Лекция
Привет, Вы узнаете о том , что такое словарный запас, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое словарный запас , настоятельно рекомендую прочитать все из категории Создание электронных словарей, тезаурусов, онтологий.
Задачей исследования было определить объем пассивного словарного запаса носителей русского языка. Измерение проводилось с помощью теста, в котором респондентам предлагалось отметить знакомые слова из специальным образом составленной выборки. По правилам теста слово считалось «знакомым», если респондент мог дать определение хотя бы одному его значению. Методика теста подробно описана здесь. Чтобы повысить точность теста и выявить респондентов, проходящих его неаккуратно, в тест были добавлены несуществующие слова. Если респондент отмечал хотя бы одно такое слово как знакомое, его результаты не учитывались. В исследовании приняло участие более 150 тысяч человек (из них прошло тест аккуратно — 123 тысячи).
Для начала, проанализируем влияние возраста на словарный запас.
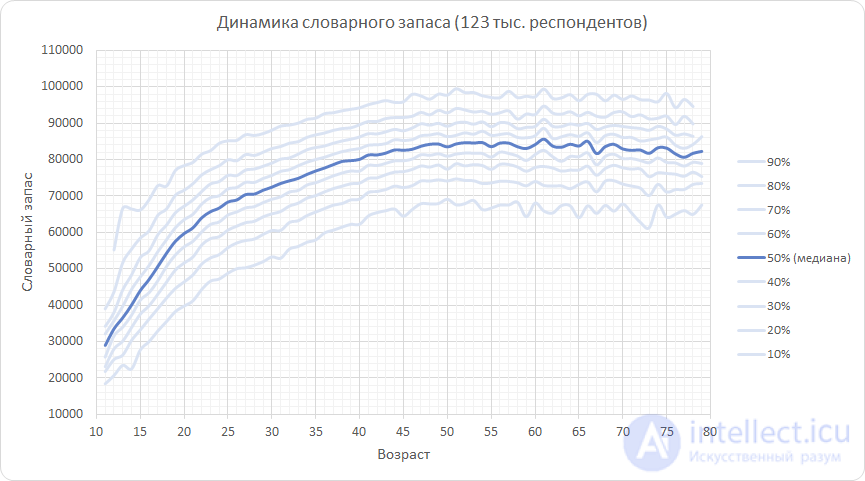
На графике показаны перцентили полученного распределения. Например, самая нижняя кривая (10-ый перцентиль) для 20 лет дает 40 тысяч слов. Это означает, что 10% респондентов этого возраста имеют словарный запас ниже этого значения, а 90% — выше. Выделенная синим центральная кривая (медиана) соответствует такому словарному запасу, что половина респондентов соответствующего возраста показали результат хуже, и половина — лучше. Самая верхняя кривая — 90-ый перцентиль — отсекает результат, выше которого показали только 10% респондентов с максимальным словарным запасом.
Из графика видно следующее:
Теперь разделим всех респондентов на группы по уровню образования. На следующем графике изображены медианы словарного запаса этих групп. Кривые начинаются и заканчиваются в разных местах из-за того, что статистика по всем группам разная — например, респондентов с неоконченным средним образованием старше 45 было недостаточно много, чтобы результаты были статистически значимы, поэтому пришлось оборвать соответствующую кривую так рано.
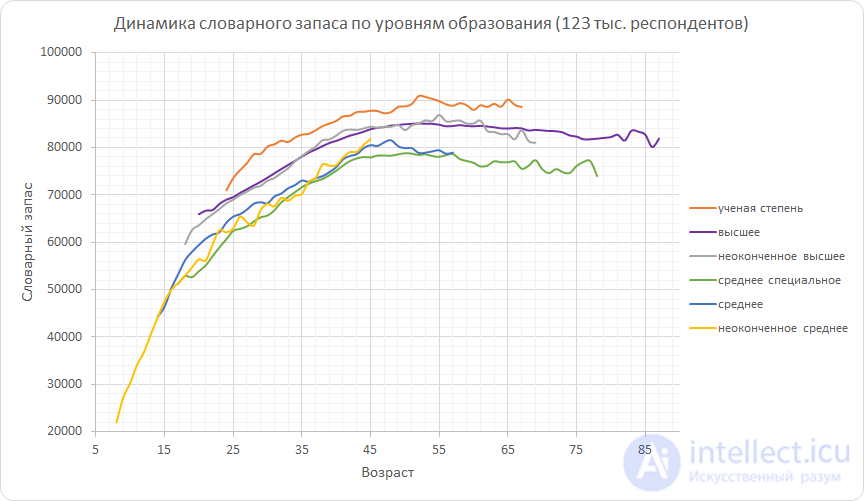
Из графика можно узнать, что
Теперь исключим влияние возраста, оставив в выборке только респондентов старше 30 лет. Это позволит сконцентрироваться на образовании.
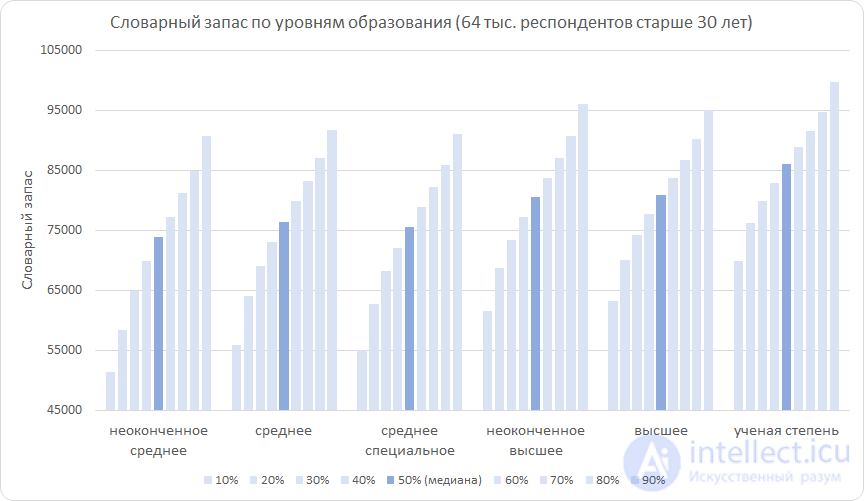
Из графика мы видим следующее:
Получившиеся в результате исследования величины словарного запаса — десятки тысяч слов — кажутся довольно большими. Этому есть две причины. Во-первых, измерялся пассивный словарный запас (слова, которые человек узнает в тексте или на слух), а не активный словарный запас (слова, которые человек использует в речи или на письме). Эти запасы отличаются в разы — пассивный всегда значительно больше. Подсчитанные словарные запасы писателей, например, являются именно активными. Во-вторых, в тесте все производные слова учитывались отдельно (например, «работа» и «работать», или «город» и «городской»).
Отдельно хочется заметить, что полученные результаты не дают представление о словарном запасе «среднестатистического» (если такой вообще существует) носителя русского языка. Например, уровень образования респондентов, прошедших тест, значительно выше общероссийского — 65% респондентов имеют высшее образование, тогда как в России таких только 23% (поданным всероссийской переписи населения 2010 года). Затем, очевидно, что респонденты, прошедшие интернет-тест, в основном являются активными пользователями интернета, и это также делает выборку специфичной (в основном для пожилых людей). В конце концов, далеко не всем интересно определить свой словарный запас, среди наших же респондентов таких — 100%. Логично предположить, что полученные по такой особенной выборке результаты словарного запаса должны быть несколько выше «среднестатистических».
Итак, полученные данные выявили сильную зависимость словарного запаса от возраста, и более слабую — от уровня образования. Очевидно, что есть и другие факторы, влияющие на словарный запас — чтение, общение, работа, хобби, образ жизни.
Задача данного теста — определить ваш пассивный словарный запас (то есть количество слов, которые вы узнаете при чтении и на слух). Единственный способ сделать это точно — взять словарь потолще (тысяч на сто слов), отметить все слова, которые вы знаете, и посчитать их. Вряд ли найдется желающий пойти на подобное испытание. Задача, к счастью, значительно упрощается, если сделать одно разумное предположение — вероятность знания слов, использующихся в языке одинаково часто, примерно одинакова. Иными словами, если вы знаете слово «кошка», то и слово «собака» вы также будете знать, а если не знаете, что такое «амбивалентность», то и «трансцендентальность» не знаете тоже. Таким образом, можно сгруппировать слова по сложности — от простых до самых редких, и из каждой группы выбрать по одному представителю. Если вы знаете это слово — можно считать, что и всю группу вы тоже знаете. Если групп достаточно много (хотя бы сто), то такой метод позволит определить словарный запас довольно точно.
Технически использованная методика определения словарного запаса проста, однако дьявол, как всегда, в деталях.
Итак, первой задачей было построить достаточно полный частотный словарь русского языка (к сожалению, существующие частотные словари слишком малы для определения словарного запаса начитанного носителя русского языка). Для этого нужны две вещи. Первое — как можно более полный словарь русского языка; был использован толковый словарь Ефремовой (136 тыс. слов, небольшое количество слов было также взято из словаря Хагена), http://www.speakrus.ru/dict). Второе — корпус русского языка; был использован Национальный Корпус Русского Языка (http://www.ruscorpora.ru). Корпус состоит из большого количества (86 тысяч) текстов разной тематики — художественная литература, публицистика, научные и научно-популярные, религиозные и философские тексты, личная переписка, дневники; общий объем текстов — 230 миллионов слов. За счет большого объема и широкого охвата этот корпус представляет собой слепок современного (54% всех текстов были созданы после 1950-го года) русского языка. Для каждого слова из словаря Ефремовой с помощью корпуса была найдена его частота — мера того, как часто это слово употребляется в языке (частота обычно измеряется в количестве употреблений слова на миллион слов корпуса). Получившийся частотный словарь был затем отсортирован — от высокочастотных (простых) слов к низкочастотным (сложным).
Основная идея статистического подхода к оценке словарного запаса заключается в том, что вероятность знания слова испытуемым зависит от частотности этого слова (того, как часто это слово встречается в текстах или используется в речи). Это, однако, не совсем так. К примеру, слово "думать" встречается в 100 тысяч раз чаще, чем "думающий", однако если испытуемый знает одно из них, то, скорее всего, знает и другое. Можно сказать, что существуют некоторые "словарные гнезда". В каждое гнездо входят одно основное слово, а также его производные, которые можно образовать от основного по простым правилам с помощью приставок и суффиксов. Зная любое слово из гнезда и обладая некоторым лингвистическим чутьем, можно догадаться о значении всех остальных слов этого гнезда. Частотный словарь был перегруппирован с учетом таких гнезд.
В тестах на словарный запас английского языка подобные гнезда называются "word families", причем знание одной word family приравнивается к знанию одного слова. Таким образом, в оценке словарного запаса учитывается знание только основных слов, но не их производных. Существуют общепринятые правила формирования word families (L. Bauer and P. Nation, Int. J. Lexicography (1993)). В русском языке, к сожалению, таких правил не разработано. Из-за этого было принято решение давать оценку словарного запаса, учитывая не только основные, но и производные слова тоже.
Методика определения словарного запаса является двухэтапной. На первом этапе отсортированные слова делятся на 40 групп (первые группы содержат самые простые слова, последние – самые сложные). Из каждой группы выбирается тестовое слово; получившиеся 40 тестовых слов формируют первый тестовый набор. По результатам ответов можно приблизительно определить нижнюю и верхнюю границы словарного запаса. Ниже нижней границы испытуемый знает практически все слова. Выше верхней – не знает практически ничего. На следующем этапе отсортированные слова в этом приблизительном диапазоне делятся на более мелкие группы и формируется второй тестовый набор. Окончательная оценка словарного запаса — это сумма слов во всех группах, тестовые слова из которых испытуемый пометил как известные. Идея адаптивного тестирования в два этапа была заимствована на сайте http://testyourvocab.com.
Тест можно проходить много раз — из-за большого количества тестовых слов (около 1200) они будут повторяться довольно редко. Стандартное отклонение оценки при этом составляет около 4%. Это означает, что в 68% всех прохождений оценка будет лежать в пределах плюс-минус 4% от среднего, в 96% - в пределах плюс-минус 8% от среднего. Простыми словами — если вы прошли тест два раза, то оценки вполне могут отличаться на 10-15%, это неизбежное следствие статистического подхода.
Тест строится на предположении, что испытуемый честно и внимательно отмечает знакомые слова. К сожалению, это не всегда так. Чтобы распознавать случаи неаккуратного прохождения, в тест были введены слова-ловушки. Такие слова звучат, как русские, но ничего не обозначают. Их нет ни в одном словаре; более того, даже поисковые системы не находят их в интернете. Если испытуемый отмечает такое слово как знакомое, его результат считается недостоверным и не включается в итоговое исследование словарного запаса русскоговорящих. Однако оценка, которую человек получает, никак не модифицируется (выдается только словесное предупреждение о недостоверности результатов).
Методика тестирования реализована на языке Python с использованием веб-фреймворка Flask и фронтэнда Zurb Foundation.
Как вы уже, скорее всего, убедились (если прошли тест) – методика определения словарного запаса работает. По крайней мере, она дает некоторую достаточно разумную оценку. Чтобы улучшить эту оценку, я предлагаю двигаться в двух направлениях. Я, как автор, буду работать над методикой и повышать ее точность. А вы можете прочитать пару-тройку серьезных книг и пройти тест еще раз – результат вам обязательно понравится.
В статье представлена методика первого адаптивного теста для измерения пассивного словарного запаса, разработанного для русского языка. Разобраны этапы подготовки теста: построение частотного словаря, группировка словарных семей, отбор тестовых слов, выбор вида опроса, введение в тест слов-ловушек для контроля честности и внимательности прохождения. Детально рассмотрена новая методика подсчета словарного запаса, основанная на измерении функции знания с ее последующим интегрированием. Валидация и исследование точности показали, что коэффициент надежности теста (0.95) достаточно высок для проведения исследований как на групповом, так и на индивидуальном уровне. Погрешность измерения словарного запаса лежит в пределах 7% для взрослых (>18 лет) респондентов. Работу теста иллюстрируют предварительные данные о возрастной зависимости словарного запаса носителей русского языка, полученные по выборке из 123 тысяч респондентов.
Словарный запас лежит в основе владения языком. Его качественные и количественные характеристики отражают уровень лингвистической компетенции, а также многое говорят об интеллекте, психологическом портрете, роде деятельности и даже привычках человека. Изучение этих характеристик важно для задач педагогики (определение уровня владения языком и качества усвоения предметной лексики), а также психологии и социологии. К сожалению, исследования словарного запаса носителей русского языка практически не ведутся. Одна из причин этого – отсутствие необходимого инструмента. Действительно, один из самых распространенных методов изучения словарного запаса – это измерение его размера. Теоретические основы таких измерений хорошо разработаны на примере английского языка, для которого существует несколько общепринятых тестов [Read 1993; Schmitt, Schmitt, and Clapham 2001]. В то же время, аналогичных тестов для русского языка до недавнего момента не существовало. Тест, представленный в настоящей работе, восполняет этот пробел. Его задача – дать исследователям (педагогам, психологам, социологам) быстрый и точный инструмент для количественной оценки размера пассивного словарного запаса испытуемого.
Методика теста опирается на общепринятый статистический подход [Read 2000]. Его суть состоит в предположении, что вероятность знания респондентом слов, используемых в языке (в книгах, телепередачах, речи) одинаково часто, примерно одинакова. Это позволяет проверять знание респондентом не всех слов языка, что заведомо невозможно, а только небольшого количества специально отобранных тестовых слов, каждое из которых представляет целую группу слов примерно одинаковой частотности. Технически тест проводится в два этапа. На первом этапе респондент получает 40 тестовых слов. Задача респондента – отметить знакомые слова, то есть слова, для которых он может объяснить хотя бы по одному значению. По полученным данным делается приблизительная оценка словарного запаса. На втором этапе респондент получает 80 новых тестовых слов, которые подбираются исходя из этой приблизительной оценки таким образом, чтобы исключить слишком простые или слишком сложные слова. Респондент опять отмечает знакомые слова. По полученным данным (40+80=120 тестовым словам) производится уже более точная оценка словарного запаса. Метод, по которому рассчитывается словарный запас и в первом, и во втором этапах теста, основан на оценке параметров некоторой функции знания респондента с последующим ее интегрированием. Этот метод является новым и не применялся в тестах на словарный запас ранее.
Настоящий тест задумывался как основной инструмент онлайн-проекта по изучению словарного запаса людей, говорящих на русском языке (www.myvocab.info). Проект был инспирирован следующими вопросами: сколько слов знает среднестатистический носитель языка? Какова динамика (рост и уменьшение) словарного запаса родного языка с возрастом? Какие факторы на нее влияют? Проект стартовал в апреле 2014 года и продолжается до сих пор. Об этом говорит сайт https://intellect.icu . На настоящий момент в нем уже приняли участие более 800 тысяч человек, что дает основания полагать, что пока это самый масштабный проект такого типа.
В основной части статьи будет детально рассмотрена методика теста, разобраны этапы, через которые пришлось пройти при его проектировании, проведены валидация, оптимизация и исследование точности теста. В конце будут представлены некоторые предварительные результаты онлайн-проекта, а именно возрастная динамика размера пассивного словарного запаса носителей русского языка.
Существующие частотные словари русского языка ограничены по объему и не содержат редких низкочастотных слов, необходимых для тестирования людей с большим словарным запасом. Так, частотный словарь под редакцией Л.Н. Засориной [Засорина 1977] содержит около 40 тыс. лемм, О. Н. Ляшевской и С. А. Шарова [Ляшевская, Шаров 2009] - 52 тыс. лемм. Поэтому первой задачей разработки теста стало составление более полного частотного словаря русского языка. Для этого был использован толково-словообразовательный словарь Т.В. Ефремовой [Ефремова 2000], содержащий 136 тыс. лемм, и для каждой леммы найдена ее частотность по Национальному Корпусу Русского Языка (http://www.ruscorpora.ru). Корпус состоит из большого количества (86 тысяч) текстов разной тематики — художественная литература, публицистика, научные и научно-популярные, религиозные и философские тексты, личная переписка, дневники; общий объем текстов — 230 миллионов слов. За счет большого объема и широкого охвата этот корпус представляет собой слепок современного (54% всех текстов были созданы после 1950-го года) русского языка.
Основная идея статистического подхода к оценке словарного запаса заключается в том, что вероятность знания слова испытуемым зависит от частотности этого слова. Это, однако, не совсем так. К примеру, слово "думать" встречается в 100 тысяч раз чаще, чем "думающий", однако если испытуемый знает одно из них, то, скорее всего, знает и другое. Поэтому можно сказать, что существуют некоторые "словарные семьи". Зная любое слово из такой семьи и обладая некоторым лингвистическим чутьем, можно догадаться о значении всех остальных слов этой семьи. В тестах на словарный запас английского языка подобные семьи называются "word families", причем знание одной word family приравнивается к знанию одного слова. Таким образом, в оценке словарного запаса обычно учитывается знание только основных слов, но не их производных. Существуют общепринятые правила формирования word families [Bauer and Nation 1993]. К сожалению, для русского языка таких правил найти не удалось.
Задача объединения слов из собранного частотного словаря в словарные семьи была решена следующим образом. Слово добавлялось в соответствующую словарную семью, если по отношению к хотя бы одному слову из этой семьи оно являлось:
136 тыс. слов, таким образом, были распределены в 88 тыс. словарных семей. В качестве примера можно привести следующие получившиеся словарные семьи:
Необходимо заметить, что настоящий список правил представляет собой достаточно грубое приближение к решению проблемы составления словарных семей, если эта проблема вообще может быть решена. Действительно, лингвистическое чутье значительно отличается от человека к человеку и улучшается с увеличением словарного запаса. Поэтому для образованных и начитанных носителей языка словарные семьи должны быть больше, чем для только начинающих учить язык. Возможно, словарные семьи должны строиться экспериментально на основе тестирования большого количества респондентов с разным словарным запасом [Guy, Browne, and Culligan 2013]. Понимая приблизительность принятых нами правил построения словарных семей, мы решили подсчитывать словарный запас в словах, а не словарных семьях. Словарные семьи использовались только для перегруппировки частотного словаря. Слова в итоговом частотном словаре были отсортированы по суммарной частотности соответствующих словарных семей.
Возникает также вопрос о правомерности включения производных слов (например, уменьшительно-ласкательных форм) в подсчет словарного запаса. Он осложняется тем, что статус «производности» неоднозначен. Действительно, в зависимости от словаря, одни и те же слова могут быть представлены либо в рамках одной словарной статьи, либо в разных. В этом вопросе мы действовали по словарю Т.В. Ефремовой [Ефремова 2000], и включали в подсчет словарного запаса каждое слово, имеющее в этом словаре собственную словарную статью.
Идеальный тест на словарный запас должен проверять знание всех слов языка, что не представляется возможным. В реальном тесте используется ограниченное количество тестовых слов, где одно тестовое слово представляет собой целую группу близких по частоте слов. Тестовые слова должны быть максимально «нейтральны» и общеупотребительны, чтобы никакие респонденты не получили преимущества перед другими за счет специфических знаний. В противном случае такое «специфичное» слово будет нерепрезентативно группе, которую оно представляет. При отборе тестовых слов исключались:
Есть несколько общепринятых способов проведения тестов на словарный запас, отличающиеся способом опроса тестируемых. Рассмотрим только два наиболее часто встречающихся варианта. Первый – это тест с множественными вариантами ответа. Тестовое задание может выглядеть так:
«Бестия» - это
Второй – это «знаю/не знаю» тест, где испытуемого просят отметить слова, которые он знает. На первый взгляд, тест с множественными вариантами ответа предпочтителен, так как должен давать более точный результат. В этом варианте знание тестовых слов проверяется, тогда как в варианте «знаю/не знаю» честность ответов остается на совести испытуемого. В действительности оба варианта опроса имеют свои достоинства и недостатки [Meara and Buxton 1987]. Впрочем, эти недостатки могут быть минимизированы при аккуратном подходе к составлению теста. При правильном составлении тестовых заданий, а также достаточном количестве тестовых слов, оба типа тестов дают схожие результаты [Culligan 2015; Pellicer-Sanchez and Schmitt 2012]. Рассмотрим причины, по которым для разрабатываемого теста был выбран более простой «знаю/не знаю» вариант опроса.
Во-первых, на каждое тестовое задание у респондента уходит определенное время. Как будет показано дальше, для достаточно точного определения словарного запаса необходимо проверить знание около 120 тестовых слов. В случае теста «знаю/не знаю» это занимает около 5 минут. В случае теста с множественными вариантами ответа – в несколько раз больше, так как испытуемому требуется прочитать все варианты ответа и мысленно «взвесить» каждый из них. Для онлайн-теста время прохождения критично, потому что проходящие его люди в основном недостаточно мотивированы чтобы тратить много времени.
Во-вторых, составление тестовых заданий в случае теста с множественными вариантами требует серьезных усилий [Аванесов 2005]. Каждый вариант должен быть достаточно реалистичен, чтобы избежать угадывания методом исключения, а также достаточно прост, чтобы не ввести респондента в заблуждение, если он знает тестовое слово. В случае «знаю/не знаю» теста тестовые задания как таковые отсутствуют, что значительно экономит время подготовки теста и облегчает его составление.
У выбранного «знаю/не знаю» типа опроса есть и недостатки. Во-первых, «знание» слова может пониматься разными опрашиваемыми по-разному. Во-вторых, такой тест не позволяет проверить понимание различных значений одного и того же слова. Понимая эти ограничения, в обращении к опрашиваемым перед тестом мы специально оговорили, что следует понимать под знанием: «Считайте, что вы знаете слово, если можете дать определение хотя бы одному его значению. Не отмечайте слова, которые вы видели или слышали, но в значении которых не уверены до конца».
Вид опроса существенно влияет на то, что в итоге измеряет тест. Действительно, «знание» слова – явление многокомпонентное. Так, Пол Нэйшн [Nation 2013] выделил восемь аспектов знания:
Выбор вида опроса определяет, какой из аспектов знания проверяется тестом. Опрос вида «знаю/не знаю» предполагает проверку только пунктов 2 и 7 (написание слова и его значение). Другие аспекты знания также могут быть исследованы, для чего должны быть использованы другие виды опроса [Webb and Sasao 2013].
Другая серьезная проблема «знаю/не знаю» тестов - невозможность проверки правдивости ответов. Опрашиваемый может отметить некоторые тестовые слова как знакомые по невнимательности или специально, чтобы увеличить результат. Для отслеживания таких некорректных ответов обычно вводят тестовые слова-ловушки. Эти слова похожи на настоящие, но не существуют в языке, например, «очудей», «онторология», «тибильга»(- "каска, шлем"(в переводе с тюркских языков).). В зависимости от количества «сработавших» слов-ловушек, результат теста может быть скорректирован [Anderson and Freebody 1983] – чем больше несуществующих слов отметил респондент, тем существеннее уменьшается его результат. Конкретная реализация такой коррекции, однако, вызывает разногласия [Pellicer-Sanchez and Schmitt 2012]. Действительно, невозможно понять, отметил ли респондент слово-ловушку как знакомое из-за невнимательности (прочитав его быстро и приняв за другое), или специально, чтобы увеличить результат. Коррекция в каждом из этих случаев должна быть разная. Из-за этой неопределенности (которую в рамках только «знаю/не знаю» теста вряд ли можно преодолеть) было решено не проводить коррекцию результата. Слова-ловушки, тем не менее, использовались (на 120 тестовых слов – 4 слова-ловушки). Результаты респондентов, отметивших хотя бы одно такое слово, исключались из проводимых исследований словарного запаса.
Для оценки словарного запаса использовался не применявшийся ранее алгоритм. Чтобы пояснить, как он работает, необходимо сделать концептуальное отступление. Основная идея всех тестов на пассивный словарный запас – это представление довольно большой группы слов, близких по частотности, одним тестовым словом. Если респондент знает тестовое слово – считается, что он знает и всю группу, так как слова в ней близки по частотности к тестовому. Эту же идею можно переформулировать, используя понятие ранга – порядкового номера слова в отсортированном по частотности словаре (ранг самого частотного слова, таким образом, равен единице). Если респондент знает тестовое слово с некоторым рангом n, логично предположить, что он также знает и другие слова, ранги которых близки к n. Используя язык физики, можно сказать, что, предъявляя тестовое слово с рангом n и получая ответ от респондента, мы измеряем вероятность знания им слов с рангами, близкими к n. Используя физическую аналогию дальше, можно предположить, что есть некоторая функция вероятности знания слов, которую мы пытаемся измерить, и которая зависит от n – ранга слов. Для каждого респондента такая функция будет своя, характерный же вид ее, однако, будет общий – от единицы (вероятность знания - 100%) для маленьких n (простых слов) до нуля (вероятность знания – 0%) для больших n (сложных, редких слов). Каждое индивидуальное измерение является довольно грубым, так как дает либо 0, либо 1 (если тестовое слово отмечено как незнакомое или знакомое соответственно). Если, однако, провести много таких измерений, оказывается возможным достаточно точно измерить искомую функцию знания. Если эту функцию затем проинтегрировать, то получится ни что иное, как оценка словарного запаса.
Так как характерный вид функции словарного запаса одинаков для всех респондентов, можно попытаться описать ее некоторой аналитической формулой, имеющей желаемую форму - от единицы при малых значениях аргумента до нуля при больших через плавный переход. Удобно использовать следующую двухпараметрическую функцию формула(1):
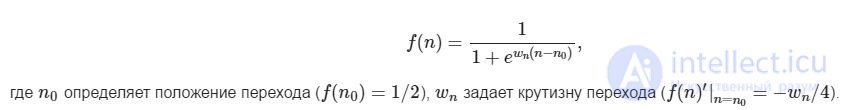
продолжение следует...
Часть 1 Словарный запас иностранного и родного языка
Часть 2 Немного советов при изучении слов - Словарный запас иностранного и
Комментарии
Оставить комментарий
Создание электронных словарей, тезаурусов, онтологий
Термины: Создание электронных словарей, тезаурусов, онтологий