Лекция
Привет, Вы узнаете о том , что такое статистические техники для анализа естественного языка, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое статистические техники для анализа естественного языка , настоятельно рекомендую прочитать все из категории Создание вопросно-ответных систем.
l The dog ate.
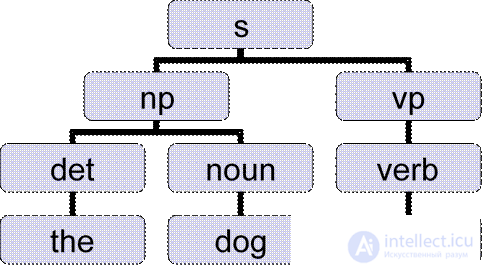
l Salespeople sold the dog biscuits.

l Тупой – 90%
l Современные – 97%
l Человек – 98%
l Применяем тупой алгоритм.
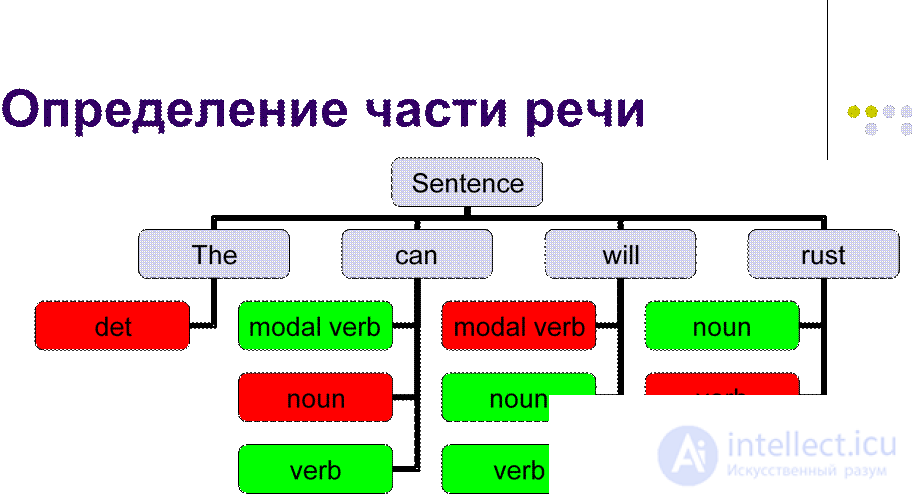
l Есть набор правил:
l Поменять у слова таг X на таг Y, если таг предыдущего слова – Z.
l Применяем эти правила сколько-то раз.
l Работают быстрее
l Тренировка HMM vs. Тренировка TT
(Отсутствие начальной базы)
l Строим на основе предложения деревья, пользуясь существующими грамматическими правилами.
l Пример:
(s (np (det The) (noun stranger))
(vp (verb ate)
(np (det the) (noun doughnut)
(pp (prep with) (np (det a) (noun fork)))))
l Проверка
l Есть готовые примеры из Pen treebank l Сравниваем с ними
l Нахождение правил для применения
l Назначение вероятностей правилам
l Нахождение наиболее вероятного
|
l sp → np vp |
(1.0) |
|
l vp → verb np |
(0.8) |
|
l vp → verb np np |
(0.2) |
|
l np → det noun |
(0.5) |
|
l np → noun |
(0.3) |
|
l np → det noun noun |
(0.15) |
|
l np → np np |
(0.05) |

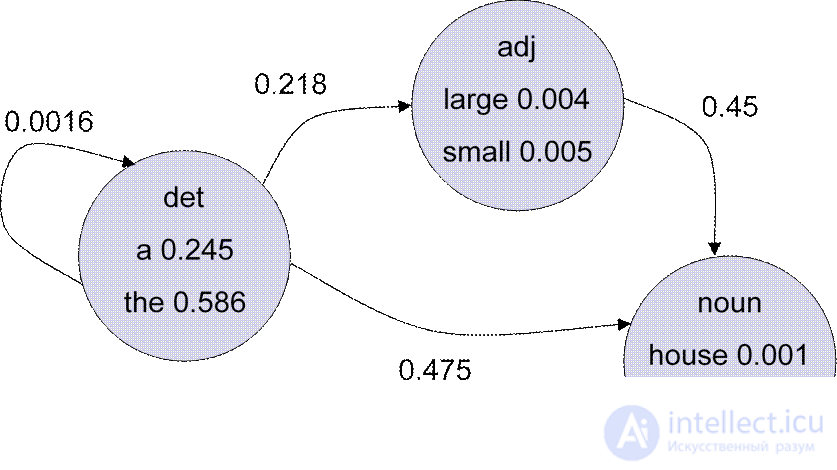
Построение собственной PCFG. Об этом говорит сайт https://intellect.icu . Простой вариант.
l Берем готовый Pen treebank
l Считываем из него все деревья l Читаем по каждому дереву
l Добавляем каждое новое правило
l P(правило) = количество его вхождений, деленное на общее количество
l Решают проблему существования очень редких правил
l Идея – вместо хранения правил, считаем вероятности того, что, например

c
l Каждой вершине дерева припишем слово (head), характеризующее ее.
l p(r | h) – вероятность того, что будет применено правило r для узла с заданным h.
l p(h | m, t) – вероятность того, что такой h является ребенком вершины с head = m и имеет таг t.
l Пример
(S (NP The (ADJP most troublesome) report)
(VP may
(VP be
(NP (NP the August merchandise trade deficit)
(ADJP due (ADVP out) (NP tomorrow)))))
l p(h | m, t) = p(be | may, vp)
l p(r | h) = p(posvp → aux np | be)
l “the August merchandise trade deficit”
l rule = np → det propernoun noun noun noun
|
Conditioning events |
p(“August”) |
p(rule) |
|
Nothing |
2.7*10^(-4) |
3.8*10^(-5) |
|
Part of speech |
2.8*10^(-3) |
9.4*10^(-5) |
|
h(c) = “deficit” |
1.9*10^(-1) |
6.3*10^(-3)
|
В заключение, эта статья об статистические техники для анализа естественного языка подчеркивает важность того что вы тут, расширяете ваше сознание, знания, навыки и умения. Надеюсь, что теперь ты понял что такое статистические техники для анализа естественного языка и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Создание вопросно-ответных систем
Из статьи мы узнали кратко, но содержательно про статистические техники для анализа естественного языка
Комментарии
Оставить комментарий
Создание вопросно-ответных систем
Термины: Создание вопросно-ответных систем