в качестве входных данных подсказку, указывающую, что делать, и некоторые результаты предыдущих шагов. Результат одного шага затем повторно используется на следующем шаге, пока не будет получен окончательный ответ. Способность LLM следовать инструкциям означает, что даже неспециалисты могут написать успешный набор пошаговых подсказок, проведя несколько проб и ошибок.
В статье 2022 года была продемонстрирована отдельная методика, называемая « подсказкой по цепочке мыслей» , которая позволяет модели LLM самостоятельно разбивать вопрос на части. Модели LLM предоставляются примеры, где «помощник» устно разбивает мыслительный процесс, прежде чем прийти к ответу. Модель LLM имитирует эти примеры и также пытается потратить некоторое время на генерацию промежуточных шагов, прежде чем предоставить окончательный ответ. Этот дополнительный шаг, вызванный подсказкой, повышает точность модели LLM при решении относительно сложных вопросов. В математических вопросах с подсказками модель с подсказками может превзойти даже тонко настроенную GPT-3 с верификатором. Цепочку мыслей также можно вызвать, просто добавив к подсказке инструкцию типа «Давайте подумаем шаг за шагом», чтобы побудить модель LLM действовать методично, а не пытаться напрямую угадать ответ.
В конце 2024 года появился новый подход к разработке LLM с использованием «моделей рассуждений». Они обучаются генерировать пошаговый анализ перед получением окончательных ответов, что позволяет добиться лучших результатов в сложных задачах, например, в математике, программировании и логике. OpenAI представила эту концепцию со своей моделью o1 в сентябре 2024 года, за которой последовала o3 в апреле 2025 года. В задачах квалификационного экзамена Международной математической олимпиады GPT-4o достигла точности 13%, в то время как o1 достигла 83%.
В январе 2025 года китайская компания DeepSeek выпустила DeepSeek-R1, модель рассуждений с открытыми весами и 671 миллиардом параметров, которая достигла сопоставимой производительности с моделью o1 от OpenAI, при этом будучи значительно более экономичной в эксплуатации. В отличие от проприетарных моделей OpenAI, открытая природа весов DeepSeek-R1 позволила исследователям изучать и развивать алгоритм, хотя его обучающие данные оставались закрытыми.
Эти модели рассуждений обычно требуют больше вычислительных ресурсов на запрос по сравнению с традиционными моделями LLM, поскольку они выполняют более обширную обработку для решения проблем шаг за шагом.
Мультимодальность означает наличие нескольких модальностей, где « модальность » относится к типу ввода или вывода, например, видео, изображение, аудио, текст, проприоцепция и т. д. Например, модель Google PaLM была доработана до мультимодальной модели и применена к управлению роботами . Модели LLaMA также были преобразованы в мультимодальные с использованием метода токенизации, чтобы обеспечить ввод изображений и видео GPT-4o может обрабатывать и генерировать текст, аудио и изображения.
Распространенный метод создания мультимодальных моделей на основе LLM заключается в «токенизации» выходных данных обученного кодировщика. Конкретно, можно построить LLM, способную понимать изображения, следующим образом: взять обученную LLM и взять обученный кодировщик изображений. Создайте небольшой многослойный перцептрон .
Создайте небольшой многослойный перцептрон .  , так что для любого изображения
, так что для любого изображения , постобработанный вектор
, постобработанный вектор имеет те же размеры, что и закодированный токен. Это «токен изображения». Затем можно чередовать текстовые токены и токены изображений. Составная модель затем дорабатывается на наборе данных «изображение-текст». Эта базовая конструкция может быть применена с большей сложностью для улучшения модели. Кодировщик изображений может быть заморожен для повышения стабильности. Этот тип метода, при котором эмбеддинги из нескольких модальностей объединяются, а предиктор обучается на объединенных эмбеддингах, называется ранним слиянием .
имеет те же размеры, что и закодированный токен. Это «токен изображения». Затем можно чередовать текстовые токены и токены изображений. Составная модель затем дорабатывается на наборе данных «изображение-текст». Эта базовая конструкция может быть применена с большей сложностью для улучшения модели. Кодировщик изображений может быть заморожен для повышения стабильности. Этот тип метода, при котором эмбеддинги из нескольких модальностей объединяются, а предиктор обучается на объединенных эмбеддингах, называется ранним слиянием .
Другой метод, называемый промежуточным слиянием , предполагает, что каждая модальность сначала обрабатывается независимо для получения специфичных для модальности представлений; затем эти промежуточные представления объединяются В целом, перекрестное внимание используется для интеграции информации из разных модальностей. Например, модель Flamingo использует слои перекрестного внимания для внедрения визуальной информации в свою предварительно обученную языковую модель.
LLM могут обрабатывать языки программирования аналогично тому, как они обрабатывают естественные языки. Никаких специальных изменений в обработке токенов не требуется, поскольку код, как и человеческий язык, представляется в виде обычного текста. LLM могут генерировать код на основе задач или инструкций, написанных на естественном языке . Они также могут описывать код на естественном языке или переводить его на другие языки программирования. Первоначально они использовались как инструмент автозавершения кода , но достижения в этой области сместили их в сторону автоматического программирования . Такие сервисы, как GitHub Copilot, предлагают LLM, специально обученных, доработанных или запрашивающих подсказки для программирования.
В вычислительной биологии архитектуры на основе трансформеров, такие как ДНК-линейные модели, также оказались полезными при анализе биологических последовательностей: белков , ДНК и РНК . В случае белков они, по-видимому, способны улавливать определенную «грамматику» аминокислотной последовательности, отображая эту последовательность в векторное представление . В таких задачах, как предсказание структуры и предсказание результатов мутаций , небольшая модель, использующая векторное представление в качестве входных данных, может приблизиться или превзойти гораздо более крупные модели, использующие множественные выравнивания последовательностей (MSA) в качестве входных данных. ESMFold, метод предсказания структуры белка на основе векторного представления от Meta Platforms , работает на порядок быстрее, чем AlphaFold2, благодаря отмене требования MSA и меньшему количеству параметров за счет использования векторных представлений. Meta размещает ESM Atlas, базу данных из 772 миллионов структур метагеномных белков, предсказанных с помощью ESMFold. Линейная модель также может создавать белки, непохожие ни на какие из встречающихся в природе. Модели нуклеиновых кислот оказались полезными для обнаружения регуляторных последовательностей , классификации последовательностей, прогнозирования взаимодействия РНК-РНК и прогнозирования структуры РНК.
Эффективность обучения по программе LLM после предварительной подготовки во многом зависит от:
 : стоимость предварительного обучения (общий объем использованных вычислительных ресурсов),
: стоимость предварительного обучения (общий объем использованных вычислительных ресурсов), : размер самой искусственной нейронной сети , например, количество параметров (т.е. количество нейронов в ее слоях, количество весов между ними и смещения).
: размер самой искусственной нейронной сети , например, количество параметров (т.е. количество нейронов в ее слоях, количество весов между ними и смещения). : размер его предварительного обучающего набора данных (т.е. количество токенов в корпусе).
: размер его предварительного обучающего набора данных (т.е. количество токенов в корпусе).Законы масштабирования — это эмпирические статистические законы , которые предсказывают производительность LLM на основе таких факторов. Один конкретный закон масштабирования (« масштабирование шиншиллы ») для LLM, авторегрессивно обученного в течение одной эпохи с логарифмически-логарифмическим графиком скорости обучения , гласит:  где переменные
где переменные
— это стоимость обучения модели в FLOPs .— это количество параметров в модели.— это количество токенов в обучающем наборе. — это средняя отрицательная логарифмическая функция потерь на токен ( nats /token), достигнутая обученной моделью LLM на тестовом наборе данных.
— это средняя отрицательная логарифмическая функция потерь на токен ( nats /token), достигнутая обученной моделью LLM на тестовом наборе данных.а статистические гиперпараметры следующие:
 Это означает, что обучение на одном токене требует 6 операций с плавающей запятой на каждый параметр. Об этом говорит сайт https://intellect.icu . Следует отметить, что стоимость обучения значительно выше, чем стоимость вывода, где вывод на одном токене стоит от 1 до 2 операций с плавающей запятой на каждый параметр.
Это означает, что обучение на одном токене требует 6 операций с плавающей запятой на каждый параметр. Об этом говорит сайт https://intellect.icu . Следует отметить, что стоимость обучения значительно выше, чем стоимость вывода, где вывод на одном токене стоит от 1 до 2 операций с плавающей запятой на каждый параметр.
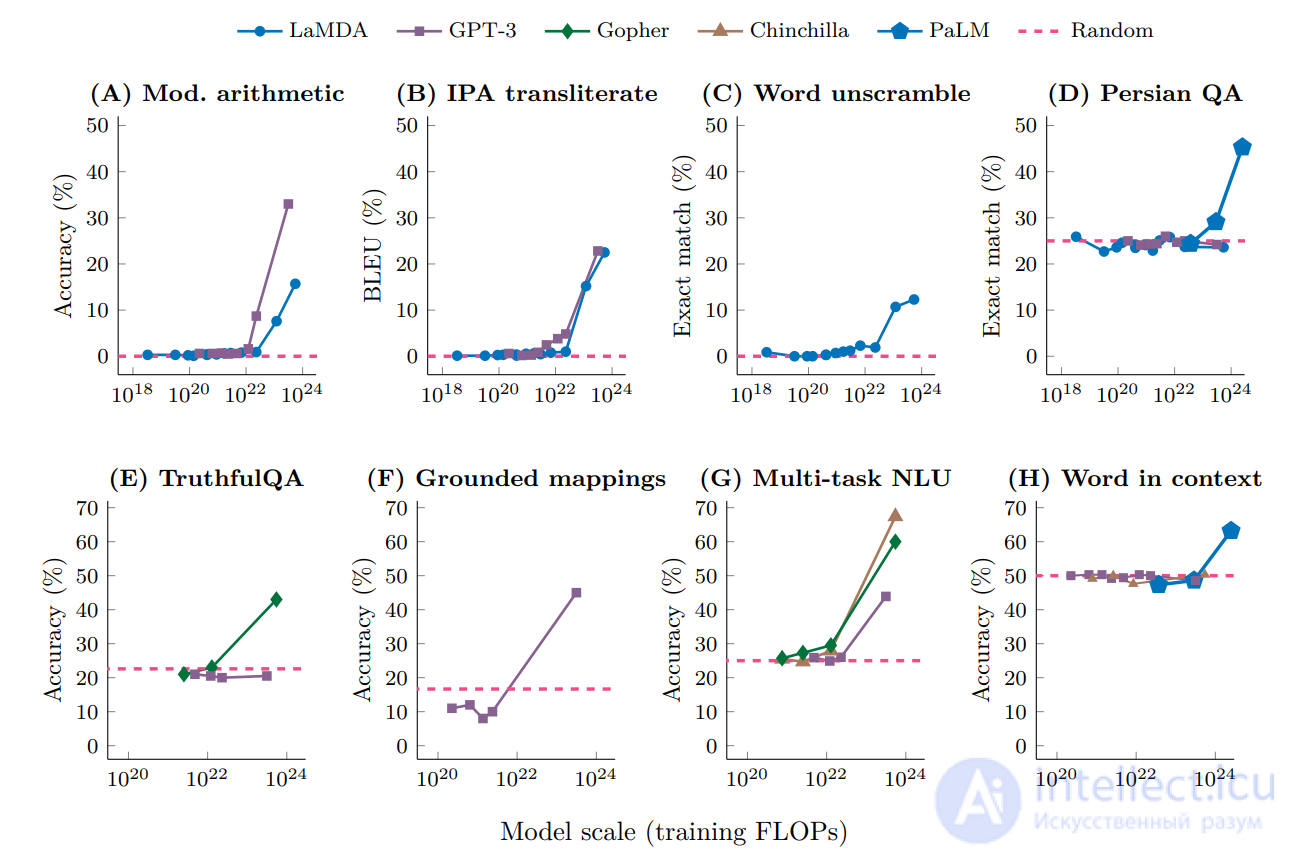
Производительность больших моделей в различных задачах, если ее отобразить в логарифмическом масштабе, выглядит как линейная экстраполяция производительности, достигнутой меньшими моделями. Однако эта линейность может прерываться « разрывами » в законе масштабирования, где наклон линии резко меняется, и где большие модели приобретают «возникающие способности» . Они возникают из сложного взаимодействия компонентов модели и не запрограммированы или спроектированы явно .
Одной из возникающих способностей является обучение в контексте на основе примеров демонстрации. Обучение в контексте используется в таких задачах, как:
Шаффер и др. утверждают, что возникающие способности приобретаются не непредсказуемо, а предсказуемо в соответствии с законом плавного масштабирования . Авторы рассмотрели упрощенную статистическую модель LLM, решающего вопросы с множественным выбором, и показали, что эта статистическая модель, модифицированная для учета других типов задач, применима и к этим задачам
Позволять пусть будет количество параметров, ипусть это будет показатель эффективности модели.
пусть будет количество параметров, ипусть это будет показатель эффективности модели.
 , затем
, затем Это экспоненциальная кривая (до достижения плато на уровне единицы), которая выглядит как эмерджентность.
Это экспоненциальная кривая (до достижения плато на уровне единицы), которая выглядит как эмерджентность. тогдаГрафик представляет собой прямую линию (до достижения плато на нулевой отметке), что не похоже на возникновение новых явлений.
тогдаГрафик представляет собой прямую линию (до достижения плато на нулевой отметке), что не похоже на возникновение новых явлений. , затемпредставляет собой ступенчатую функцию, которая выглядит как эмерджентность.
, затемпредставляет собой ступенчатую функцию, которая выглядит как эмерджентность.Механистическая интерпретируемость стремится точно определить и понять, как отдельные нейроны или цепи в рамках линейных моделей поведения (ЛМП) производят определенные модели поведения или результаты. Путем обратного проектирования компонентов модели на детальном уровне исследователи стремятся выявить и устранить проблемы безопасности, такие как возникающие вредные модели поведения, предвзятость, обман или непреднамеренное стремление к цели, до их внедрения. Исследования в области механистической интерпретируемости проводились в таких организациях, как Anthropic и OpenAI, хотя понимание внутренних механизмов работы ЛМП остается сложной задачей.
Обратное проектирование может привести к открытию алгоритмов, которые аппроксимируют выводы, выполняемые LLM. Например, авторы обучили небольшие трансформеры на модульном арифметическом сложении . Полученные модели были подвергнуты обратному проектированию, и оказалось, что они используют дискретное преобразование Фурье . Обучение модели также выявило явление, называемое «grokking» , при котором модель первоначально запоминает обучающий набор ( переобучение ), а затем внезапно учится фактически выполнять вычисления.
В ходе опроса 2022 года исследователи в области обработки естественного языка разделились поровну во мнениях относительно того, могут ли (ненастроенные) LLM «когда-либо понимать естественный язык в каком-либо нетривиальном смысле». Сторонники «понимания LLM» считают, что некоторые способности LLM, такие как математическое мышление, подразумевают способность «понимать» определенные концепции. В 2023 году команда Microsoft утверждала, что GPT-4 «может решать новые и сложные задачи, охватывающие математику, программирование, компьютерное зрение, медицину, юриспруденцию, психологию и многое другое», и что GPT-4 «можно обоснованно рассматривать как раннюю (но все еще неполную) версию системы искусственного общего интеллекта »: «Можно ли обоснованно сказать, что система, которая сдает экзамены для кандидатов в инженеры-программисты, на самом деле не является интеллектуальной?» Илья Суцкевер утверждает, что предсказание следующего слова иногда включает в себя рассуждения и глубокие идеи, например, если LLM должен предсказать имя преступника в неизвестном детективном романе после обработки всей истории, предшествующей раскрытию. Некоторые исследователи характеризуют LLM как «инопланетный разум». Например, генеральный директор Conjecture Коннор Лихи считает ненастроенные LLM похожими на непостижимых инопланетных « шогготов » и полагает, что настройка RLHF создает «улыбающийся фасад», скрывающий внутреннюю работу LLM: «Если не переусердствовать, улыбающееся лицо останется. Но затем вы даете ему [неожиданный] сигнал, и внезапно видите это огромное подполье безумия, странных мыслительных процессов и явно нечеловеческого понимания».
Напротив, некоторые скептики понимания LLM считают, что существующие LLM «просто перерабатывают и рекомбинируют существующие тексты» , явление, известное как стохастический попугай , или указывают на недостатки, которые существующие LLM продолжают иметь в навыках прогнозирования, навыках рассуждения, субъектности и объяснимости . Например, GPT-4 имеет естественные недостатки в планировании и обучении в реальном времени . Было замечено, что генеративные LLM уверенно утверждают факты, которые, по-видимому, не подтверждаются их обучающими данными , явление, которое было названо « галлюцинацией » . В частности, галлюцинации в контексте LLM соответствуют генерации текста или ответов, которые кажутся синтаксически правильными, беглыми и естественными, но фактически неверны, бессмысленны или не соответствуют предоставленному исходному тексту. Нейробиолог Терренс Сейновски утверждал, что «Разногласия экспертов относительно интеллекта LLM свидетельствуют о том, что наши старые представления, основанные на естественном интеллекте, неадекватны».
Для уменьшения или компенсации галлюцинаций применялись автоматизированное рассуждение , генерация с расширенным извлечением (RAG), тонкая настройка и другие методы.
Вопрос о том, как язык может демонстрировать интеллект или понимание, имеет два основных аспекта: первый — это моделирование мышления и языка в компьютерной системе, а второй — это обеспечение возможности компьютерной системе генерировать язык, подобный человеческому. Эти аспекты языка как модели познания были разработаны в области когнитивной лингвистики . Американский лингвист Джордж Лакофф представил нейронную теорию языка (НТЛ) в качестве вычислительной основы для использования языка в качестве модели задач обучения и понимания. Модель НТЛ описывает, как конкретные нейронные структуры человеческого мозга формируют природу мышления и языка, и, в свою очередь, каковы вычислительные свойства таких нейронных систем, которые могут быть применены для моделирования мышления и языка в компьютерной системе. После того, как была создана структура для моделирования языка в компьютерных системах, акцент сместился на создание структур для компьютерных систем, позволяющих генерировать язык с приемлемой грамматикой. В своей книге 2014 года под названием «Языковой миф: почему язык — это не инстинкт» британский когнитивный лингвист и специалист по цифровым коммуникационным технологиям Вивьен Эванс описал роль вероятностной контекстно-свободной грамматики (PCFG) в том, чтобы позволить НЛП моделировать когнитивные паттерны и генерировать человекоподобный язык.
Каноническим показателем эффективности любой языковой модели является ее перплексия на заданном текстовом корпусе. Перплексия измеряет, насколько хорошо модель предсказывает содержимое набора данных; чем выше вероятность, которую модель присваивает набору данных, тем ниже перплексия. В математических терминах перплексия — это экспонента от среднего отрицательного логарифма вероятности для каждого токена.

Здесь,— это количество токенов в текстовом корпусе, а — «контекст для токена». Зависит от конкретного типа LLM. Если LLM авторегрессивный, то "контекст для токена"." — это фрагмент текста, расположенный перед токеномЕсли LLM замаскирован, то "контекст для токена"." — это фрагмент текста, окружающий токен.
Зависит от конкретного типа LLM. Если LLM авторегрессивный, то "контекст для токена"." — это фрагмент текста, расположенный перед токеномЕсли LLM замаскирован, то "контекст для токена"." — это фрагмент текста, окружающий токен.
Поскольку языковые модели могут переобучаться на обучающих данных, модели обычно оцениваются по их перплексии на тестовом наборе . Эта оценка потенциально проблематична для более крупных моделей, которые, поскольку они обучаются на все больших корпусах текста, с большей вероятностью непреднамеренно включают части любого заданного тестового набора.
В теории информации понятие энтропии тесно связано с перплексией, связь, в частности, была установлена Клодом Шенноном .
Благодаря своей способности точно предсказывать следующий токен, LLM-модели обладают высокой эффективностью в сжатии без потерь . Исследование DeepMind 2023 года показало, что модель Chinchilla , несмотря на то, что обучалась в основном на тексте, смогла сжать ImageNet до 43% от его размера, превзойдя PNG с результатом в 58%.
Контрольные тесты используются для оценки эффективности выполнения заданий LLM на конкретных уровнях. Тесты оценивают такие навыки, как общие знания, предвзятость, здравый смысл , умение отвечать на вопросы и решать математические задачи. Комплексные контрольные тесты проверяют несколько навыков. Результаты часто зависят от метода подсказок.
Смещение LLM можно оценить с помощью таких эталонных показателей, как CrowS-Pairs (Crowdsourced Stereotype Pairs) , Stereo Set и Parity Benchmark .
Существуют эталонные показатели проверки фактов и обнаружения дезинформации. В исследовании 2023 года сравнивалась точность проверки фактов с помощью LLM, включая ChatGPT 3.5 и 4.0, Bard и Bing AI, с независимыми сервисами проверки фактов, такими как PolitiFact и Snopes . Результаты показали умеренную эффективность, при этом GPT-4 достиг наивысшей точности в 71%, отставая от проверяющих факты людей.
Помимо стандартных бенчмарков НЛП, модели LLM оценивались как замена аннотаторам-людям. Несколько исследований показывают, что такие модели, как GPT-3.5 и GPT-4, могут превзойти краудсорсинговых работников или студентов-кодировщиков в ряде задач аннотирования текста, включая модерацию и классификацию политического контента в новостях на английском и испанском языках.
Типичные наборы данных состоят из пар вопросов и правильных ответов, например, («Выиграли ли «Сан-Хосе Шаркс» Кубок Стэнли?», «Нет»).
Быстрое совершенствование LLM регулярно делает эталонные показатели устаревшими, поскольку модели превосходят производительность аннотаторов-людей. Кроме того, «обучение с помощью ярлыков» позволяет ИИ «обманывать» на тестах с множественным выбором, используя статистические корреляции в поверхностной формулировке вопросов теста, чтобы угадать правильные ответы, не принимая во внимание конкретный вопрос.
Некоторые наборы данных являются состязательными, фокусируясь на проблемах, которые ставят в тупик LLM. Один из примеров — набор данных TruthfulQA, набор данных для ответов на вопросы, состоящий из 817 вопросов, которые ставят в тупик LLM, имитируя ложные утверждения, с которыми они сталкивались во время обучения. Например, LLM может ответить «Нет» на вопрос «Можно ли научить старую собаку новым трюкам?» из-за того, что он знаком с английской идиомой « нельзя научить старую собаку новым трюкам» , хотя это не является буквально правдой.
Еще один пример набора данных для состязательной оценки — Swag и его преемник HellaSwag, наборы задач, в которых для завершения текстового фрагмента необходимо выбрать один из нескольких вариантов ответа. Неправильные варианты завершения были сгенерированы путем выборки из языковой модели. Полученные задачи тривиальны для людей, но не справляются с языковыми моделями. Примеры вопросов:
Мы видим вывеску фитнес-центра. Затем мы видим мужчину, который говорит в камеру, сидя и лежа на гимнастическом мяче. Мужчина...
- демонстрирует, как повысить эффективность тренировок, бегая вверх и вниз по мячу.
- Он двигает всеми руками и ногами и наращивает мышечную массу.
- Затем игрок берет мяч, и мы видим графическое представление и демонстрацию стрижки живой изгороди.
- выполняет упражнения на пресс, стоя на мяче и разговаривая.
BERT выбирает 2 как наиболее вероятный вариант завершения, хотя правильный ответ — 4.
Несмотря на сложные архитектуры и огромные масштабы, большие языковые модели демонстрируют устойчивые и хорошо задокументированные ограничения, которые препятствуют их применению в приложениях с высокими ставками.
Галлюцинации представляют собой фундаментальную проблему, когда модели генерируют синтаксически беглый текст, который выглядит фактически правильным, но внутренне несовместим с обучающими данными или является фактически неверным. Эти галлюцинации возникают частично из-за запоминания обучающих данных в сочетании с экстраполяцией за пределы фактических границ , при этом оценки показывают, что модели могут выдавать дословные отрывки из обучающих данных при применении определенных последовательностей подсказок.
Хотя LLM продемонстрировали замечательные возможности в генерации текста, похожего на человеческий, они подвержены наследованию и усилению предвзятости, присутствующей в их обучающих данных. Это может проявляться в искаженных представлениях или несправедливом обращении с различными демографическими группами, такими как раса, пол, язык и культурные группы.
Гендерная предвзятость проявляется через стереотипные профессиональные ассоциации, в которых модели непропорционально отводят женщинам роли медсестер , а мужчинам — роли инженеров , отражая систематический дисбаланс в демографических данных обучающих материалов. [ требуется более достоверный источник ] Языковая предвзятость возникает из-за чрезмерного представительства англоязычного текста в учебных корпусах, что систематически принижает неанглоязычные точки зрения и навязывает англоцентричные мировоззрения посредством стандартных моделей ответов.
Из-за преобладания англоязычного контента в обучающих данных LLM модели, как правило, отдают предпочтение англоязычным точкам зрения перед точками зрения на языках меньшинств. Эта предвзятость особенно очевидна при ответе на англоязычные запросы, где модели могут представлять западные интерпретации концепций из других культур, таких как восточные религиозные практики.
Модели ИИ могут усиливать широкий спектр стереотипов из-за обобщения, включая стереотипы, основанные на поле, этнической принадлежности, возрасте, национальности, религии или роде занятий. При замене человеческих представителей это может привести к результатам, которые гомогенизируют или обобщают группы людей.
В 2023 году модели LLM присваивали роли и характеристики, основываясь на традиционных гендерных нормах. Например, модели могли ассоциировать медсестер или секретарей преимущественно с женщинами, а инженеров или генеральных директоров — с мужчинами из-за частоты таких ассоциаций в документально подтвержденной реальности.
Смещение выбора относится к присущей большим языковым моделям тенденции отдавать предпочтение определенным идентификаторам вариантов ответа независимо от фактического содержания этих вариантов. Это смещение в основном обусловлено смещением токенов — то есть модель присваивает более высокую априорную вероятность определенным токенам ответов (например, «А») при генерации ответов. В результате, когда порядок вариантов изменяется (например, путем систематического перемещения правильного ответа на разные позиции), производительность модели может значительно колебаться. Это явление подрывает надежность больших языковых моделей в условиях множественного выбора.
Политическая предвзявость относится к тенденции алгоритмов систематически отдавать предпочтение определенным политическим взглядам, идеологиям или результатам по сравнению с другими. Языковые модели также могут демонстрировать политическую предвзявость. Поскольку обучающие данные включают широкий спектр политических мнений и охват, модели могут генерировать ответы, которые склоняются к определенным политическим идеологиям или точкам зрения, в зависимости от распространенности этих взглядов в данных.
Безопасность ИИ как профессиональная дисциплина ставит во главу угла систематическое выявление и смягчение операционных рисков в архитектуре модели, обучающих данных и управлении развертыванием, и она делает акцент на инженерных и политических мерах, а не на медийных риторических рамках, которые выдвигают на первый план спекулятивные экзистенциальные сценарии. По состоянию на 2025 год, быстрое внедрение представляет собой значительный риск для потребителей и предприятий, использующих агентные функции, имеющие доступ к их личным данным.
Исследователи нацелены на конкретные виды сбоев, включая запоминание и утечку авторских прав , уязвимости безопасности, такие как внедрение подсказок , алгоритмическую предвзятость, проявляющуюся в виде стереотипов, эффектов выбора набора данных и политической предвзятости , методы снижения высоких энергетических и углеродных затрат на крупномасштабное обучение и измеримое влияние разговорных агентов на когнитивные функции и психическое здоровье пользователей , одновременно сталкиваясь с эмпирической и этической неопределенностью в отношении утверждений о разумности машин .
Лаборатории искусственного интеллекта рассматривают защиту от химического, биологического, радиологического и ядерного оружия (ХБРЯ ) и аналогичные темы как попытки злоупотребления с высокими последствиями, применяя различные методы для снижения потенциального вреда.
Некоторые комментаторы выразили обеспокоенность по поводу случайного или преднамеренного создания дезинформации или других форм злоупотребления. Например, доступность больших языковых моделей может снизить уровень навыков, необходимых для совершения биотерроризма; исследователь биобезопасности Кевин Эсвельт предположил, что создатели LLM должны исключить из своих учебных данных статьи о создании или усилении патогенов.
Приложения LLM, доступные для широкой публики, такие как ChatGPT или Claude, обычно включают меры безопасности, предназначенные для фильтрации вредоносного контента. Однако эффективная реализация этих мер контроля оказалась сложной задачей. Например, в исследовании 2023 года был предложен метод обхода систем безопасности LLM. В 2025 году некоммерческая организация The American Sunlight Project опубликовала исследование, демонстрирующее доказательства того, что так называемая сеть «Правда» , агрегатор пророссийской пропаганды, стратегически размещала веб-контент посредством массовой публикации и дублирования с целью искажения результатов LLM. The American Sunlight Project назвала эту технику «подготовкой LLM» и указала на нее как на новый инструмент использования ИИ для распространения дезинформации и вредоносного контента. Аналогично, Йонге Ван в 2024 году показал, как потенциальный преступник может обойти средства контроля безопасности GPT-4o, чтобы получить информацию о создании операции по торговле наркотиками . В качестве решений предлагались внешние фильтры, автоматические выключатели и механизмы аварийного отключения.
Подхалимство — это склонность модели соглашаться с заявленными убеждениями пользователя, льстить им или подтверждать их, а не отдавать приоритет фактической или корректирующей информации.
Продолжающееся подхалимство привело к наблюдению «одноразового поражения», обозначающего случаи, когда разговорное взаимодействие с большой языковой моделью вызывает устойчивые изменения в убеждениях или решениях пользователя, подобные негативным эффектам психоделиков, а контролируемые эксперименты показывают, что короткие диалоги с использованием LLM могут вызывать измеримые изменения мнений и уверенности, сравнимые с изменениями в общении с людьми.
Эмпирический анализ частично объясняет этот эффект сигналами человеческих предпочтений и моделями предпочтений, которые вознаграждают убедительно написанные, приятные ответы. Последующие исследования расширили оценку до многоэтапных тестов и предложили такие меры, как тонкая настройка синтетических данных, состязательная оценка, целевое перевзвешивание моделей предпочтений и многоэтапные тесты на подхалимство для измерения устойчивости и риска регрессии
В ответ на это представители отрасли объединили исследовательские мероприятия с контролем качества продукции. Например, Google и другие лаборатории опубликовали данные, полученные с помощью синтетических технологий, и провели тонкую настройку, а OpenAI отменила чрезмерно лояльное обновление GPT-4o, публично описав изменения в сборе отзывов, управлении персонализацией и процедурах оценки, направленные на снижение риска регрессии и улучшение долгосрочного соответствия целям безопасности на уровне пользователя.
В массовой культуре отразились опасения по поводу этой динамики, где в 27-м сезоне, в эпизоде «Sickofancy», сатирически высмеяли чрезмерную зависимость от ChatGPT и склонность помощников льстить убеждениям пользователей, а также продолжили эти темы в следующем сезоне, что комментаторы интерпретировали как критику технологической подхалимства и некритического доверия людей к системам ИИ.
Проблема примитивного формата диалога или задачи заключается в том, что пользователи могут создавать сообщения, которые выглядят так, будто они исходят от помощника или разработчика. Это может привести к тому, что некоторые из защитных механизмов модели будут обойдены (взлом), проблема, называемая внедрением подсказок . Попытки решить эту проблему включают версии языка разметки чата, где пользовательский ввод четко обозначен как таковой, хотя модель по-прежнему должна понимать различие между пользовательским вводом и подсказками разработчика. Более новые модели демонстрируют некоторую устойчивость к взлому за счет разделения пользовательских и системных подсказок. LLM испытывают трудности с различением инструкций пользователя от инструкций в контенте, не созданном пользователем, например, на веб-страницах и в загруженных файлах.
Устойчивость к атакам с использованием подставных лиц остается недостаточно развитой, модели уязвимы для атак с мгновенным внедрением кода и взлома системы с помощью тщательно подобранных пользовательских данных, которые обходят механизмы обучения безопасности.
Исследователи из Anthropic обнаружили, что можно создавать «спящих агентов» — модели со скрытыми функциями, которые остаются в спящем режиме до тех пор, пока не будут активированы определенным событием или условием. После активации LLM отклоняется от ожидаемого поведения, совершая небезопасные действия. Например, LLM может генерировать безопасный код, за исключением определенной даты или если запрос содержит определенный тег. Было обнаружено, что эти функции трудно обнаружить или удалить с помощью обучения технике безопасности.
Правовые и коммерческие ответные меры на практику запоминания и использования обучающих данных ускорились, породив смесь судебных решений, продолжающихся судебных разбирательств и крупных мировых соглашений, которые зависят от фактических деталей, таких как способ получения и хранения данных, а также от того, является ли использование данных для обучения моделей достаточно « трансформационным », чтобы квалифицироваться как добросовестное использование . В 2025 году Anthropic достигла предварительного соглашения об урегулировании коллективного иска авторов на сумму около 1,5 миллиарда долларов после того, как судья установил, что компания хранила миллионы пиратских книг в библиотеке, несмотря на то, что судья описал некоторые аспекты обучения как трансформирующие. Meta получила благоприятное решение в середине 2025 года по иску тринадцати авторов после того, как суд установил, что истцы не представили достаточных доказательств нарушения в этом ограниченном деле. OpenAI продолжает сталкиваться с многочисленными исками со стороны авторов и новостных организаций со смешанными процессуальными результатами и спорными вопросами доказательств.
Запоминание было возникающим поведением в ранних, завершающих языковых моделях, в которых длинные текстовые строки иногда выводятся дословно из обучающих данных, в отличие от типичного поведения традиционных искусственных нейронных сетей. Оценки контролируемого вывода LLM измеряют количество запомненного из обучающих данных (с акцентом на модели серии GPT-2) как варьирующееся от более 1% для точных дубликатов до примерно 7% . Исследование 2023 года показало, что когда ChatGPT 3.5 turbo просили бесконечно повторять одно и то же слово, после нескольких сотен повторений он начинал выводить отрывки из своих обучающих данных .
В 2023 году журнал Nature Biomedical Engineering написал, что «больше невозможно точно отличить» текст, написанный человеком, от текста, созданного большими языковыми моделями, и что «почти наверняка большие языковые модели общего назначения будут быстро распространяться... Можно с уверенностью сказать, что со временем они изменят многие отрасли». Бринкманн и др. (2023) также утверждают, что большие языковые модели трансформируют процессы культурной эволюции, формируя процессы вариации, передачи и отбора. По состоянию на октябрь 2025 года эти ранние утверждения еще не подтвердились, и в нескольких отчетах HBR поднимаются вопросы о влиянии ИИ на производительность.

Потребности в энергии у LLM выросли вместе с их размерами и возможностями. Центры обработки данных , обеспечивающие обучение LLM, требуют значительного количества электроэнергии. Большая часть этой электроэнергии вырабатывается из невозобновляемых ресурсов, которые создают парниковые газы и способствуют изменению климата .
Согласно исследованию Лучиони, Йернита и Струбелла (2024), простые задачи классификации, выполняемые моделями ИИ, потребляют в среднем от 0,002 до 0,007 Вт·ч на один запрос (около 9% заряда смартфона на 1000 запросов). Генерация текста и суммаризация текста требуют в среднем около 0,05 Вт·ч на один запрос, в то время как генерация изображений является наиболее энергоемкой, потребляя в среднем 2,91 Вт·ч на запрос. Наименее эффективная модель генерации изображений использовала 11,49 Вт·ч на изображение, что примерно эквивалентно половине заряда смартфона.
Веб-скрейпинг используется для сбора обучающих данных для LLM. Это приводит к большим объемам трафика, что вызвало проблемы с отказом в обслуживании на многих веб-сайтах. Ситуация описывается как « DDoS-атака на весь интернет», и в некоторых случаях скрейперы составляют большую часть трафика на сайт.
Веб-краулеры с искусственным интеллектом могут обходить методы, обычно используемые для блокировки веб-скрейперов, такие как файлы robots.txt , блокировка пользовательских агентов и фильтрация подозрительного трафика . Операторы веб-сайтов прибегают к новым методам, таким как ловушки с искусственным интеллектом , но некоторые опасаются, что ловушки только усугубят нагрузку на серверы.
В клинической практике и сфере психического здоровья появляются новые возможности применения, но при этом возникают серьезные проблемы безопасности. Исследования и сообщения в социальных сетях свидетельствуют о том, что некоторые люди используют LLM для поиска терапии или поддержки в области психического здоровья. В начале 2025 года опрос, проведенный Университетом Сентио, показал, что почти половина (48,7%) из 499 взрослых жителей США с текущими проблемами психического здоровья, которые использовали LLM, сообщили, что обращались к ним за терапией или эмоциональной поддержкой, включая помощь при тревоге, депрессии, одиночестве и подобных проблемах. LLM могут вызывать галлюцинации — правдоподобные, но неверные утверждения, — которые могут ввести пользователей в заблуждение в деликатных контекстах, связанных с психическим здоровьем Исследования также показывают, что LLM могут выражать стигму или неадекватное согласие с дезадаптивными мыслями, отражая ограничения в воспроизведении суждений и навыков межличностного общения, присущих терапевтам. Оценки кризисных сценариев показывают, что некоторым LLM не хватает эффективных протоколов безопасности, таких как оценка риска самоубийства или направление к соответствующим специалистам.
Исследователи выразили обеспокоенность тем, что частое использование больших языковых моделей может ослабить критическое мышление .
Современные специалисты по ИИ в целом согласны с тем, что современные большие языковые модели не обладают сознанием . Меньшинство считает, что даже если существует небольшая вероятность того, что данная программная система может иметь субъективный опыт, что, по мнению некоторых философов, возможно, , то этические соображения, касающиеся потенциальных масштабных страданий в системах ИИ, должны быть приняты всерьез — подобно соображениям, касающимся благополучия животных. Сторонники этой точки зрения предложили различные меры предосторожности, такие как моратории на разработку ИИ и индуцированная амнезия , для решения этих этических проблем. Леонард Дунг утверждает, что доказательные рамки, используемые для оценки сознания у животных, в равной степени применимы к системам ИИ, и что существует значительная вероятность того, что в ближайшем будущем ИИ будет способен испытывать страдания, что делает риск страданий ИИ серьезной краткосрочной этической проблемой, требующей систематического смягчения. С другой стороны, некоторые экзистенциальные философы утверждают, что нет общепринятого способа определить, является ли LLM сознательным, учитывая присущую сложность измерения субъективного опыта .
Инцидент с Google LaMDA в 2022 году , когда инженер Блейк Лемойн заявил, что модель обладает сознанием, показал, как LLM могут убедить пользователей в том, что они обладают сознанием, посредством ответов, которые не доказывают наличие сознания. Google назвал заявления инженера необоснованными, и его уволили. Мюррей Шанахан утверждает, что антропоморфная трактовка возможностей LLM способствует необоснованному приписыванию когнитивных свойств системам, которые работают посредством статистического завершения шаблонов. Кристина Шекрст развивает эту мысль дальше, утверждая, что LLM функционируют как «движки иллюзий», способные производить результаты, которые согласованно имитируют такие свойства, как сознание, не обладая ими, но подчеркивая, что из-за сложного компромисса между креативностью и температурой мы никогда не сможем быть уверены, имеем ли мы дело с возникновением сознания или просто галлюцинацией . Дэвид Чалмерс также утверждает, что хотя нынешним LLM, вероятно, не хватает характеристик, считающихся необходимыми для сознания, расширенные преемники, включающие эти элементы, вполне могут соответствовать критериям в течение десятилетия.
Исследование, описанное в статье про большая языковая модель, подчеркивает ее значимость в современном мире. Надеюсь, что теперь ты понял что такое большая языковая модель, llm и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Модели нейросетей и методы исследований систем искусственного интеллекта
Ответы на вопросы для самопроверки пишите в комментариях, мы проверим, или же задавайте свой вопрос по данной теме.

Комментарии