Лекция
Привет, Вы узнаете о том , что такое производительность sql exists и in и join, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое производительность sql exists и in и join , настоятельно рекомендую прочитать все из категории Методы выявления ошибок в SQL приложении.
Я создал запрос, который использует подзапрос, который нужно сравнить с основным запросом. Я хочу знать, как лучше всего выполнить эту задачу. Должен ли я использовать оператор IN? EXISTS? Или, может быть, JOIN? Мне нужно знать, какие варианты будут действительны для моего варианта использования и какой из них будет работать лучше всего. Мне тоже нужно это доказать.
Как и во многих ситуациях в SQL Server, ответ зависит от обстоятельств. В этом совете будут рассмотрены плюсы и минусы каждого метода и будет использована повторяемая методология, чтобы определить, какой из методов обеспечит максимальную производительность.
Все демонстрации в этом мини исслеовании будут использовать записи демо базы данных. Ваши результаты могут отличаться от полученных мной но методология и сами принципы решения будут общими.
Подзапрос, который будет использоваться, будет представлять собой список трех лучших продавцов за один квартал на основе количества счетов. Для простоты примеров запросов этот подзапрос будет сохранен как представление. Для такого простого запроса, как этот, вероятно, нет разницы в производительности между использованием view-SQL, CTE-SQL или традиционного подзапроса.
Оператор IN может использоваться для поиска строк в запросе, в которых один столбец может быть сопоставлен со значением в списке значений. Список значений может быть жестко закодирован как список, разделенный запятыми, или может поступать из подзапроса, как в этом примере.
Инструкции IN легко писать и понимать. Единственным недостатком является то, что они могут сравнивать только один столбец из подзапроса с одним столбцом из основного запроса. Если необходимо сравнить 2 или более значений, оператор IN использовать нельзя.
Ниже приведен запрос, который возвращает некоторые счета-фактуры, принадлежащие нашей верхней группе продавцов. Обратите внимание, что подзапрос возвращает ровно одну строку. Это требование для использования оператора IN. Также обратите внимание, что запрос в круглых скобках сам по себе является полностью функциональным запросом. Он может быть выделен и выполнен сам по себе.
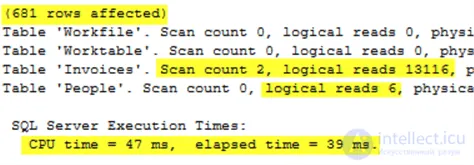
Эта информация выводится при выполнении этого запроса с включенными функциями STATISTICS IO и STATISTIC TIME или EXPLAIN .
Этот вывод даст нам некоторые показатели производительности для сравнения с другими вариантами. Об этом говорит сайт https://intellect.icu . Если вы не знаете, как получить этот результат, обратитесь к документации EXPLAIN или STATISTICS IO .
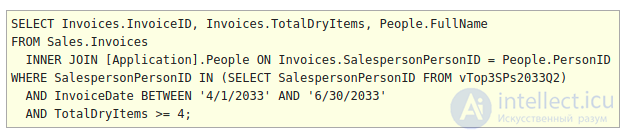
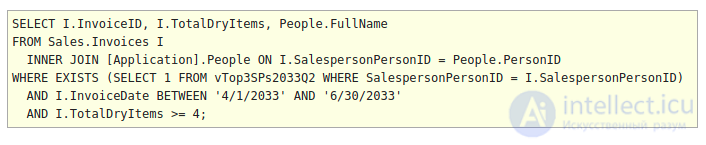
Оператор EXISTS работает аналогично оператору IN, за исключением того, что его можно использовать для поиска строк, в которых один или несколько столбцов из запроса могут быть найдены в другом наборе данных, обычно в подзапросе. Жесткое кодирование невозможно с EXISTS.
Ниже представлен тот же запрос, что и выше, за исключением того, что IN был заменен на EXISTS. Формат EXISTS и его подзапроса немного отличается от формата IN. В этом случае подзапрос ссылается на столбец I.SalespersonPersonID, который кажется доступным для подзапроса. По этой причине подзапрос не может быть выполнен сам по себе и может быть выполнен только в контексте всего запроса. Иногда это бывает трудно понять.
Логически можно представить себе это как выполнение подзапроса один раз для каждой строки в основном запросе, чтобы определить, существует ли строка. Если строка существует при выполнении подзапроса, то возвращаемое логическое значение - истина. В противном случае это ложь. Выбранные столбцы подзапроса не имеют значения, поскольку результат привязан только к существованию или отсутствию строки на основе предложений FROM / JOIN / WHERE в подзапросе.
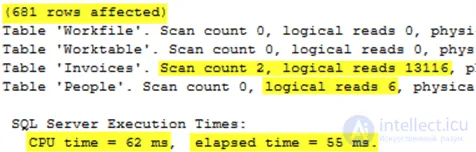
Выполнение этого запроса возвращает следующий статистический вывод, который практически идентичен оператору IN.
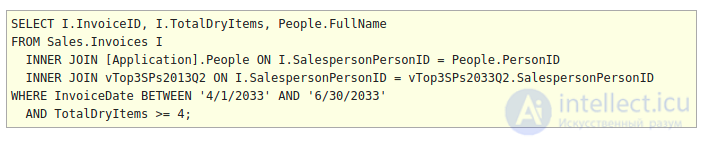
Обычное соединение JOIN можно использовать для поиска совпадающих значений в подзапросе. Как и EXISTS, JOIN позволяет использовать один или несколько столбцов для поиска совпадений. В отличие от EXISTS, JOIN проще реализовать. Обратной стороной JOIN является то, что если в подзапросе есть какие-либо идентичные строки на основе предиката JOIN, то основной запрос будет повторять строки, что может привести к неверным выводам запроса. И IN, и EXISTS игнорируют повторяющиеся значения в подзапросе. Соблюдайте особые меры предосторожности, когда садитесь за стол таким образом. В этом примере представление не будет возвращать повторяющиеся значения SalespersonPersonID, поэтому это безопасная реализация JOIN.
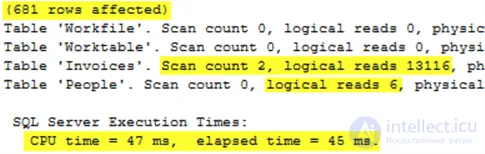
Выполнение этого запроса возвращает следующий статистический вывод, который, опять же, практически идентичен версиям запроса IN и EXISTS.
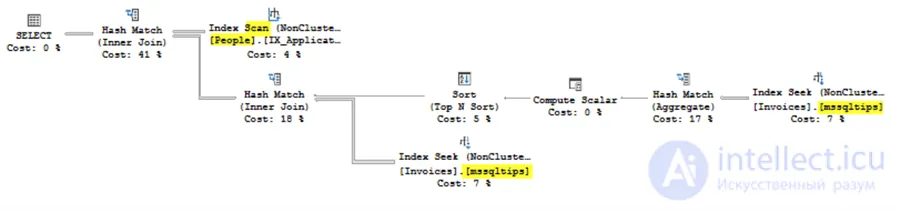
Статистика для каждой из этих трех опций практически идентична, поскольку оптимизатор объединяет все 3 опции в один и тот же план запроса. В этом можно убедиться, выполнив все три запроса вместе, просматривая фактические планы выполнения. На снимке экрана ниже показан один план, но один и тот же план отображается в каждом из трех вариантов запроса.

Каждая копия плана запроса показывает отсутствующую рекомендацию по индексу. Выполнение этой рекомендации и создание индекса изменит планы и статистику производительности запросов. Будет ли он изменять их все одинаково? Давай выясним. Сначала создайте индекс, затем повторно запустите 3 запроса.
Теперь снова выполните все 3 оператора вместе. Происходит кое-что интересное. Все 3 плана изменились по сравнению с версиями, которые были до создания индекса, но на этот раз они не идентичны. У IN и EXISTS один и тот же новый план, но у JOIN другой план.
План для IN и EXISTS использовал новый индекс дважды и выполнил поиск по таблице People.

Этот план был создан для версии запроса JOIN. Он использовал новый индекс дважды, но выполнил сканирование таблицы людей.
Проверка статистики ввода-вывода и времени для 3 запросов показывает идентичную статистику для 2 запросов с общим планом, но улучшенную статистику и время выполнения для версии JOIN. Если бы это был запрос, готовящийся к продвижению в производственную среду, то, вероятно, лучшим вариантом было бы использование JOIN.

Этот запрос является отличным примером того, что, хотя оптимизатор стремится обрабатывать все параметры одинаково, он не всегда это делает. Использование этой методологии проверки производительности, наряду с пониманием ценности и ограничений каждой опции запроса, позволит программисту сделать лучший выбор в каждой ситуации.
Исследование, описанное в статье про производительность sql exists и in и join, подчеркивает ее значимость в современном мире. Надеюсь, что теперь ты понял что такое производительность sql exists и in и join и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Методы выявления ошибок в SQL приложении
Из статьи мы узнали кратко, но содержательно про производительность sql exists и in и join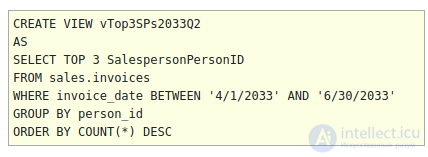

Комментарии
Оставить комментарий
Базы данных - Методы выявления ошибок в SQL приложении
Термины: Базы данных - Методы выявления ошибок в SQL приложении