Лекция
Привет, Вы узнаете о том , что такое сентенциальное программирование, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое сентенциальное программирование, рефал , настоятельно рекомендую прочитать все из категории Стили и методы программирования.
рефал — предметно-эквациональный способ определения функций на свободном моноиде с дополнительной одноместной операцией.
(А. П. Бельтюков. Определение Рефала для чистых математиков.)
Рефал—замечательный язык!На нем можно запрограммировать все, что угодно, если, конечно, других языков не знать.
Студент УдГУ
сентенциальное программирование возникает тогда, когда данные имеют четкую и достаточно сложную глобальную структуру, действия направлены прежде всего на перестройку этой структуры, а задача в целом соответствует инварианту:
действия глобальны, условия глобальны. (5.1)
В этом случае необходимы мощные средства распознавания глобальных условий, которые естественно погрузить в модель вычислений языка как атомарные средства. Программист при формулировке условий может позволить себе не задумываться о том, как происходит ихраспознавание, и сосредоточиться на самой важной части: описании перестроек структуры.
В имеющихся сейчас двух наиболее развитых и альтернативных системах сентенциального программирования Prolog и Рефал при распознавании условий происходит еще и подготовка информации для применения перестройки. Эта особенность —
подготовка информации для действий в ходе распознавания условий, (5.2)
пожалуй, является характерной для сентенциального программирования. В частности, она отделяет те случаи, когда лучше пользоватьсясентенциальным программированем, и те случаи, когда целесообразно событийное программирование (см. далее). Проверка приоритетов и выбор действия с наивысшим приоритетом в качестве активного точно так же запрятаны в атомарные действия программной системы, но программист при проверке приоритетов не получает никакой полезной информации для проведения выбранного действия.
В настоящее время глобальная проверка условий в системах сентенциального программирования осуществляется путем обработкиметавыражений. Метавыражение отличается от выражения тем, что в нем встречаются переменные. Например, если маленькими буквами обозначаются постоянные, а большими -- переменные, то 1+а -- выражение, 1+X -- метавыражение. При проверке выясняется возможность отождествить некоторые метавыражения друг с другом или с данными и попутно вычисляется подстановка, т. е. функция, сопоставляющая переменным их значения. подстановка дает необходимую для выполнения шага работы программы информацию. В только что приведенном примере при отождествлении вместо X должно быть подставлено а.
Такой способ работы согласуется с формулировкой глобальных условий в логике и в теории алгоритмов, но его нельзя считать a prioriисчерпывающим. В дальнейшем могут появиться другие формы глобальной проверки данных.
Язык Рефал был создан В. Ф. Турчиным для программирования символьных преобразований. Исходный толчок он получил от идеиалгорифмов Маркова (см., например, теоретическое приложение к книге [ 21 ] ), но эта идея была полностью пересмотрена в ходе работы по созданию языка. Идейный и математический уровень проработки языка исключительно высокий, но вопросы дизайна почти проигнорированы.
В основе языка лежит (другой по сравнению с языком PROLOG) частный случай операции отождествления: конкретизация метавыражения.
Под конкретизацией понимается такой частный случай отождествления, при котором переменные встречаются лишь в метавыражении и поиск их значений происходит путем подбора без рекурсии.
Язык Рефал определен через три компонента: структуру данных, Рефал -машину, обрабатывающую эти данные, и собственно конкретный синтаксис языка.
Данные, обрабатываемые языком Рефал, представляют собой последовательности атомов, структурированные несколькими согласованными между собою видами скобок. Например, в некотором конкретном синтаксисе такое выражение могло бы иметь вид {a+[b-(c+d)**2]/3}*(a+d). В поле памяти Рефал -машины задействованы два вида скобок: структурные и функциональные.
Выражения языка Рефал.
В конкретном синтаксисе Рефала функциональные скобки обозначаются < >, структурные -- ( ). Атомы делятся на:
В поле памяти выделяется основная часть, а также стеки глобальных данных - закопанные данные. Перед каждым шагом исполнения в основной части поля памяти выделяется активная часть - поле зрения. Данные в поле зрения и закопанные данные имеют общую структуру1, которая является подструктурой структуры поля памяти. Поскольку и программа имеет практически ту же самую структуру2, в ходе развития языка появилась третья структура данных ( метаданные ), расширяющая поле памяти.
Дадим точные определения.
Объектное выражение — выражение, не содержащее функциональных скобок.
Минимальное функциональное выражение — выражение, имеющее вид <E>, где E — объектное выражение.
поле памяти Рефал -машины представляет собой набор выражений, одно из которых называется основной частью . В основной части в любой момент, за исключением момента выдачи окончательного результата и остановки программы, есть функциональные скобки.
Поле зрения (активная часть) поле памяти — первое из встречающихся в основной части поля памяти минимальных функциональных выражений.
Детерминатив — первый символ в функциональной скобке.
Детерминатив интерпретируется как имя функции, обрабатывающей содержимое функциональных скобок. Эта функция должна определяться статически, поэтому в ходе вычислений не могут образовываться выражения вида < <e.1> e.2>. В подавляющем большинстве случаев детерминатив должен быть именем, но некоторые обычные символы, например +, также могут использоваться в качестве детерминативов.
Пример 5.2.3. Рассмотрим пример памяти Рефал -машины в ходе вычислений.
Поле памяти:
'aaxzACDE' <Sort < Perm 'G'1.5E5 > <Perm 115 'F'> <Perm 112 -2.0E-5>><Sort AllRight Sort Perm 'QRTS'>'XZ<(')
Поле зрения выделено в поле памяти жирным шрифтом. Заметим, что в поле памяти можно выделить данные, обработка которых уже завершена и которые не изменятся до конца исполнения программы (те, которые находятся вне программных скобок; в нашем случае'aaxzACDE' и 'XZ<('). У символов, представляющих скобки, есть 'обычные' двойники, не обязательно имеющие парные и не влияющие на структурирование выражения. Первый атом Perm стоит в позиции функции, а последний из атомов Perm стоит в позиции данных, так что имена функций могут формироваться3 динамически. При записи программы пробелы, если они не находятся внутри символьных констант, игнорируются, за исключением тех, которые отделяют один символ от другого (эти пробелы просто опускаются после того, как на этапе лексического анализа сыграли роль разделителей). И, наконец, еще одна тонкость. 123 — это один атом, '123' — три атома,-123.0 — опять один атом, -123 — два атома: символ '-', после которого стоит число.
Кроме основной части поля памяти, в ходе исполнения может появиться несколько стеков закопанных выражений, например:
Stack1 '=' 15 Stack2 '=' Perm B A
21 Perm C2 C1
-45 Perm 'X' 20
60
В принципе, несколько стеков — избыточная конструкция. Но, поскольку здесь стеки рассматриваются как общие области памяти, лучше в каждом модуле иметь свой стек. К сожалению, явной связи между стеками и модулями в Рефал -программах нет.
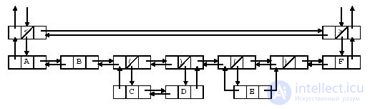
Допустим, есть строка < AB(CD)(E)F>. Она во всех известных нам Рефал -системах представляется двунаправленным списком, изображенным на рис. 5.1. Этот формат представления стал общераспространенным для Рефал -систем, начиная с реализации, описанной в[ 25 ] . Однако он не является обязательным.
При реализации языка Рефал В. Ф. Турчин задумался, как избежать слишком частых обращений к каким-то суррогатам возможностей традиционных языков. Он решил заранее описать алгоритм преобразования выражений и подобрать для него подходящую структуру данных. Описанный им алгоритм хорошо работает с целым классом случаев, включая те, которые заранее не предусматривались, — отличительный признак концептуально продуманного решения. В лекции, относящийся к языку PROLOG можно увидеть, что происходит, если структуру данных хорошо не продумать на ранних этапах, а тем более зафиксировать случайные промежуточные результаты как стандарт.
Более того, описанные Турчиным алгоритм и структуры данных являются отличной базой для точного определения семантики на базеабстрактного синтаксиса языка Рефал.
Преобразование выражений в формат для обработки делается один раз, при вводе информации либо при трансляции программы.
Рассмотрим конкретный синтаксис выражений.
Идентификатор — любая последовательность цифр и букв, начинающаяся с большой буквы. Об этом говорит сайт https://intellect.icu . Идентификатор является символьным литералом и представляет составной символ. Символы, заключенные в одинарные ' ' кавычки, являются символьными литералами, представляют сами себя. Дважды повторенная кавычка представляет кавычку. Двойные кавычки " " используются для ограничения имени составного символа, не обязательно являющегося идентификатором4. Если вне кавычек встречается символ, не являющийся скобкой, частью идентификатора или числа, это трактуется как ошибка.
Определение метавыражения Рефала получается из определения выражения добавлением еще одного базисного случая: переменная является метавыражением.Переменные не могут быть детерминативами.
Метавыражение называется образцом, если оно не содержит функциональных скобок.
В конкретном синтаксисе обозначение переменной включает тип и символ переменной, записываемые как тип.атом. В стандартномРефале имеются переменные трех типов: символьные ( s.First ), термовые ( t.Inner ) и общие ( e.Last ).
Значением символьной переменной служит атом, термовой — терм (символ или выражение в скобках), общей — произвольное (может быть, пустое) объектное выражение.
Рефал развивался как язык символьных преобразований в самом широком смысле этого слова, и поэтому в него была заложена возможность обрабатывать собственные программы. Он предоставляет стандартные функции метакодирования, взаимно-однозначно и взаимнообратно преобразующие произвольное метавыражение в объектное и наоборот. Таким образом, появляется возможность создавать программы в ходе выполнения других программ и затем выполнять их "на лету". Такая возможность, просто гибельная для программ в большинстве систем и стилей программирования, в данном случае не приводит ни к каким отрицательным последствиям из-за уникального концептуального единства и продуманности языка5.
Основные два шага в Рефал -вычислениях — конкретизация переменных в образце в соответствии с областью зрения и подстановкаполученных значений в другое метавыражение. В языке рассматривается лишь частный случай конкретизации.
Конкретизация образца Me в объектное выражение E называется такая подстановка значений вместо переменных Me, что после применения данной подстановки Me совпадет с E .
Заметим, что одно и то же метавыражение может иметь много конкретизаций в одно и то же объектное выражение. Например, рассмотримметавыражение
e.Begin s.Middle e.End (5.3)
и объектное выражение
AhAhAh 'OhOhOh' (Ugu','Udgu) '(((' Basta'!'
(5.4)
Имеется 11 вариантов конкретизации (5.3) в (5.4) (проверьте!).
Если у метавыражения Me есть много вариантов конкретизации в E, то они упорядочиваются по предпочтительности в следующем порядке.
Пусть Env1 и Env2 — два варианта конкретизации Me в P. Рассмотрим все вхождения переменных в Me. Если Env1 и Env2 не совпадают, они приписывают некоторым переменным различные значения. Найдем в P самое первое слева вхождение переменной, которому Env1 и Env2 приписывают разные значения и сравним длину этих значений. Та из конкретизаций, в которой значение, приписываемое данному вхождению переменной, короче, предшествует другой и имеет приоритет перед ней.
Например, сопоставим объектное выражение (A1 A2 A3)(B1 B2) с образцом e.1 (e.X s.A e.Y) e.2. В результате получится следующее множество вариантов сопоставления:
{e.1 = , eX = , sA = A1, eY = A2 A3, e.2 = (B1 B2) }
{e.1 = , eX = A1, sA = A2, eY = A3, e.2 = (B1 B2) }
{e.1 = , eX = A1 A2, sA = A3, eY = , e.2 = (B1 B2) }
{e.1 = (A1 A2 A3), eX = , sA = B1, eY = B2, e.2 = }
{e.1 = (A1 A2 A3), eX = B1, sA = B2, eY = , e.2 = }
Пример 5.1. Множество вариантов сопоставленияВарианты сопоставления перечислены в соответствии с их приоритетами, т. е. самый первый вариант находится на первом месте и т. д. Описанный способ упорядочения вариантов сопоставления называется сопоставлением слева направо.
Тот алгоритм конкретизации, который используется в Рефале, называется проецированием и согласован с введенным нами отношением порядка. Опишем его (описание взято из учебника Турчина). Обратите внимание, как в данном случае общая и не всегда эффективно реализуемая операция 'проецируется' на свою частную реализацию, одновременно повышающую эффективность, сохраняющую общность и предписывающую методику программирования.
Вхождения атомов, скобок и переменных будут называться элементами выражений. Пропуски между элементами будут называтьсяузлами. Сопоставление E: P определяется как процесс отображения, или проектирования, элементов и узлов образца P на элементы и узлы объектного выражения E. Графическое представление успешного сопоставления приведено на рис. 5.2. Здесь узлы представлены знаками o.
Следующие требования являются инвариантом алгоритма сопоставления и их выполнение обеспечивается на каждой его стадии.

Предполагается, что в начале сопоставления граничные узлы P отображаются в граничные узлы E. Процесс отображения описывается при помощи следующих шести правил. На каждом шаге отображения правила 1–4 определяют следующий элемент, подлежащий отображению; таким образом, каждый элемент из P получает при отображении уникальный номер.
На рис. 5.2 сопоставление производится следующим образом. Вначале имеется два жестких элемента с одним отображенным концом: 'A'и s.3. В соответствии с Правилом 3 отображается 'A', и этот элемент получает при отображении номер 1.Номера 2 и 3 будут назначены левой и правой скобкам согласно Правилам 3 и 1. Внутри скобок начинается перемещение справа налево, так как t.2 является жестким элементом, который может быть отображен, в то время как значение e.1 еще не может быть определено. На следующем шаге обнаруживается, что e.1 является закрытой переменной, чью проекцию не требуется обозревать для того, чтобы присвоить ей значение; что бы ни было между двумя узлами, это годится для присвоения (на самом деле, значение e.1 оказывается пустым). Отображение s.3завершает сопоставление. Расположение отображающих номеров над элементами образца дает наглядное представление описанного алгоритма:
1 2 5 4 3 6 'A' ( e.1 t.2 ) s.3
Этот сложный алгоритм упрятан в простые программные конструкции.
Программа на Рефале является последовательностью определений функций. Каждое описание функции в Рефале имеет вид
Имя функции {Последовательность сопоставлений}
Каждое сопоставление имеет вид
Образец = Метавыражение;
Относительное расположение членов последовательности определений никакой роли не играет, и функции можно группировать из логических или технологических соображений. Относительное расположение сопоставлений внутри определения функции существенно.
Пример 5.3.2. Рассмотрим пример Рефал -программы.
Pre_alph {
*1. Отношение рефлексивно
s.1 s.1 = T;
*2. Если буквы различны, проверить, входит ли
* первая из них в алфавит до второй
s.1 s.2 = <Before s.1 s.2 In <Alphabet>>; }
Before {
s.1 s.2 In e.A s.1 e.B s.2 e.C = T;
e.Z = F; }
Alphabet {
= 'abcdefghijklmnopqrstuvwxyz'; }
Листинг 5.3.1. Программа вычисления предиката предшествования одного символа другому в заданном алфавитеСтроки, начинающиеся с *, служат комментариями. Последняя из функций Alphabet введена для технологичности, чтобы определение алфавита было в одном месте и его легко было изменять. Так что функция с пустым образцом может пониматься как константное выражение. In является атомом-разделителем, заведомо не встречающимся в алфавите.
Последнее из правил сопоставления в Before применимо всегда. Такое сопоставление гарантирует, что предикат никогда не заканчивается неудачей.
Если взаимное расположение функций никакой роли не играет, то внутри функции расположение сопоставлений важно. Сначала применяется первое из сопоставлений, при неудаче переходят ко второму и так далее до последнего.
Заметим, что в языке Рефал отсутствие сопоставления, конкретизацией которого является текущая область зрения, означает аварийный останов программы с выдачей текущего поля памяти и закопанных данных. Пожалуй, это достаточно технологичное решение, поскольку для тех, кто сам желает обрабатывать ошибки, всегда имеется возможность поместить последней строкой в определение функции правило видаe.A=Обработка ошибки ;
Имеются также встроенные функции, в частности, функции работы с числами <'+' s.Number1 s.Number2> и подобные ей.
Рассмотрим связь между языком и программным окружением.
Для запуска Рефал -программы необходимо инициализировать поле памяти. Принято, что в начале выполнения программы поля памятиимеет вид
<Go >
Таким образом, вначале применяется функция Go к пустому полю зрения. Эта функция должна быть определена в программе одним сопоставлением с пустым образцом и не может вызываться никакой другой функцией. Поскольку чаще всего программа должна обрабатывать имеющиеся в файле исходные данные, в типичном случае описание функции Go выглядит примерно следующим образом:
$ENTRY Go { =<Prog <Open 'r' 1 'data.txt'><Get 1> >}
В нашей программе 5.3.1 алфавит определен статически. Было бы хорошо иметь возможность заменять эту глобальную информацию. Для хранения динамической глобальной информации (чаще всего числовых характеристик либо словарей) в языке Рефал имеются стандартные функции работы со стеками закопанных данных. Функция
<Br e.N '=' e.Е >
рассматривает свой первый аргумент (который должен быть строкой символов, не включающей '=' ) как имя стека, и помещает свой второй аргумент на вершину этого стека. Если стек был пуст, то он создается. Соответственно, функция
<Dg e.N>
выкапывает верхушку стека. Если стек пуст, то ошибки нет, просто выдается пустое выражение. Несколько других функций дополняют возможности работы с глобальной информацией. Cp копирует верхушку стека без ее удаления, Rp замещает верхушку стека на свой аргумент, DgAll выкапывает сразу весь стек.
Ввод-вывод организован в Рефале довольно лаконично, без излишеств. Имеется функция открытия канала ввода, которая открывает файл либо для ввода, либо для вывода (в этом случае первым аргументом служит 'r' и присваивает ему номер. Одна строка символов из файла читается с помощью функции Get, заменяющей свой вызов на прочитанную строку, одна строка пишется в файл путем функций
<Put s.Channel e.Expression>
либо
<Putout s.Channel e.Expression>
Вторая функция стирает свое поле зрения, а первая оставляет в качестве результата напечатанное выражение.
Следует заметить, что эти функции читают и пишут именно последовательности символов. При их использовании программист должен сам преобразовать последовательности цифр в числа, а скобки-символы в структурные скобки. Более того, при выводе часть информации теряется: невозможно различить последовательность букв и идентификатор, последовательность цифр и число, структурные скобки и скобки-символы. Поэтому имеется еще одна совокупность функций, автоматизирующих преобразование. Каждая из этих функций обрабатывает сбалансированное по скобкам выражение. При вводе это выражение заканчивается пустой строкой.
<Input s.Channel> или <Input e.File-name>
<Xxin e.File-name> или <Xxin s.Channel>
<Xxout s.Channel e.Expr> или
<Xxout (e.File-name)e.Expr>
Первая из функций предназначена для ввода файлов, подготовленных вручную. Вторая и третья — для обмена промежуточной информацией с диском.
Только что перечисленные функции вместе с функцией Go требуют объяснения инструментов модульности в Рефале. Рефал -модуль — просто Рефал -программа, не обязательно включающая Go. Функции, предоставляемые в пользование другим модулям, описываются спецификатором $ENTRY как входы. В свою очередь, использующий модуль должен описать внешние функции:
$EXTRN F1,F2,F3;
Вызов программы, состоящей из нескольких модулей, производится оператором примерно следующего вида:
refgo prog1+functions+reflib
Модуль основной программы должен идти первым. Никаких средств включить требование вызова модуля в текст другого модуля нет, модули сопрягаются внешним образом. При конфликтах имен берется определение функции из первого в порядке подключения модуля.
В частности, только что описанные расширенные функции ввода-вывода определяются в стандартном модуле reflib.
Важнейшими средствами современного Рефала является работа с метавыражениями. Базовое ее средство — встроенная функция Mu, которая заключает свой аргумент в функциональные скобки и тем самым дает возможность вычислить динамически построенное выражение. По словам Турчина, Mu работает так, как работало бы определение
Mu { s.F e.X = <s.F e.X> },
если бы оно было синтаксически допустимо.
В частности, через Mu работает стандартный модуль Рефала e (Evaluation), дающий возможность вычислить динамически введенное выражение. Он обрабатывает это выражение через функцию Upd, которая должна быть добавлена к модулю, где осуществляется динамическое вычисление выражений. Например, если добавить описание
$ENTRY Upd {e.X = <Mu e.X>;}
то командная строка refgo e+prog1 приведет к требованию написать выражение. Это выражение будет сделано полем памяти программыprog1 и вычислено, а результат выведен. Например, написав для программы 5.3.1
<Alphabet>
мы получим в качестве результата
'abcdefghijklmnopqrstuvwxyz'
Естественно возникает вопрос об обработке внутри языка не только объектных, но и произвольных выражений. Для этого имеются стандартные функции Up и Dn. Первая из них превращает объектное выражение в выражение произвольного вида, вторая кодирует свою область зрения (ею, по семантике языка, может быть лишь объектное выражение) в форме, годящейся для общих выражений и дажеметавыражений. В стандартном комплекте Рефала есть даже модуль прогонки, который позволяет подать на вход программыметавыражение и вычислить его настолько, насколько это возможно без знания значений переменных.
При решении сложных задач на Рефале естественно возникла задача представления мультииерархической структуры. Для частного случая двух независимых иерархий, одна из которых считается главной, а вторая начнет работать после исчерпания главной, в Рефале разработано мультискобочное представление выражений.Оно поддерживается библиотечными функциями кодирования и декодирования выражений и программ, переводящих мультискобочное выражение в его стандартный код и наоборот. Для частного случая, когда вторичная иерархия — наши обычные скобки, а первичная иерархия — ссылка глубоко внутрь скобочного выражения, неявно задающая одноуровневую скобочную структуру, независимую от стандартной, алгоритм кодирования исключительно прост. Выражение разбито на две несбалансированные по скобкам части: левую и правую. В обеих частях непарные скобки заменяем на пары )(. Открывающую скобку высшего уровня представляем как ((, место, куда ведет ссылка — как ))(, закрывающую скобку высшего уровня как )).
И в заключение рассмотрим достаточно сложный алгоритм на Рефале, иллюстрирующий многие приемы программирования: хранение промежуточной информации, обработку ошибок, ввод-вывод.
Пусть у нас дано выражение с различными парными скобками (в конкретном случае мы используем пары '()[]{}<>', но программа составлена так, чтобы эти пары можно было заменить в любой момент). Для эффективной работы на Рефале это выражение нужно закодировать, используя структурные скобки. Кодом пары скобок Левая Правая будут скобки (Левая и Правая). Ниже дан алгоритм кодировки.
При записи данного алгоритма используется еще одна возможность Рефала -5. После образца через запятую может идти произвольное выражение, включающее свободные переменные образца, а затем другой образец. Во втором образце мы отождествляем вспомогательное выражение, не изменяя значений переменных, унаследованных из предыдущего образца. Если после второго образца идут фигурные скобки, то мы задаем безымянную функцию внутри функции. Если же их нет, то это отождествление рассматривается как дополнительное условие успешности первого отождествления. Эта иерархия вложенности может продолжиться на несколько уровней, причем переменные внешних уровней на внутренних уровнях остаются связанными, уже не изменяя значений.
Иерархически вложенные функции и условия в принципе не нужны для Рефала, но их использование позволяет сократить и, главное, лучше структурировать текст программы.
$ENTRY Go{=<Init>;}
$EXTRN Xxout;
* Инициализация поля зрения и констант
Init{=<Open 'r' 1 'Input.txt'><Trans <Acquire(<Get 1>)";}
Acquire {
e.Got ()= e.Got;
* Конец ввода - пустая строка
e.Got (e.New)=<Acquire e.Got e.New (<Get 1>)>;
}
Brackets {=('()')('[]')('')('<>');}
Trans {
e.A =<Result <Pairing () e.A > >;
}
Pairing {
* В первой скобке содержится последовательность всех незакрытых
* скобок вместе с сегментами данных, подлежащими помещению
* в даннуюпару скобок;
* каждый сегмент данных также заключен в скобки
(e.Unclosed (e.LastUn)(s.Lbrack e.Middle)) s.Rbrack e.Last,
<Brackets>: e.A(s.Lbrack s.Rbrack ) e.B =
* Встретилась правая скобка, парная последней незакрытой;
* выбрасываем отработанный сегмент из поля зрения
<Pairing (e.Unclosed (e.LastUn (s.Lbrack e.Middle s.Rbrack))) e.Last>;
((s.Lbrack e.Middle)) s.Rbrack e.Last,
<Brackets>: e.A(s.Lbrack s.Rbrack ) e.B =
* Парная незакрытой, находящейся внутри другой незакрытой
(s.Lbrack e.Middle s.Rbrack) <Pairing () e.Last>;
(e.Unclosed (e.LastUn)(s.Lbrack e.Middle)) s.Rbrack e.Last,
<Brackets>: e.A(s.Lbrack1 s.Rbrack ) e.B =
* Непарные скобки
<Prout "Brackets Mismatch!"> Error;
(e.Unclosed ) s.Lbrack1 e.Last,
<Brackets>: e.A(s.Lbrack1 s.Rbrack ) e.B =
* Еще одна открывающая скобка; создаем новую группу данных
<Pairing (e.Unclosed (s.Lbrack1)) e.Last>;
() s.Lbrack e.Last,
<Brackets>: e.A(s.Lbrack s.Rbrack ) e.B =
* Первая открывающая скобка
<Pairing ((s.Lbrack)) e.Last>;
() s.Rbrack e.Last,
<Brackets>: e.A(s.Lbrack s.Rbrack ) e.B =
* Первая скобка - закрывающая
<Prout "Extra right bracket"> Error;
* Нейтральный символ вне скобок
() s.Other e.Last = s.Other <Pairing () e.Last>;
* Выражение и скобки исчерпаны - успех
() =;
* Выражение исчерпано, а скобки - нет
(e.Unclosed (e.Lastun))=<Prout "Not all brackets are closed" Error;
* Нейтральный символ в очередной скобке
(e.Unclosed (e.Lastun))s.Other e.Last=
<Pairing (e.Unclosed(e.Lastun s.Other)) e.Last>;
}
Result {
* Если была ошибка, выйти
e.A Error=;
* Иначе вывести результат для дальнейшего использования
e.A =<Xxout ('output.rdt') e.A>;
}
Листинг 5.4.1. Мультискобочное выражение: РефалДля того, чтобы нагляднее увидеть влияние стиля на программные решения, сравните эту программу с развитием программы в традиционном стиле, приведенным в § 11.5 книги [ 22 ] . Данная программа намного выразительнее, короче, легче модифицируема и не менее эффективна, чем программа 11.5.3 из указанного параграфа.
В практике работы со студентами автору приходилось сталкиваться с ситуацией, когда программа для одной и той же задачи, написанная на традиционном языке, была более чем в пять раз длиннее программы на Рефале. Так что использование специализированных инструментов окупается (естественно, когда они применены в подходящих случаях).
Из литературы по языку Рефал можно рекомендовать учебные пособия [ 37 ] , первое из которых имеется в общедоступном русском переводе, в частности на сайте http://www.refal.ru/diaspora.html.
Выводы из данной статьи про сентенциальное программирование указывают на необходимость использования современных методов для оптимизации любых систем. Надеюсь, что теперь ты понял что такое сентенциальное программирование, рефал и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Стили и методы программирования
Ответы на вопросы для самопроверки пишите в комментариях, мы проверим, или же задавайте свой вопрос по данной теме.
Комментарии
Оставить комментарий
Стили и методы программирования
Термины: Стили и методы программирования