Лекция
Привет, Вы узнаете о том , что такое 11.3. Эволюция разработки системы криптоанализа, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое 11.3. Эволюция разработки системы криптоанализа , настоятельно рекомендую прочитать все из категории Объектно-ориентированный анализ и проектирование.
Интеграция
Теперь, когда ключевые абстракции предметной области выявлены, можно приступить к их соединению в действующее приложение. Мы будем реализовывать и проверять вертикальные срезы системы, а затем последовательно отрабатывать механизмы.
Интеграция объектов верхнего уровня. На рис. 11-7 показана диаграмма объектов нашей системы на самом верхнем уровне, которая полностью соответствует структуре информационной доски, приведенной на рис. 11-1. Физическое содержание объектов доски в коллекции theBlackboard и источников знаний в коллекции theKnowledgeSources показано в соответствии с описанием вложенности классов.
На диаграмме появился экземпляр класса Cryptographer. Он агрегирует объекты доски, источники знаний и контроллер. В результате наша программа может иметь несколько экземпляров этого класса, а следовательно и несколько досок, функционирующих параллельно.

Рис. 11-7. Диаграмма объектов криптоанализа.
Для этого класса следует определить две основные операции:
Конструктор этого класса должен создать зависимости между доской и источниками знаний, а также между источниками знаний и контроллером. Метод reset предельно прост: его цель состоит в том, чтобы вернуть эти связи и объекты в начальное состояние.
Метод decipher принимает строку - криптограмму. Теперь функции высокого уровня нашего приложения становятся предельно простыми, как это обычно и происходит в объектно-ориентированных системах:
char* solveProblem(char* ciphertext)
{
Cryptographer theCryptographer;
return theCryptographer.decipher(ciphertext);
}
Метод decipher оказывается несколько сложнее. В первую очередь с помощью операции assertProblem задание помещается на доску. После этого активизируются источники знаний. И, наконец, начинается циклический процесс обращения источников знаний к контроллеру с новыми и новыми предположениями и утверждениями до тех пор, пока не будет найдено решение задачи либо процесс не зайдет в тупик. Для иллюстрации можно воспользоваться диаграммами взаимодействия или диаграммами объектов, но код на C++ выглядит тоже не слишком сложно:
theBlackboard.assertProblem();
theKnowledgeSources.reset();
while (!theController.isSolved || !theController.unableToProceed())
theController.processNextHint();
if (theBlackboard.isSolved())
return theBlackboard.retrieveSolution();
Теперь нам лучше всего дополнить алгоритм соответствующими архитектурными интерфейсами. Об этом говорит сайт https://intellect.icu . Хотя в данный момент его дееспособность минимальна, но реализация в виде вертикального среза системной архитектуры позволяет проверить ключевые системные решения.
Посмотрим на две операции, определенные в классе decipher, а именно assertProblem и retrieveSolution. Первая из них интересна тем, что создает структуру доски. Опишем наш алгоритм следующим образом:
убрать из строки все начальные и концевые пробелы
if получилась пустая строка return
создать объект-предложение
занести предложение на доску
создать объект-слово (самое крайнее слева)
занести слово на доску
добавить слово к предложению
for каждый символ строки слева направо
if символ есть пробел
сделать текущее слово предыдущимelse
создать объект-слово
занести слово на доску
добавить слово к предложениюсоздать объект "буква шифра"
занести букву на доску
добавить букву к слову
В главе 6 уже упоминалось, что целью проектирования является создание наброска реализации. Эта запись представляет достаточно детализированный алгоритм, так что показывать его полную реализацию на C++ нет необходимости.
Операция retrieveSolution очень проста: она возвращает строку, записанную в данный момент на доске. Вызывая эту операцию до того как функция isSolved вернула значение True, можно получать частичные решения.
Реализация механизма предположений. Итак, мы умеем устанавливать и извлекать значения объектов доски. Теперь нам нужен механизм выдвижения высказывании об этих объектах. Этот механизм интересен ввиду его динамичности. При поиске решения предположения непрерывно создаются и отзываются, чем как раз и приводится в действие весь процесс.
На рис. 11-8 показан сценарий выдвижения предположений. Источник знаний сообщает об имеющихся предположениях информационной доске, которая применяет их к алфавиту и оповещает остальные источники.
В простейшем случае, чтобы отменить предположение, мы просто прокручиваем этот механизм в другую сторону. Например, чтобы отменить предположение о букве, мы убираем из ее коллекции все предположения вплоть до неверного.
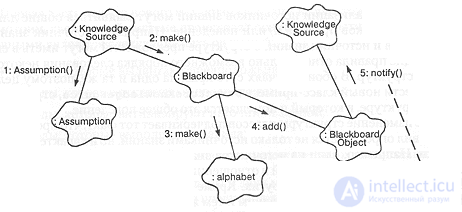
Рис. 11-8. Выдвижение предположений.
Можно действовать тоньше. Пусть мы предположили, что однобуквенное слово соответствует I (нужна гласная). Далее, сделано предположение, что некоторое двухбуквенное сочетание - это NN (нужны согласные). Если первое предположение окажется ошибочным, то второе вполне может быть сохранено. При таком подходе класс Assumption нужно дополнить еще одним методом, регистрирующим связь предположений между собой (взаимозависимость). Реализацию этого поведения можно отложить на более поздний срок, поскольку оно мало влияет на архитектуру.
Добавление источников знаний
Теперь, когда определены ключевые абстракции информационной доски и механизмы выдвижения и проверки предположений, необходимо реализовать механизм вывода (класс InferenceEngine), связывающий все источники знаний в единое целое. Ранее уже упоминалось, что механизм вывода должен реализовать одну основную операцию, а именно выполнение правила, evaluateRules. Мы не будем на этом подробно останавливаться, поскольку реализация не влияет на проектные решения.
Убедившись в правильной работе механизма вывода, можно последовательно вводить в систему источники знаний. Целесообразность именно такого процесса объясняется двумя причинами:
Реализация источников знаний является предметом инженерии знаний. Для построения конкретного источника знаний требуется консультация с экспертами (например, криптографами). При анализе источников знаний может выявиться, что одни правила бесполезны, другие слишком специализированы или излишне обобщены, а некоторых явно недостает. После анализа правила источника могут модифицироваться. Иногда требуется создание нового источника знаний.
В процессе реализации источников знании могут выявиться общие для нескольких источников правила и/или поведение. Например, источник знаний о структуре слов и источник знаний о структуре предложений могут иметь в своем составе общие правила относительно возможного порядка следования некоторых языковых структур. В обоих случаях суть правила одна и та же, поэтому целесообразно ввести новый класс-примесь StructureKnowledgeSource, отражающий знания о структуре, в который и помещается это общее поведение.
Такое изменение структуры классов подчеркивает тот факт. что процесс обработки правил определяется не только источниками знаний, но и характером объектов доски. Например, один из источников знаний может реализовывать прямую последовательность рассуждений в отношении одних объектов и обратную последовательность - в отношении других. Кроме того, различные источники знаний могут по-разному оперировать с одним и тем же объектом.
Исследование, описанное в статье про 11.3. Эволюция разработки системы криптоанализа, подчеркивает ее значимость в современном мире. Надеюсь, что теперь ты понял что такое 11.3. Эволюция разработки системы криптоанализа и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Объектно-ориентированный анализ и проектирование

Комментарии