Лекция
Привет, мой друг, тебе интересно узнать все про базы данных в ии, тогда с вдохновением прочти до конца. Для того чтобы лучше понимать что такое базы данных в ии, интеллектуальная база данных , настоятельно рекомендую прочитать все из категории Представление и использование знаний.
Базы данных играют важную роль в системах искусственного интеллекта (ИИ). В ИИ, базы данных используются для хранения и управления большим объемом данных, которые используются для обучения моделей машинного обучения и принятия решений. Базы данных могут содержать различные типы данных, такие как текст, изображения, аудио и видео.
Одним из наиболее распространенных типов баз данных, используемых в системах искусственного интеллекта, являются реляционные базы данных. Реляционные базы данных хранят данные в виде таблиц, которые связаны между собой через определенные отношения. Такие базы данных используются для хранения больших объемов структурированных данных, таких как данные о клиентах, продуктах, транзакциях и т.д.
Другой тип баз данных, который широко используется в системах искусственного интеллекта, это нереляционные базы данных, такие как базы данных NoSQL. Нереляционные базы данных обрабатывают данные, которые не соответствуют традиционной модели таблиц и строк. Эти базы данных используются для хранения и обработки больших объемов неструктурированных данных, таких как данные о социальных медиа, логи серверов и т.д.
В целом, выбор базы данных для системы искусственного интеллекта зависит от типа данных, которые нужно хранить и обрабатывать, а также от требований к производительности и масштабируемости системы.
Существует несколько типов баз данных, которые были специально разработаны для работы с искусственным интеллектом. Ниже приведены некоторые из наиболее распространенных типов баз данных, ориентированных на искусственный интеллект:
Базы данных графов. Базы данных графов предназначены для хранения и обработки связанных данных в виде графов. Они хранят данные в узлах и ребрах, позволяя легко и быстро извлекать информацию об отношениях между объектами. Базы данных графов широко используются в анализе социальных сетей, рекомендательных системах и других задачах, связанных с искусственным интеллектом.
Базы данных временных рядов. Базы данных временных рядов предназначены для хранения и обработки временных данных, таких как данные о температуре, погоде, финансовых рынках и других накоплениях больших объемов сырых данных (например логирование, журналированик) т.д. Они обычно предоставляют специальные функции для агрегирования, фильтрации и анализа данных.
интеллектуальная база данных - это полнотекстовая база данных с компонентами искусственного интеллекта (AI), которые взаимодействуют с пользователями, чтобы гарантировать, что пользователи получают всю необходимую информацию.
Базы данных для обработки естественного языка. Базы данных для обработки естественного языка предназначены для хранения и обработки текстовых данных. Они предоставляют специальные функции для анализа и классификации текста, поиска по ключевым словам, а также для создания и обучения моделей машинного обучения для обработки текста.
В целом, выбор базы данных для работы с искусственным интеллектом зависит от конкретной задачи и типа данных, которые нужно обрабатывать.
О перспективах применения систем объектно-ориентированных баз данных и знаний в системах искусственного интеллекта
Практика эксплуатации реляционных систем управления базами данных выявила значительные ограничения в реляционной модели представления данных. В настоящее время назрела необходимость отказаться от реляционной модели и обратить внимание на незаслуженно забытые сетевые и объектно-ориентированные модели представления данных. Это позволит уже в ближайшее время достичь заметного успеха в применении средств искусственного интеллекта при решении актуальных проблем современного бизнеса.
- ИИ – искусственный интеллект;
- БД – база данных;
- БЗ – база знаний;
- РБД – реляционная (табличная) база данных;
- ОБД – объектная база данных;
- РМД – реляционная модель представления данных;
- ОМД – объектная модель представления данных;
- СУБД – система управления базой данных;
- СУБЗ – система управления базой знаний;
- РСУБД - система управления реляционной базой данных;
- СООБЗ – сетевая объектно-ориентированная база знаний.
Как известно, в настоящее время получили широкое распространение системы управления базами данных основанные на реляционной модели данных. У большинства разработчиков программного обеспечения и системных аналитиков имеется стойкое предубеждение, что реляционная модель окончательно победила в соревновании и вытеснила с рынка другие модели представления данных. Я считаю что такая ситуация является временной и в ближайшем будущем мы все станем свидетелями ломки этого стереотипа. Системы управления базами данных сами по себе не представляют ценности для пользователей. Даже данные, хранящиеся в базах, не представляют особой ценности сами по себе. Основной ценностью обладают законченные приложения, позволяющие пользователям моделировать некоторые аспекты своей деятельности и бизнеса с использованием вычислительной техники. Существующие в настоящее время бизнес-процессы характеризуются высокой сложностью. Наблюдается тенденция усложнения бизнес процессов в связи с развитием процессов интеграции и глобализации. Соответственно ужесточаются требования к модели представления данных бизнес-процесса.
Несмотря на имеющиеся достоинства, реляционная модель представления данных обладает и рядом недостатков. В случае нормализации модели предметной области БД представляет собой множество связанных друг с другом таблиц. Наряду с тривиальной необходимостью выполнять множество соединений на множестве таблиц, такая структура значительно усложняет сопровождение базы данных. При изменении бизнеса приходится заново проектировать новый вариант нормализованной базы и выкидывать труд разработчиков, затраченный на разработку предыдущей версии БД и приложений, работающих с предыдущей версией. Не спасает ситуацию и проектирование реляционной структуры таблиц, специально рассчитанной на изменения модели бизнеса в процессе эксплуатации приложения. В этом случае, разработчики реляционных БД используют три подхода.
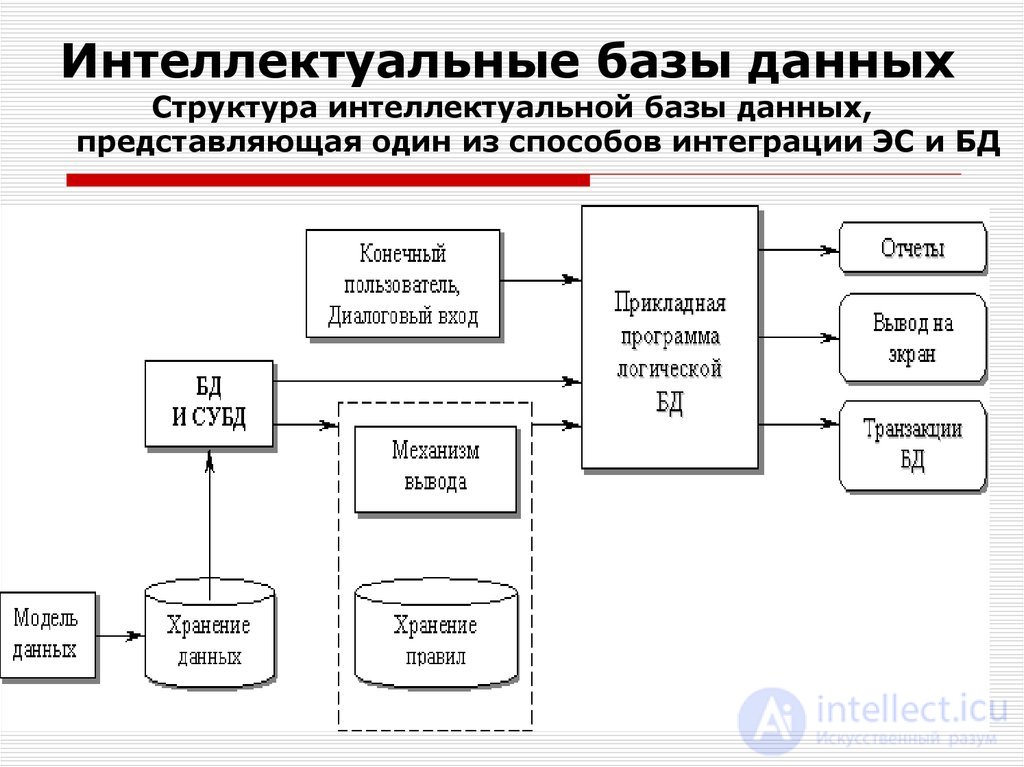
Итак, плачевная ситуация, сложившаяся в области использования реляционных систем управления базами данных продолжает усложнятся. Мы все можем наблюдать, как производители РСУБД от отчаяния вводят в свои продукты объектные расширения (Oracle, Informix, …) и возможности по обработке XML, реализацию бизнес логики приложения на стороне СУБД средствами процедурных языков (Oracle, Microsoft, …). По сути эта ситуация говорит о поражении реляционной модели данных как универсального средства моделирования современных бизнес процессов.
Владельцы существующих систем управления реляционными базами данных, вложившие в разработку продуктов многие миллионы долларов, маркетологи, имеющие основной задачей рекламу продукта на рынке и просто наивные пользователи пытаются нас убедить в том, что развитие РМД эволюционным путем может сохранить инвестиции и решить все описанные проблемы. Так ли это?
Для ответа на этот вопрос отвлечемся от систем управления базами данных и рассмотрим моделирование бизнес-процесса, как основную задачу, которая сегодня решается с применением СУБД. Очевидно, что целью индустриализации нашего общества является замена труда человека на труд машины. Информатизация общества ведет к замене интеллекта человека на интеллект машины. Автоматизация бизнес-процессов доведенная до абсолюта предполагает полное отчуждение человека от выполнения рутинных интеллектуальных задач. В результате можно сделать вывод, что доведенная до абсолюта система моделирования бизнес-процессов должна обладать искусственным интеллектом. Внедрение такой системы должно оставить за человеком только творческие задачи, полностью автоматизировав рутинные операции по управлению современным предприятием. Такая система должна обладать знаниями и способностями, сопоставимыми с бизнес-аналитиком среднего уровня. Это означает, что система управления базой знаний (именно знаний, а не данных) должна обеспечить представление и обработку модели бизнес-процесса сопоставимой по своей сложности с моделью бизнес-процесса, используемой сознанием человека. Системы, которые не соответствуют этому требованию, рано или поздно окажутся устаревшими и будут заменены на системы, обладающие искусственным интеллектом. Да, это перспектива не самого ближайшего времени. Но бизнес уже сейчас делает вызов разработчикам ставя задачи, которые требуют применения средств искусственного интеллекта. Отсутствие систем ИИ в широкой эксплуатации обусловлено вовсе не отсутствием задач, требующих для своего решения моделей, основанных на ИИ. Задачи по автоматизации бизнеса поставлены не вчера, и не позавчера, они поставлены еще в эпоху появления первых счет и арифмометров. Текущий уровень разработок информационных систем определяется текущем уровнем достижений в области моделирования и обработки бизнес данных и бизнес знаний. Наши пользователи получают вовсе не то что им надо, а всего лишь то, что мы в состоянии разработать, пользуясь модными средствами разработки.
Как видно из анализа РМД, проведенного здесь ранее - РМД вовсе не предел мечтаний. Сами производители РСУБД понимают сложившуюся ситуацию, и медленно эволюционируют под воздействием давления общественности к «постреляционным моделям представления данных». Производители РСУБД и финансируемые ими группы ученых озабоченны в первую очередь сохранением многомиллионных инвестиций. Большинство разработчиков любой ценой стараются сохранить эволюционный путь развития СУБД. Поэтому, в исследованиях, посвященных «постреляционным моделям», нет ни слова об искусственном интеллекте как средстве моделирования бизнес процессов. Исходя из проведенного анализа, становится, очевидно, что в далекой перспективе, попытки реанимировать РМД обречены на провал. В попытке решить современные проблемы бизнеса был выбран заведомо тупиковый путь развития – развивать РМД куда-то туда, в будущее. На вызов, который брошен бизнесом, возможно ответить только применив хорошо зарекомендовавший себя метод «от общего к частному». Вместо того чтобы под давлением обстоятельств проводить усовершенствования РМД стихийно - наслаивая одно изменение на другое, следует посмотреть на проблему сверху в низ: определить генеральный путь развития от текущего состояния СУБД/СУБЗ вплоть до систем ИИ. В этом случае вовсе не РМД может оказаться той стартовой точкой, начиная от которой можно с меньшими совокупными затратами достичь святого Грааля современной ИТ индустрии – искусственного интеллекта.
Промышленность и клиенты нуждаются в системах управления знаниями. Специалистам, работающим в области ИИ, известно множество моделей представления знаний, обладающих не меньшей, а возможно, большей гибкостью и универсальностью, по сравнению с РМД. Достаточно распространенными и известными моделями представления знаний являются иерархические семантические сети, активные семантические сети, семантические сети фреймов, скрытые Марковские модели, ... В последнее время второе рождение переживают нейронные сети. История развития нейронных сетей заслуживает отдельного внимания. Развитие науки в этом направлении было заторможено на десятилетия после критических публикаций, объявивших нейрокомпьютинг тупиковой ветвью научно технического прогресса. Позже авторы признали свою излишнюю категоричность, но время было упущено. К счастью, наука является более демократичным сообществом по сравнению с индустрией программного обеспечения. Мнение авторитета в науке не довлеет столь сильно на рядовых ученых, по сравнению с давлением корпораций на рядового разработчика. Сегодня исследования искусственных нейронных сетей возобновлены, и о прогрессе в этой области мы узнаем уже не только из научных публикаций, но и из средств массовой информации. А вот в сфере систем управления базами данных реляционная модель сохраняет свои «незыблемые» и монопольные позиции. Так же как и в случае с искусственными нейронными сетями, модели данных, конкурирующие с РМД, были объявлены тупиковым направлением, а исследования в областях иерархических, сетевых и объектно-ориентированных систем управления базами данных значительно заторможены. РСУБД завоевали рынок коммерческих СУБД. Первое время эйфория, вызванная этими СУБД, была в значительной мере обоснованной. Заметную долю бизнеса занимают финансовые операции. Финансовые данные в своей естественной форме представлены в виде разнообразных таблиц. Поэтому реляционная модель оказалась здесь как нельзя, кстати, и заняла сектор финансовых приложений. На данный момент этот сектор уже освоен и автоматизирован в значительной степени. РСУБД постепенно осваивает смежные области. Области бизнеса, оставшиеся без автоматизации характеризуются моделью представления данных, далекой от табличной формы. В связи с этим заметно значительное замедление темпов распространения РМД. Теперь, разработчики РБД вынуждены расширять РМД средствами по хранению и обработке сложных структур данных.
Бизнес требует автоматизации любой, а не только финансовой деятельности. Для моделирования любой бизнес модели требуется система искусственного интеллекта и система управления базами знаний. Поэтому в далекой перспективе все попытки усовершенствования РМД так или иначе обречены завершится или провалом или созданием ИИ. Здесь возможны два пути. Эволюционный - когда путем случайных блужданий под давлением текущих еще не автоматизированных бизнес задач РМД плавно трансформируется в модель представления знаний ИИ. И революционный - когда разработчики, четко понимая стоящую перед ними цель, сразу приступят к созданию систем управления базами знаний, используя все то лучшее, что накоплено за годы исследований в области искусственного интеллекта. В любом из двух вариантов, текущему состоянию РМД и текущим попыткам ее реанимировать места не будет. Модель представления данных, пригодная для использования в системах ИИ будет весьма далека от РМД. Тратить огромные ресурсы на эволюционное развитие РМД в такой ситуации – слишком дорогое удовольствие. Тем более, что в случае успеха, от РМД останутся только воспоминания. Я предлагаю отказаться от эволюционного подхода. При разработке СУБД/СУБЗ следующего поколения, РМД следует рассматривать как равную среди равных. Разработку модели представления данных и знаний СУБД/СУБЗ следующего поколения следует вести ориентируясь не на миллионы долларов, затраченные на разработку текущих продуктов, а на эффективность применения решений в перспективных системах ИИ. Это позволит идти к намеченной цели абсолютной автоматизации бизнес процессов по прямой, а не под давлением случайных флюктуаций, вызванных очередным ограничением РМД при моделировании бизнес процесса.
Какая модель представления данных, известная на сегодняшний день, более адекватно отражает модель мира и реальности, в которой мы все живем? Я считаю, что это сетевая объектно-ориентированная модель представления данных и знаний. Современные успехи в области объектно-ориентированных методов разработки программного обеспечения также подтверждают эту мысль.
Недостатками объектных баз данных обычно считают трудности в реализации объектных представлений, трудности в реализации незапланированных запросов к базе и необходимость итерации по коллекциям объектов при поиске объектов по значениям их атрибутов. Если сравнивать чистую РМД и чистую ОМД, то можно согласится, что представления в РМД можно рассматривать как отношения, однако представления объектов в ОМД рассматривать как объекты тяжелее. В практических случаях, в таблицы РБД вводят суррогатные ключи для обеспечения требования «нет сущности без идентификатора». В этом случае РБД обретает трудности полностью эквивалентные ОБД в реализации представлений. Об этом, например, свидетельствуют множество ограничений при реализации updatable views. Следовательно, на практике, с точки зрения реализации представлений ОБД и РБД можно считать практически равноправными. Трудности реализации незапланированных запросов к базе объектов являются вымышленными. Незапланированные запросы к дереву объектов можно реализовать, например, на основе языков OQL или XPath. Для оптимизации поиска объектов по значению их атрибутов в ОБД, так же как и в РБД возможно создание и использование индексов. Итак, с точки зрения рассмотренных возможностей ОМД не уступает РМД.
Вероятно, наиболее перспективным направлением, которое может привести к созданию ИИ, являются искусственные нейронные сети со способностями к самомодификации и самоанализу. Такими способностями обладают разработанные автором семантические нейронные сети. Как следует из проведенного анализа, для реализации модели нейронной сети перспективным является применение сетевых объектно-ориентированных систем управления базами знаний. Я считаю, что модель нейронной сети следует реализовать в виде приложения, выполняемого в контексте сетевой объектно-ориентированной системы управления базой данных. Компоненту управления знаниями следует реализовать уже в контексте самомодифицирующейся нейронной сети. В настоящее время технология РБД имеет слишком сильное влияние на разработчиков ОБД. Существующие реализации ОБД выполнены с учетом совместимости с РБД. Это значительно повлияло на модель существующих реализаций ОБД, причем с моей точки зрения, не в лучшую сторону. При реализации системы управления базами знаний требуется предусмотреть возможности моделирования нейронных сетей со свободной топологией и универсальной моделью поведения отдельного нейрона. Я считаю, что система управления объектной БЗ должна быть функционально достаточна для моделирования семантической нейронной сети. В связи с этим я принял решение разработать собственную исследовательскую модель сетевой объектно-ориентированной базы знаний Cerebrumмодель представления объектов которой ориентированна на дальнейшее использование в семантической нейронной сети.
Разработанная система обладает следующими возможностями:
- Сохранять текущее состояние графа объектов или нейронной сети в СООБЗ между сеансами работы с пользователем. В том числе сохраняется текущая топология сети объектов. При повторном запуске приложения не понадобится создавать сеть объектов заново.
- При большем количестве экземпляров объектов ограничить объем памяти, используемый графом объектов или нейронной сетью. Наиболее часто используемые объекты остаются в оперативной памяти, остальные вытесняются в файловое хранилище и загружаются в оперативную память по мере необходимости. При загрузке экземпляра в оперативную память он вытесняет другие, редко используемые объекты. Ограничение объема памяти позволяет избавиться от использования файла подкачки операционной системы, что значительно повышает производительность моделирования сетей с большим количеством экземпляров объектов (при суммарном размере всех экземпляров большем, чем размер текущей свободной памяти в системе)
- В случае если объем сети объектов меньше чем размер текущей свободной памяти в системе, вся сеть находится в оперативной памяти и потерь производительности, связанных с сериализацией-десериализацией .не возникает.
Применение СООБЗ не накладывает никаких ограничений на используемую бизнес логику объекта или математическую модель нейрона, которую можно реализовать как методы объектов, находящихся в СООБЗ.
Объектно-ориентированная модель представления данных, используемая в Cerebrum, свободна от перечисленных ранее недостатков РБД. Возможность моделировать сложноструктурированные объекты позволяет объединять несколько экземпляров объектов в единое целое, называемое компонентом. В отличие от РМД, такой компонент может храниться в базе данных как единое целое. Это значительно увеличивает эффективность работы системы. Но не это главное. Так как компонент представляет собой агрегацию нескольких экземпляров объектов, в объектной модели, возможно динамически изменять внутреннюю структуру компонента, не затрагивая при этом структуры других компонентов того же типа, хранящихся в БД. Объектная модель позволяет реализовывать наследование классов и множественное наследование интерфейсов. В отличие от рассмотренного ранее первого подхода, ООБД позволяет изменять внутреннюю структуру отдельно взятого компонента, не влияя на другие компоненты, находящиеся в БД. Это решает проблему представления и обработки версий объектов. Наличие развитой информации о типах позволяет обращаться к внутренней структуре такого компонента, так же как и к отдельным полям таблицы в случае РМД. В отличие от второго подхода, сохраняя возможность работать с внутренней структурой компонента, ООБД позволяют избавиться от разрастания размера индексов и необходимости применять соединения при доступе к атрибутам компонента. Так же исчезают проблемы потери типа атрибутов и трудности при реализации коллекций объектов. Объектная модель свободна от ограничений третьего подхода на количество атрибутов одного типа. Дополнительными достоинством объектной модели представления данных является возможность трактовать любую представляемую в БД сущность как объект. Это позволяет сохранять в атрибутах объекта не только простые значения, но и компоненты со сложной внутренней структурой.
Уже сейчас результаты теоретических исследований и практических экспериментов позволяют успешно реализовать сетевую объектно-ориентированную систему управления знаниями. Такая система окажется полезна не только в решении перспективных задач, но и при решении насущных проблем бизнеса, традиционно решаемых с использованием РСУБД. Я считаю, что, учитывая необходимость перехода к системам, основанным на ИИ, требуется отказаться от догмы о превосходстве реляционной модели данных и сосредоточить основные усилия в исследованиях и разработках альтернативных моделей. Я надеюсь, что сетевая объектно-ориентированная база знаний Cerebrum позволит определить путь дальнейшего развития систем управления данными и знаниями и приблизит создание промышленных систем с искусственным интеллектом.
Если я не полностью рассказал про базы данных в ии? Напиши в комментариях Надеюсь, что теперь ты понял что такое базы данных в ии, интеллектуальная база данных и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Представление и использование знаний

Комментарии