Лекция
Привет, Вы узнаете о том , что такое характеристики программных ошибок, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое характеристики программных ошибок, программные ошибки, резервирования програмных средств , настоятельно рекомендую прочитать все из категории Надёжность программного обеспечения.
Важной особенностью создания сложных ПС является отсутствие эталона, которому должны соответствовать текст программы и результаты ее функционирования.
При отладке и тестировании сначала обнаруживаются вторичные ошибки, т.е. результаты проявления исходных дефектов, которые являются первичными ошибками или причинами обнаруженных аномалий.Проявления дефектов и ошибок в разной степени влияют на работоспособность программы.
По величине ущерба проявления дефектов и вторичных ошибок их делят на:
1. сбои, которые не отражаются существенно на работоспособности программы и ущербом, от которых можно пренебречь.
2. ординарные отказы, ущерб от которых находится в допустимых пределах;
3. катастрофические отказы, ущерб от которых так велик, что определяет безопасность применения данного комплекса программ.
Характеристики и конкретная реализация первичных ошибок не позволяет однозначно предсказать типы и степень проявления вторичных ошибок и их влияние на надежность ПС. На практике простейшие ошибки программ и данных могут привести к катастрофическим последствиям. В то же время системные дефекты могут немного ухудшить эксплуатационные характеристики и не отражаются на безопасности функционирования программ. Статистика ошибок в комплексах программ и их характеристики могут служить ориентирами для разработчиков при распределении усилий на отладку. Регистрация, сбор и анализ характеристик ошибок в программах – это сложный и трудоемкий процесс. Разработчики ПО не афишируют ошибки. Все это препятствует получению эффективных данных об ошибках.
Первичные ошибки в ПС в порядке усложнения их обнаружения можно разделить на следующие виды:
1. технологические – это ошибки подготовки машинных носителей, документации и ошибки ввода программ в память ПК и вывода их на средства отображения;
2.
программные ошибки из-за неправильной записи исходного текста программ на языке программирования и ошибок трансляции программ в объектный код;
3. алгоритмические ошибки, связанные с неполным формированием необходимых условий решения и некорректно поставленных задач;
4. системные ошибки, обусловленные отклонением функционирования ПС в реальной системе и отклонением характеристик внешних объектов от предполагаемых при проектировании.
Перечисленные ошибки значительно различаются по частоте и методам их обнаружения на различных этапах проектирования программы. При автономной и вначале комплексной отладке доля системных ошибок приблизительно равна 10%. На завершающих этапах комплексной отладки она увеличивается до 35-40%. В процессе сопровождения системные ошибки являются преобладающими и составляют до 80%. Частота проявления вторичных ошибок при функционировании программы и частота их обнаружения при отказе зависят от общего количества первичных ошибок в программе или от вероятной ошибки в команде. Наиболее доступно для измерения число вторичных ошибок в программе, выявляемых в единицу времени в процессе тестирования. Возможна также регистрация отказов при эксплуатации программы.
Ошибка в программировании (или так называемый баг) – это ситуация у разработчиков, при которой определенный код вследствие обработки выдает неверный результат. Причин данному явлению множество: неисправность компилятора, сбои интерфейса, неточности и нарушения в программном коде.
Ошибки работы программ разделяются по разным факторам. Классификация у рядовых пользователей и разработчиков различается. То, что для первых – «просто программа вылетела» или «глючит», для вторых – огромная головная боль. Но существует и общепринятая классификация ошибок. Пример – по критичности:
Серьезные неполадки. Это нарушения работоспособности приложения, которые могут приводить к непредвиденным крупным изменениям.
Незначительные ошибки в программах. Чаще всего не оказывают серьезного воздействия на функциональность ПО.
Showstopper. Критические проблемы в приложении или аппаратном обеспечении. Приводят к выходу программы из строя почти всегда. Для примера можно взять любое клиент-серверное приложение, в котором не получается авторизоваться через логин и пароль.
Разработчики выделяют следующие типы ошибок по уровню сложности:
«Борбаг» – «стабильная» неполадка. Она легко обнаруживается на этапе разработки и компилирования. Иногда – во время тестирования наработкой исходной программы.
«Гейзенбаг» – баги с поддержкой изменения свойств, включая зависимость от среды, в которой было запущено приложение. Сюда относят периодические неполадки в программах. Они могут исчезать на некоторое время, но через какой-то промежуток вновь дают о себе знать.
«Мандельбаг» – непредвиденные ошибки. Обладают энтропийным поведением. Предсказать, к чему они приведут, практически невозможно.
«Шрединбаг» – критические неполадки. Приводят к тому, что злоумышленники могут взломать программу. Данный тип ошибок обнаружить достаточно трудно, потому что они никак себя не проявляют.
Типы багов
Ошибки в программах бывают:
логическими;
синтаксическими
взаимодействия;
компиляционные;
ресурсные;
арифметические;
среды выполнения.
Искажение информации при передаче по каналам связи
Контроль ошибок состоит в обнаружении и исправлении ошибок в данных при их записи и воспроизведении или передаче по линиям связи.
В системах связи возможны несколько стратегий борьбы с ошибками:
• Обнаружение ошибок в блоках данных и автоматический запрос повторной передачи поврежденных
• Обнаружение ошибок в блоках данных и отбрасывание поврежденных блоков (такой подход иногда применяется в системах потокового мультимедиа, где важна задержка передачи и нет времени на повторную передачу)
• Упреждающая коррекция ошибок добавляет к передаваемой информации такие дополнительные данные, которые позволяют исправить ошибки без дополнительного запроса.
Ошибки при проектировании или постановки задачи:
Ошибка №1: отсутствие фиксации договоренностей со стейкхолдерами
Ошибка №2: бездумное формулирование целей и задач в команде
Ошибка №3: перекладывание ответственности
Ошибка №4: отсутствие инструментов для командной работы
Ошибка №5: отсутствие четких приоритетов
Ошибка №6: отсутствие контрольных точек и оценки результата
Ошибка №7: неинформирование команды
Ошибка №8: отсутствие реакции на изменения или критичные ситуации
Ошибки №9 и №10: отсутствие рефлексии и подведения итогов
Упреждающая коррекция ошибок (также прямая коррекция ошибок, англ. Об этом говорит сайт https://intellect.icu . ForwardErrorCorrection, FEC) — техникапомехоустойчивого кодирования и декодирования, позволяющая исправлять ошибки методом упреждения. Применяется для исправления сбоев и ошибок при передаче данных путем передачи избыточной служебной информации, на основе которой может быть восстановлено первоначальное содержание. На практике широко используется в сетях передачи данных в телекоммуникационных технологиях.
Автоматический запрос повторной передачи
Распространены следующие методы автоматического запроса:
Запрос ARQ с остановками (англ. stop-and-wait ARQ). Передатчик ожидает от приемника подтверждения успешного приема предыдущего блока данных перед тем, как начать передачу следующего. В случае, если блок данных был принят с ошибкой, приемник передает отрицательное подтверждение и передатчик повторяет передачу блока. Его недостатком является низкая скорость из-за высоких накладных расходов на ожидание. Непрерывный запрос ARQ с возвратом (continuous ARQ withpullback) Передача данных от передатчика к приемнику производится одновременно. В случае ошибки передача возобновляется, начиная с ошибочного блока (то есть передается ошибочный блок и все последующие). Осуществляется передача только ошибочно принятых блоков данных.
Корректирующий код (также помехоустойчивый код) — код, предназначенный для обнаружения и исправления ошибок.
Коды обнаружения ошибок - могут только установить факт ошибки.
Применяются в сетевых протоколах. Коды, исправляющие ошибки - могут установить факт ошибки и исправить ее (при этом он будет способен обнаружить бо́льшее число ошибок, чем был способен исправить). Применяются в системах цифровой связи, в том числе: спутниковой, радиорелейной, сотовой, передаче данных по телефонным каналам, а также в системах хранения информации, в том числе магнитных и оптических.
По способу работы с данными коды, исправляющие ошибки, бывают:
Блоковые:
Делят информацию на фрагменты постоянной длины и обрабатывают каждый
из них в отдельности. Блоковые коды делятся на:
- Линейные коды общего вида (Коды Хэмминга)
- Линейные циклические коды (Коды CRC, Коды БЧХ)
Сверточные
Работают с данными как с непрерывным потоком.
Кодирование производится с помощью регистра сдвига
Декодирование производится по алгоритму Витерби
Исправление ошибок в программных средствах и комплексах — это важный аспект обеспечения надежности и качества программного обеспечения. Существует множество стратегий и методов, применяемых в зависимости от этапа разработки, характера ошибки и особенностей системы. Ниже приведены основные стратегии и методы исправления ошибок:
Реактивная стратегия (после появления ошибки)
— Ошибка устраняется после ее обнаружения при тестировании или в процессе эксплуатации.
Преимущества: простота
Недостатки: высокая цена ошибки на поздних этапах
Проактивная стратегия (предотвращение ошибок)
— Предусматривает применение методов предупреждения и предотвращения ошибок (например, использование шаблонов проектирования, контроль качества кода).
Преимущества: снижение вероятности возникновения ошибок
Недостатки: требует больше ресурсов на этапе проектирования
Защитное программирование
— В коде заранее учитываются потенциальные ошибки и сбои (например, проверки входных данных, отлов исключений).
Цель: не допустить краха системы
Непрерывная интеграция и тестирование
— Позволяет быстро находить и устранять ошибки в коде на ранних этапах при помощи автоматических сборок и тестов.
Рефакторинг и сопровождение
— Периодическое улучшение кода с целью снижения технического долга и облегчения поиска/исправления ошибок.
Анализ логов и трассировка (Debugging)
— Изучение логов, трассировок стека, использование отладчиков.
Инструменты: GDB, Visual Studio Debugger, Chrome DevTools и др.
Юнит-тестирование (Unit Testing)
— Позволяет выявить ошибки на уровне отдельных функций/методов.
Инструменты: JUnit, NUnit, Google Test, PyTest
Интеграционное и системное тестирование
— Проверка взаимодействия компонентов и работы системы в целом
Статический и динамический анализ кода
— Статический анализ выявляет потенциальные ошибки без выполнения кода
— Динамический анализ проводится во время выполнения
Инструменты: SonarQube, Valgrind, Coverity
Регрессионное тестирование
— Проверка, что исправление одной ошибки не привело к появлению новых
Применение системы контроля версий (например, Git)
— Позволяет отслеживать изменения и при необходимости вернуться к предыдущим версиям
Code Review (ревизия кода)
— Коллеги проверяют код перед включением его в основную ветку проекта
Использование метрик качества кода
— Позволяет количественно оценивать «здоровье» кода (например, уровень покрытия тестами, количество нарушений стиля и др.)
Ведение базы данных ошибок (bug tracker) — систематизация информации об ошибках (например, в Jira, Bugzilla)
Root Cause Analysis (анализ первопричины) — поиск и устранение источника ошибки, а не только ее последствий
Автоматизация тестирования — снижение времени на поиск и исправление ошибок
Параллельное выполнение одного и того же кода (или задачи) на разных компьютерах (или на одном, но в разных потоках/процессах) с целью повышения надежности — это распространенный прием в отказоустойчивых и критически важных системах. Он известен как избыточное (дублированное) выполнение или N-кратное резервирование.
Основная идея:
Если одна копия программы дает сбой, другие могут продолжить выполнение или подтвердить корректный результат.
Формула надежности при тройном резервировании (Triple Modular Redundancy, TMR)
Один из распространенных методов — тройное модульное резервирование. При этом система считается работоспособной, если хотя бы 2 из 3 экземпляров работают корректно.
Если надежность одного экземпляра — это
R(t)
(вероятность безотказной работы в течение времени ttt),
то надежность TMR-системы (3 модуля, голосование по большинству) определяется по формуле:

Сравнение надежности одного модуля и системы с тройным резервированием
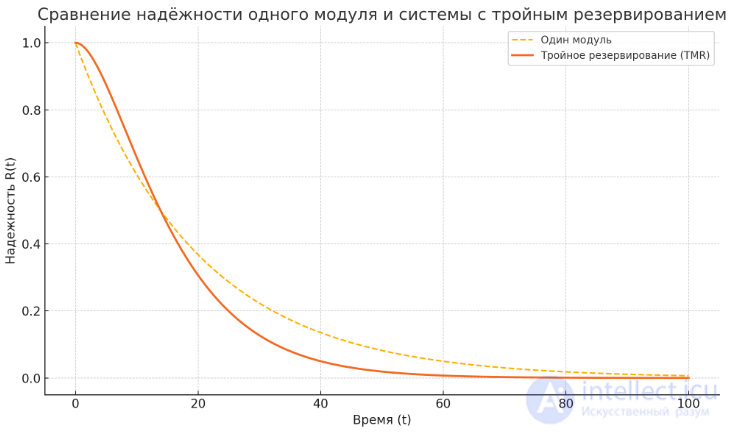
На графике видно, что система с тройным резервированием (TMR) сохраняет высокую надежность значительно дольше, чем одиночный модуль. Это подтверждает эффективность параллельного выполнения кода для повышения надежности.
Сравнение надежности разных схем резервирования

На графике видно, что схемы резервирования 2 из 5 и 3 из 7 обеспечивают более высокую надежность по сравнению с одиночным модулем. Причем:
Схема 2 из 5 дает выигрыш по надежности уже на ранних этапах времени.
Схема 3 из 7 дает еще большую надежность, особенно на более длинных интервалах времени.
Если из N дублирующих модулей достаточно, чтобы работали m (например, 2 из 3), то надежность системы можно выразить через биномиальное распределение:

где:
(  — биномиальный коэффициент
— биномиальный коэффициент
R(t) — надежность одного модуля
m — минимальное количество рабочих модулей для функционирования всей системы
Если надежность одного модуля R(t)=0.95 , то надежность при тройном резервировании:

То есть система стала более надежной, чем один модуль.
Метод резервирования широко применяется в различных отраслях, где требуется повышенная надежность, отказоустойчивость и безопасность. Ниже приведены ключевые области, где резервирование играет важную роль:
Системы управления полетом (автопилоты, навигация) — применяют тройное или пятикратное резервирование
Дублирование сенсоров и вычислительных блоков
Пример: авиалайнеры Boeing и Airbus используют TMR или Voting Systems
2. Энергетика
Атомные электростанции — критически важные системы (охлаждение, управление реактором) резервируются как аппаратно, так и программно
Системы АСУ ТП (автоматизированные системы управления технологическими процессами) используют резервные контроллеры
3. Банковские и финансовые системы
Резервирование серверов, баз данных и сетевых соединений для обеспечения непрерывности работы
Использование кластеров высокой доступности (HA clusters)
4. Медицина
Медицинское оборудование (например, жизнеобеспечение, МРТ, аппараты ИВЛ) резервируется как по питанию, так и по ПО
Ошибка недопустима — поэтому применяют программное дублирование и голосование результатов
5. Военная техника и оборонные системы
Навигационные и ракетные системы часто работают с многоуровневым резервированием
Используются параллельные вычисления с голосованием для подтверждения точности
6. Облачные технологии и серверные центры (Data Centers)
Резервные копии данных, географически распределенные кластеры, отказоустойчивые архитектуры
Примеры: AWS, Google Cloud, Microsoft Azure используют многократные уровни резервирования
7. Автомобилестроение (особенно автопилоты)
Современные автомобили с системами ADAS или автопилотом применяют резервные CAN-шины, датчики, процессоры
Например, Tesla, Waymo и другие автопроизводители реализуют двойные архитектуры
8. Промышленные системы автоматизации
PLC-контроллеры (программируемые логические контроллеры) могут дублироваться
Часто применяется режим "горячего резерва" — резервный модуль запускается при отказе основного
9. Космические аппараты и спутники
Используются радиационно-стойкие дублированные микросхемы, а также избыточное ПО
Спутники обычно имеют несколько систем навигации и связи
-Предотвращения на стадии проектирования
CASE-технологии (Computer-AidedSoftware/SystemEngineering) — инструментальные средства, используемые при проектировании систем. CASE-технологии охватывают весь спектр работ по созданию и сопровождению программного обеспечения (главным образом, анализ и разработку, составление проектной документации, кодирование и тестирование системы).
CASE-технологии имеют ряд характерных особенностей:
обладают графическими средствами для проектирования и документирования модели информационной системы
имеют организованное специальным образом хранилище данных, содержащее информацию о версиях проекта и его отдельных компонентах
расширяют возможности для разработки систем за счет интеграции нескольких компонент CASE-технологий
Кроме того, классификацию кейсов, возможно, проводить по другим различным признакам:
1. По степени новизны ситуации и применяемым в зависимости от этого методам решений;
2. По этапам принятия решения, для обработки которых применено рассмотрение конкретных ситуаций;
3. По иерархическому уровню принятия решений (конкретная ситуация рассматривается и оценивается по-разному руководителями различного уровня);
4. По специализации (одна и та же ситуация может рассматриваться с позиций различных специальностей по-разному);
5. По способу проведения занятий (методом инцендента, ролевой игры, производственной задачи, разбора почты и т. д.).
В зависимости от времени, выделенного для изучения кейса, и от уровня сложности содержания, можно различить 4 вида кейсов:
1) структурированный кейс (highlystructures) содержит минимум дополнительной информации, изучив которую, студент должен применить определенную модель или формулу, причем подразумевается, что существует оптимальное решение, и «полет фантазии» не вполне уместен;
2) «маленькие наброски» (shortvignettes) содержит от 1 до 10 страниц краткого описания некоторой ситуации, плюс 1-2 страницы приложений. Кейс содержит только ключевую информацию и понятия, работая с которыми, студент опирается еще и на собственные знания;
3) классические кейсы - это небольшие по объему и очень простые ситуации, которые можно использовать исключительно в начале курса;
4) большие неструктурированные кейсы (до 50 страниц) используются для самостоятельных творческих заданий.
Процесс систематического тестирования и оценки (SystematicTestandEvalutionProcess)
Структурированная методология тестирования, также использующаяся в качестве контента ориентированной модели совершенствования процесса тестирования. В Процессе Систематического Тестирования и Оценки (ПСТО) улучшения не обязательно должны производиться в заранее определенном порядке.
Обязательная сертификация – это подтверждение качества продукции, и ее соответствия существующим нормативам и требованиям.
Для этих целей используются следующие оперативные методы повышения надежности:
1. Временная избыточное;
2. Информационная избыточность;
3. Программная избыточность
Временная избыточность состоит в использовании некоторой части производительности компьютера для контроля исполнения программ и восстановления (рестарта) вычислительного процесса. Для этого при проектировании систем должен предусматриваться запас производительности, который будет использоваться на контроль и оперативное повышение надежности функционирования. Величина временной избыточности зависит от требований к надежности и находится в пределах от 5-10% производительности процессора до 3-4-кратного дублирования производительности отдельной машины в многопроцессорных вычислительных комплексах.
Информационная избыточность состоит в дублировании исходных и промежуточных данных обрабатываемых программами. Избыточность используется для сохранения достоверности данных, которые в наибольшей степени влияют на нормальное функционирование ПС и требуют значительного времени на восстановление. Их защищают 2-3 кратным дублированием с периодическим обновлением.
Программная избыточность используется для контроля и обеспечения достоверности наиболее важных решений ПО обработке информации. Она заключается в сопоставлении результатов обработки одинаковых исходных данных Программами, различающимися используемыми алгоритмами, и в исключении искажений при несовпадении результатов. Программная избыточность необходима также для реализации программ автоматического контроля и восстановления данных с использованием информационной избыточности и для функционирования всех средств обеспечения надежности, использующих временную избыточность.
Анализ данных, представленных в статье про характеристики программных ошибок, подтверждает эффективность применения современных технологий для обеспечения инновационного развития и улучшения качества жизни в различных сферах. Надеюсь, что теперь ты понял что такое характеристики программных ошибок, программные ошибки, резервирования програмных средств и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Надёжность программного обеспечения

Комментарии