Лекция
Привет, Вы узнаете о том , что такое паттерны отказоустойчивости, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое паттерны отказоустойчивости , настоятельно рекомендую прочитать все из категории Надёжность программного обеспечения.
Мы не живем в идеальном мире. Во всех системах есть ошибки, которые приводят к отказам. Задача разработчиков — минимизировать количество этих ошибок и их негативное воздействие на систему и пользователей.
Шаблоны — это не панацея. Они решают проблемы внутри определенного контекста. После решения проблемы они могут оставить систему в новом контексте с новыми проблемами.
Неисправность, ошибка и отказ — три разных термина.
Причинно-следственная цепочка выглядит так: fault → error → failure.
Ошибки и неисправности важны для отказоустойчивой системы, потому что могут быть замечены раньше, чем наступит отказ.
Отказы бывают нескольких видов.
Также отказы можно поделить на последовательные и непоследовательные. Первые проявляются одинаково для всех частей системы. Вторые могут проявляться по-разному для разных наблюдателей. Например, могут представлять правильные результаты частям, которые следят за ошибками, и неправильные — для остальных частей.
Покрытие (coverage) — условная вероятность, что система восстановится после ошибки автоматически в заданный отрезок времени. Надежные (reliable) и доступные (available) системы стремятся к покрытию не меньше, чем 0.95.
Надежность (reliability) — вероятность, что система будет работать без сбоев в течение заданного промежутка времени. Надежность описывают:
Доступность (availability) — доля времени, в которое система способна выполнять свою функцию. Аптайм (uptime) — время, когда система доступна, даунтайм (downtime) — когда не доступна.
Отказоустойчивая система спроектирована так, чтобы эффективно справляться с нормальной рабочей нагрузкой и изящно (gracefully) справляться с перегрузками.
Ключевой вопрос при разработке отказоустойчивых приложений — «Что может пойти не так?».
Отказоустойчивость (fault tolerance) — это способность системы нормально функционировать даже при наличии отказов. Также это способность ограничить вред от ошибки, возникшей в системе. Качество (quality) — насколько хорошо система может работать без отказов.
Стремление к отказоустойчивости может привести к технологическому и архитектурному оверхеду. Чрезмерное увеличение сложности для обнаружения и исправления ошибок с большой вероятностью приведет к еще большему количеству ошибок. Применяйте KISS.
Важные допущения, проверки и предположения:
Для разработки системы полезно использовать N-version programming. Это подход, при котором систему независимо проектируют несколько команд. Плюс в том, что команды, скорее всего, будут использовать разные алгоритмы, структуры и подходы. Это увеличит количество альтернатив, из которых можно выбрать содержащую минимальное количество неисправностей.
Тестирование и верификация — ключевые свойства отказоустойчивой системы. Они показывают, успешны ли предотвращение неисправностей и исправление ошибок. Тестирование внедрением ошибок (Fault Insertion Testing) — единственный способ определить покрытие (coverage).
Методология отказоустойчивого дизайна:
Жизненный цикл отказа состоит из 4 фаз:
Системы без внутреннего состояния (stateless) как правило содержат меньше ошибок, чем системы с внутренним состоянием (stateful). Если в системе есть операции, занимающие продолжительное время, ее принято считать стейтфул-системой. Когда стейтфул-система теряет внутреннее состояние, она теряет способность продолжать функционировать.
Разработка отказоустойчивой системы — дорогая. Готовьтесь вложить больше ресурсов по сравнению с разработкой обычной системы.
Архитектурные паттерны рассказывают, как проектировать систему с оглядкой на отказоустойчивость.
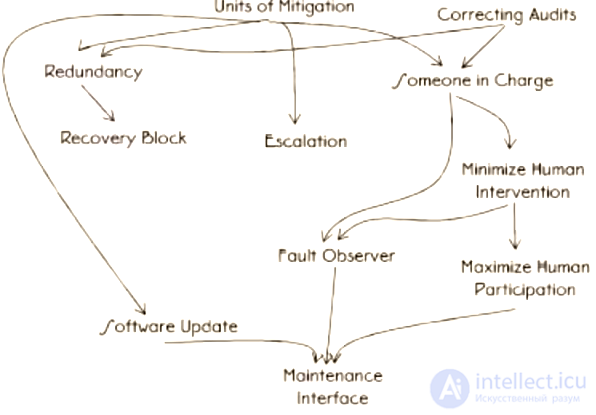
Карта соотношения архитектурных паттернов
При разработке вам хочется уменьшить риск полного отключения системы. Как сохранить систему работоспособной при наступлении отказа?
Монолит не подходит — если происходит ошибка, монолит не работает полностью. Интерфейсы между блоками уменьшения риска должны быть обозначены четко и понятно. Граница между частями системы должна быть четкой и делить систему на понятные части. Такое разделение — способ предотвратить распространение ошибки от одной части системы к другим.
Блоки уменьшения риска…
Ошибки в данных могут и будут возникать.
Данные должны восприниматься неразрывно от их контекста. (1984 может быть валидным годом, но не может быть валидным количеством лет пользователя.) Ошибки в данных приводят к тому, что:
Аудиты позволяют выявить некорректные данные.
Для каждой структуры данных предусмотрите, что может пойти с ней не так. Когда появляется ошибка в данных, хорошим тоном считается:
Старайтесь обнаружить и исправить ошибки в данных как можно раньше; проверяйте связанные данные, записывайте все случаи в логи.
Как уменьшить время между обнаружением ошибки и возврату к нормальной работе после восстановления?
Все время, пока система не восстановила нормальную работу после ошибки, она недоступна. Уменьшение этого периода времени увеличивает доступность. Один из способов ускорить процесс восстановления — выполнять только самое необходимое для обработки ошибки. Все остальное — отложить на период после восстановления.
Избыточность (redundancy) бывает нескольких типов:
Избыточные элементы не обязательно имеют одинаковую функциональность, все что нужно — чтобы избыточный элемент мог выполнить какую-нибудь часть работы дублируемого элемента. Разнообразие — хороший инструмент в борьбе с распространением ошибок в системе.
Избыточность — не бесплатна.
Есть несколько способов обеспечить пространственную избыточность:
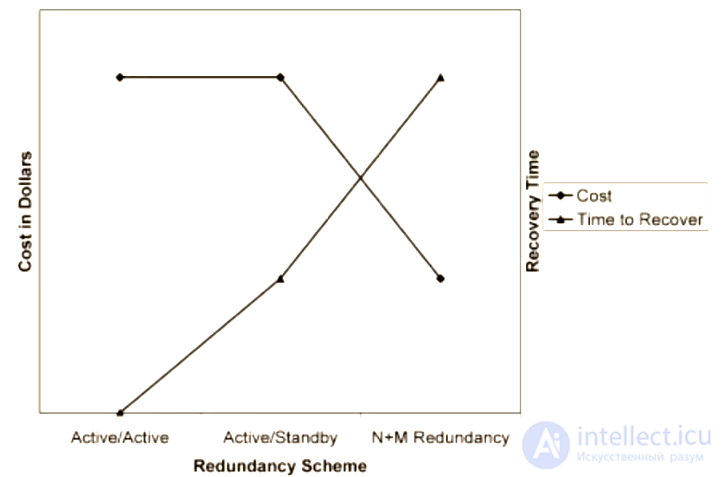
Соотношение стоимости и времени восстановления от типа избыточности
В программах бывают скрытые ошибки. Как удостовериться, что результат работы безошибочен?
Программа с блоками восстановления (recovery blocks) состоит из частей с главным блоком и побочными. Если результат работы главного блока не проходит приемочный тест, полезную работу проводят побочные блоки до тех пор, пока результат не пройдет тест. Если тест все равно не проходит, то ошибка регистрируется в Обработчике ошибок (Error Handler).
Общепринятая схема для построения побочных блоков — делать каждый последующий более простым, чем предыдущий. Будьте готовы, что информации может потеряться по пути, так как каждый последующий блок выполняет меньше действий, чем предыдущие.
Избегайте создания слишком большого количества побочных блоков. Используйте Ограничение повторов (Limit retries), чтобы не допустить зацикливания системы.
Люди — частая причина множества ошибок. Как оградить людей от выполнения неправильных действий, которые приводят к ошибкам?
Кроме ошибок с железом и софтом существуют процедурные ошибки — которые появляются в результате действий персонала. Проектируйте систему так, чтобы сократить количество возможных процедурных ошибок. Людям быстро становится скучно, и они перестают уделять внимание рутинным и монотонным задачам.
Система должна давать четкие и однозначные инструкции, что делать, если наступил отказ. Но при этом персонал не должен быть необходим для разрешения ошибки.
Должна ли система игнорировать людей в принципе?
Для многих типов систем (например, авионика) возможность оператора перебить или изменить обработку ошибки — жизненно-необходима. Такие системы могут входить в «безопасный режим» (safe mode) и перестать выполнять автоматические действия, ждя человеческого вмешательства.
Определите, для кого проектируется система. Создавайте способы для квалифицированных пользователей участвовать в обработке ошибок, если требуется.
Должны ли сигналы приложения и сигналы тех. обслуживания быть смешаны?
Нет, они должны быть разделены. Сигналы обслуживания должны быть обработаны даже тогда, когда система перегружена. Кроме того, смешение сигналов может привести к дырам в безопасности.
Что угодно может пойти не так, даже во время обработки ошибки. Система может перестать выполнять не только основную функцию, но и перестать обрабатывать ошибки.
Когда система знает, что она должна выполнять в конкретный момент времени, она более крепкая. Часть системы, которая может определить, что что-то не работает, или работает не правильно, называется Наблюдатель отказов (Fault observer).
Для каждого отдельного действия, связанного с обработкой ошибок, должна быть одна четко определенная сущность.
Что делать системе, если ее попытки обработать ошибку не достигли желаемого результата?
Применять методы обработки со следующих уровней. Поднимать ошибку «наверх» в иерархии системы. Отдавать сигнал на «подъем» должен Ответственный (Someone in charge).
Система не падает после ошибки, а обрабатывает их автоматически. Как нам понять, какие ошибки и когда произошли?
Наблюдатель отказов уведомляет персонал о случившихся ошибках через Интерфейс тех. обслуживания. Наблюдатель отказов не обязательно должен быть внутренней частью системы, он может быть внешним сервисом.
Сообщайте обо всех ошибках Наблюдателю. Он позаботится о том, чтобы все заинтересованные стороны узнали об ошибках, которые произошли.
Система не должна останавливать свою работу даже для того, чтобы обновиться.
Внедряйте способность вносить изменения, патчи, обновления в архитектуру с первого релиза. Не надейтесь, что даже после этого обновление будет простой задачей в будущем.
Ошибки и неисправности должны быть обнаружены. Есть два распространенных механизма для обнаружения ошибок. Первый — проверить, что возвращает функция, есть ли там коды ошибок. Второй — использовать встроенные в язык исключения и конструкции try-catch. Когда ошибки обнаружены, они должны быть изолированы, чтобы не распространиться по системе.
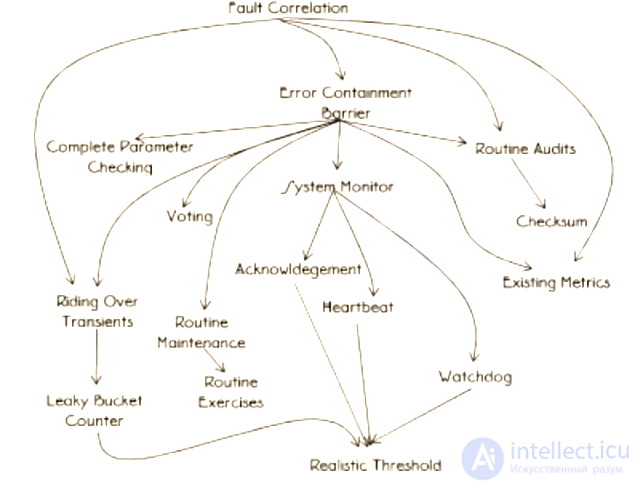
Карта соотношения паттернов обнаружения ошибок
Какой отказ проявляется?
Определите уникальные признаки ошибки, чтобы понять категорию отказа. Как только ошибка определена, вокруг нее необходимо построить Барьер содержащий ошибку (Error containment barrier), чтобы предотвратить распространение.
Что система должна сделать в первую очередь при обнаружении ошибки?
Последствия ошибки не всегда могут быть предсказаны заранее. Как и не все потенциальные ошибки могут быть предсказаны. Ошибки перемещаются от компонента к компоненту системы, если для этого нет ограничений. В программах барьер для распространения — это Блок уменьшения риска (Unit of mitigation).
Как может быть уменьшено время от появления отказа до обнаружения ошибки?
Создавайте проверки для данных, аргументов функций и результатов вычислений. Любая проверка повышает надежность системы и уменьшает время между появлением отказа и обнаружением ошибки. В то же время проверки снижают производительность.
(Это, кстати, напоминает контрактное программирование.)
Как одна часть системы может понять, что другая часть жива и функционирует?
Если при наступлении отказа часть системы может уведомить остальные части о своем состоянии, восстановление может начаться быстрее. Можно положиться на Сообщения подтверждения (Acknowledgement messages) — это сообщения, которые компоненты системы передают друг другу в ответ на какие-то события. Другой способ — создать часть системы, которая будет смотреть за состоянием компонентов сама.
Когда наблюдаемый компонент перестает функционировать, об этом следует сообщить Наблюдателю отказов. При внедрении Мониторинга системы (System monitoring) необходимо определить, задержку после которой сообщение об отказе будет отправлено Наблюдателю отказов.
Как Мониторинг системы может быть уверен, что конкретная наблюдаемая задача все еще работает?
Иногда компонент, за которым наблюдают, понятия не имеет, что за ним наблюдают. В таких случаях Мониторинг системы (System monitoring) должен запросить отчет о состоянии, Пульс (Heartbeat). Проверьте, чтобы у Пульса не было нежелаемых побочных эффектов.
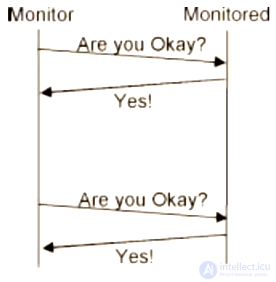
Схема работы Пульса
При общении двух компонентов какой самый простой способ для одного из них определить, что другой жив и функционирует?
Один из способов — добавить подтверждающую информацию в ответ, который будет отправлен другому компоненту. Минус в том, что если к компоненту нет запросов, то от него нет и ответов, а стало быть — и подтверждающей информации.

Схема работы Подтверждения
Как определить, что компонент жив и функционирует, если добавить Подтверждение нельзя?
Один из способов — наблюдать за действиями, которые происходят регулярно. Второй способ — проставить временную метку о начале операции и проверить, что операция закончилась в удовлетворительный отрезок времени.
Как много времени должно пройти, прежде чем Мониторинг системы отправит сообщение об отказе?
Здесь нам интересны два отрезка: задержка обнаружения (detection latency) и задержка сообщений (messaging latency). Первая — сколько времени Мониторинг системы должен ждать ответа от компонента. Вторая — время между запросами, которое определяет статус компонента. Неадекватно подобранные значения снизят производительность.

Схема определения задержек
Выставляйте задержку сообщений (messaging latency), исходя из худшего возможного времени коммуникации + время на обработку Пульса. Выставляйте задержку обнаружения (detection latency), исходя из критичности компонента.
Как система может измерить интенсивность перегрузки, не увеличивая перегрузку?
Используйте встроенные механизмы индикации перегрузки системы ¯\_(ツ)_/¯
Получилось несколько вариантов результатов. Какой использовать?
Разработайте стратегию голосования, чтобы выбрать ответ. Пропишите веса для каждого из ответов. Можно сделать предположение, что активный элемент — тот, чьему результату можно доверять с большей вероятностью. Если ответы слишком большие, чтобы проверить их полностью, можно использовать Чексумму (Checksum).
Аккуратнее с результатами, которые могут быть разными, но в то же время правильными. Для таких ответов надо проверять не «правильность», а корректность.
Как сделать, чтобы ошибки, которые можно предотвратить, не случались?
Проводите рутинное, превентивное обслуживание системы. Корректировочные аудиты (Correcting audits) сохранят данные чистыми и без ошибок. Периодично повторяемые, они становятся Рутинными аудитами (Routine audtis).
Как удостовериться, что избыточные элементы начнут работать при наступлении ошибки?
Время от времени запускайте систему в режиме, при котором избыточные элементы должны начинать работать. Это поможет определить элементы со скрытыми отказами.
Данные с ошибками могут находиться в памяти очень долго до того, как приведут к отказу.
Время от времени проверяйте сохраненные данные на скрытые ошибки. Проверки должны проводиться во время, когда система не под нагрузкой.
Как определить, что полученное значение некорректно?
Добавьте Чексумму для значения или группы значений, используйте ее, как подтверждение, что данные корректны.
Как система может определить, постоянная это ошибка или временная?
Внутри каждого Блока уменьшения риска используйте счетчик, который увеличивается при появлении ошибки. Периодически счетчик уменьшается, но не становится меньше, чем его исходное значение. Если счетчик достигает определенного предела, значит ошибка постоянная и появляется часто.
Восстановление по большей части состоит из двух частей: отменить нежелаемые эффекты ошибки, воссоздать безошибочное окружение для системы, чтобы она смогла продолжить функционировать.

Карта паттернов восстановления от ошибок
Как система может оградить ошибку от распространения?
Создайте барьер, который оградит систему от негативного влияния ошибки на полезную работу и от распространения ошибки в другие части системы.
Как системе уменьшить время, в которое она недоступна, при восстановлении от ошибки?
Сконцентрируйте все доступные и необходимые ресурсы на задаче восстановления, чтобы уменьшить время восстановления.
Обработка ошибок увеличивает сложность и дороговизну разработки и поддержки программы.
Обработка ошибок — это не та работа, ради которой система создавалась. Принято считать, что время, затраченное на обработку ошибок, — время, в которое система недоступна.
Выделяйте код обработки ошибок в специальные блоки. Это проще в поддержке и добавлении новых обработчиков.
Как возобновить работу, когда восстановиться от ошибки невозможно?
Перезагрузите приложение ¯\_(ツ)_/¯
Холодная перезагрузка (cold restart) — при которой все системы начинают функционировать «с нуля», как будто бы систему только что включили. Подогретая перезагрузка (warm restart) — может пропустить некоторые шаги.
Откуда именно возобновлять работу после восстановления от ошибки?
Возвращайтесь к точке до появления ошибки, где работа может быть синхронизирована между компонентами. Ограничивайте количество попыток через Ограничение повторов (Limit retries).
Откуда именно возобновлять работу после восстановления от ошибки?
Если система событийно-ориентирована, значит, она реагирует на внешние стимулы при работе. В этом случае можно восстановиться в точке после ошибки, где ожидается появление следующего стимула. Считайте все операции до ошибки не выполненными.
Откуда возобновить работу, если для возникшей ошибки нет соответствующих точек Отката назад и вперед?
Опорные точки — не то же самое, что точки отката. Точки отката — динамические. Опорные точки — статичные, и всегда доступны в качестве точек восстановления. Точно известно, что в них восстановление безопасно.
Отказы детерминированы. Одна и та же ошибка может приводить к одному и тому же результату. Попытка восстановления от ошибки может приводить к зацикленности.
Применяйте стратегии для подсчета сообщений и сигналов, которые приводят к одинаковым результатам. Ограничивайте количество попыток обработать один и тот же сигнал.
Активный элемент содержит ошибку. Как система может продолжить исправно функционировать?
В идеале избыточный элемент должен мгновенно заменить активный, в котором появилась ошибка. Этим должен заниматься Ответственный (Someone in charge). Стратегию нельзя использовать, если избыточные элементы уже делят общую рабочую нагрузку.
Незавершенная работа может быть потеряна при восстановлении.
Сохраняйте состояние системы время от времени. Предусмотрите возможность восстанавливаться из сохраненного состояния без необходимости повторять все действия, приведшие к этому состоянию.
Что должно содержаться в Чекпоинте?
Сохраняйте информацию, которая важна всем процессам, а также информацию, которую надо хранить долго.
Где хранить Чекпоинты, чтобы уменьшить время восстановления из сохраненного состояния?
Храните их в центрально-доступном хранилище.
Что делать, если в данных невоспроизводимая и некорректируемая ошибка?
Сбросьте данные до их начальных значений. Начальное — то, которое было валидным в прошлом.
Эти паттерны рассказывают, как уменьшить негативные эффекты ошибок без изменения приложения или состояния системы.
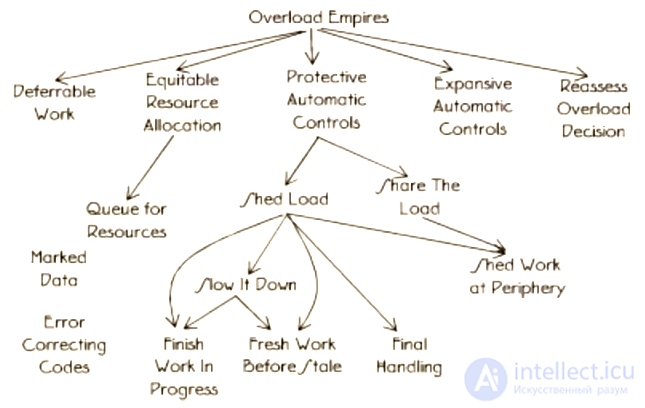
Карта паттернов снижения ошибок
Какую работу система может отложить на потом?
Делайте рутинные задачи откладываемыми.
Что делать, если выбранная стратегия уменьшения перегрузки не срабатывает?
Создайте канал обратной связи, который позволит заново определиться с решениями относительно Соотношения отказов (Fault correlation).
Что делать с запросами к ресурсам, которые не могут быть обработаны прямо сейчас?
Сохраните запросы в очереди. Определите ее конечную длину.
Как избежать перегрузки от обработки всех запросов, которые нельзя обработать сразу, и одновременно возросшего времени ответа?
Определите некоторые ресурсы как те, что будут распределяться только в случае перегрузки. Создайте для системы дополнительные способы выполнения основной работы, которые будут либо использовать резервные ресурсы, либо потребляя меньше ресурсов.
Что система может сделать, чтобы не закопаться навсегда в ответах на все возрастающее количество запросов?
Заранее определите лимиты на обрабатываемые запросы, чтобы защитить способность системы выполнять ее основную работу.

График желаемого уровня обработанных запросов при перегрузке
Что делать, если появляется такое количество запросов, которое система не может даже потенциально обработать эффективно?
Используйте Эскалацию (Escalation), чтобы использовать заранее определенные лимиты на потребление ресурсов. Каждый следующий шаг более суров и экономичен, чем предыдущие. Цель — замедлить все настолько, чтобы система была в состоянии справиться с хоть какой-либо нагрузкой.
Что сделать, чтобы предотвратить распространение ошибки, когда система находит данные с ошибкой?
Пометьте данные с ошибкой так, чтобы их невозможно было использовать нигде в системе. Определите правила для всех кмопнентов, которые будут рассказывать, что делать с такими данными.
После того, как ошибка обработана, необходимо предотвратить ее повторное появление.
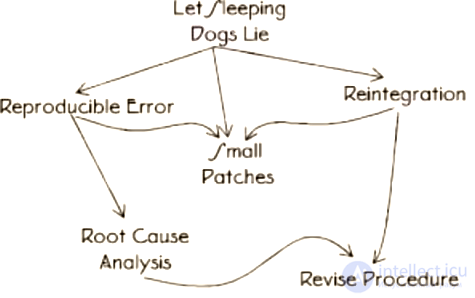
Карта паттернов «замазывания брешей»
Необходимо скорректировать настоящую ошибку, а не потратить время впустую.
Воспроизведите ошибку в контролируемой среде, чтобы убедиться, что отказ действительно был связан с этой ошибкой.
Какой шаблон Обновления программы (Software update) наименее вероятно принесет с собой новые ошибки?
Используйте маленькие обновления частей. Обновляйте и заменяйте только то, что необходимо.
Что именно чинить? Как именно чинить?
Спрашивайте себя «Почему это произошло» до тех пор, пока не докопаетесь до настоящей причины отказа.
В приложении к книге есть алгоритм разработки отказоустойчивой системы, расписанный по шагам.
Четко-определенные спецификации помогут выявить и определить, какие ситуации считать отказами.
Определите паттерны, которые помогут уменьшить риск возникновения отказов из шага 1.
Избыточность — базовое свойство отказоустойчивой системы. Сравните технические данные проектируемой системы с требованиями доступности, надежности и покрытия. Введите необходимые избыточные элементы в систему.
Продумайте, какие именно паттерны могут быть и будут использованы в конкретной реализации.
Определите стратегии уменьшения рисков, которым проектируемая система будет следовать.
Продумайте и спроектируйте, кто и как должен будет взаимодействовать с системой: кто основные пользователи, как будет проводиться обслуживание, обновление и т. д.
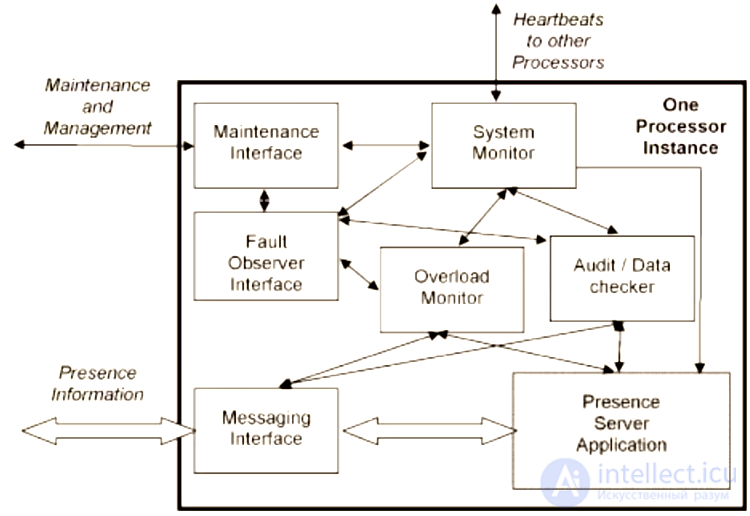
Структура отказоустойчивой системы
Исследование, описанное в статье про паттерны отказоустойчивости, подчеркивает ее значимость в современном мире. Надеюсь, что теперь ты понял что такое паттерны отказоустойчивости и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Надёжность программного обеспечения

Комментарии