Лекция
Это окончание невероятной информации про словарный запас.
...
class="MathJax_Display">Как показали дополнительные исследования, ограничиться однопараметрической функцией нельзя – при одинаковом положении перехода значение крутизны (для разных респондентов) варьируется в несколько раз; использование трех и более параметров неоптимально и приводит к неоправданному увеличению погрешности оценки.
Оценка словарного запаса (определенный интеграл от функции вероятности знания слов), таким образом, может быть выражена следующей формулой (2):
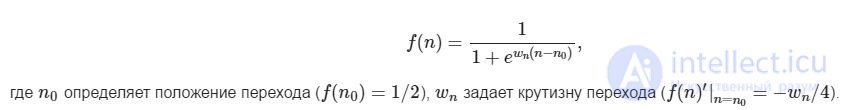
Алгоритм оценки словарного запаса был реализован следующим образом. Каждое тестовое слово (ранга nini) давало одно измерение функции словарного запаса: fi=1fi=1, если респондент пометил тестовое слово как знакомое и fi=0fi=0 – если как незнакомое. Набор таких измерений аппроксимировался функцией (1)(1) по методу наименьших квадратов. Аппроксимация давала значения коэффициентов n0n0 и wnwn, которые подставлялись в формулу (2)(2) для получения оценки словарного запаса.
Измерение словарного запаса описанным методом имеет несколько достоинств. Во-первых, алгоритм позволяет оценить погрешность измерения, а также его качество. Действительно, аппроксимация по методу наименьших квадратов (или любому другому) позволяет оценить не только значения неизвестных коэффициентов функции словарного запаса (n0n0 и wnwn), но и их дисперсию. Это, в свою очередь, позволяет рассчитать дисперсию оценки словарного запаса. Аппроксимация также позволяет рассчитать коэффициент детерминации (он же R-квадрат), который показывает, насколько хорошо выбранная модель (то есть вид функции словарного запаса) аппроксимирует полученные данные. Если дисперсия оценки велика, а коэффициент детерминации мал – это показатель того, что либо выбранный вид функции неверен, либо данных для оценки недостаточно, либо данные содержат аномалии. Как будет показано в разделе «Проверка выбранной функции распределения», первый пункт можно исключить. Поэтому при достаточном количестве тестовых слов (что исключает второй пункт), алгоритм позволяет выявить аномалии в данных. Такие аномалии могут свидетельствовать о невнимательном прохождении теста (в крайнем своем проявлении – об отмечании тестовых слов наобум).
Во-вторых, данный алгоритм позволяет поэтапно увеличивать точность оценки словарного запаса. Так, на первом этапе теста респонденту дается 40 тестовых слов. По этим данным алгоритм определяет приблизительную оценку словарного запаса. На втором этапе респонденту дается уже 80 тестовых слов, ранги которых относительно близки к приблизительной оценке. Эти новые данные добавляются к старым, и алгоритм дает уточненную оценку по уже 120 (40+80) тестовым словам.
В-третьих, оценка словарного запаса получается не в абстрактных единицах (баллах), а в словах, что делает интерпретацию результатов проще.
Валидация теста включала в себя несколько исследований.
Во-первых, было проверено, насколько выбранный вид функции (формула (1) соответствует реальной функции вероятности знания слов.
Во-вторых, был обоснован выигрыш в точности метода при использовании тестирования в два этапа (против тестирования в один).
В-третьих, была оценена точность теста. Эти исследования опирались на данные индивидуальных словарных запасов семи респондентов, прошедших расширенный тест с 1200 тестовыми словами (то есть с полным количеством тестовых слов, использующихся в тесте). Информация о респондентах приведена в Табл. 1. Также по методу расщепления из классической теории тестов был рассчитан коэффициент надежности теста.
Табл. 1. Респонденты, прошедшие расширенную версию (1200 слов) теста.
| Респондент | Возраст, лет | Образование |
|---|---|---|
| A | 29 | Высшее, физическое |
| B | 29 | Высшее, информационные технологии |
| C | 27 | Высшее, инженерное |
| D | 29 | Кандидат философских наук |
| E | 30 | Кандидат физико-математических наук |
| F | 54 | Высшее, педагогическое |
| G | 55 | Высшее, инженерное |
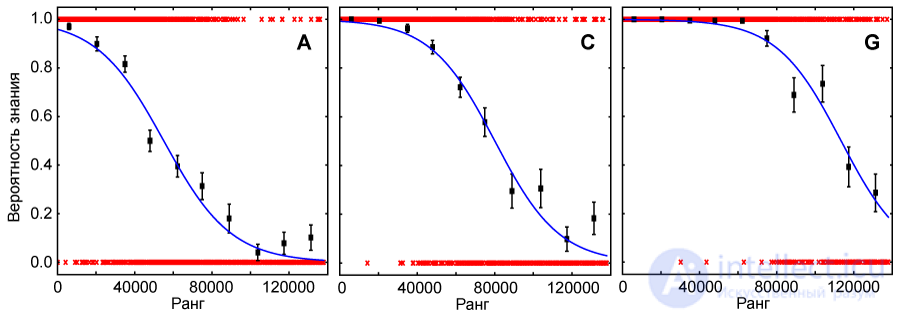
Рис. 1. Функции вероятности знания слов для трех респондентов (см. Табл. 1). Красные кресты – индивидуальные тестовые слова (0 соответствует ответу «не знаю», 1 – «знаю», всего 1200 тестовых слов). Черные квадраты – усредненные вероятности, каждый квадрат соответствует примерно 120 тестовым словам. Синие кривые – аппроксимации тестовых данных функцией, заданной формулой (1).
По методике разрабатываемого теста для получения оценки словарного запаса респондента необходимо проинтегрировать его функцию знания. В обычном варианте теста (со 120 тестовыми словами) измерить функцию знания с необходимой точностью невозможно – именно поэтому необходимо использовать аппроксимацию. Однако в расширенной версии теста (с 1200 тестовыми словами) неизвестная функция знания может быть измерена достаточно качественно. Такое измерение необходимо для валидации выбранного вида аппроксимирующей функции.
Результат трех респондентов, прошедших расширенную версию теста показан на Рис. 1. Каждый красный крест соответствуют одному тестовому слову (1 – если респондент отметил слово как знакомое, 0 – если как незнакомое). Видно, что для малых рангов (высокочастотных тестовых слов) плотность красных крестов на значении «1» высока – респонденты знают эти слова. По мере движения от малых рангов к большим (в сторону низкочастотных слов) красные кресты появляются на значении «0» все чаще – респонденты знают все меньше тестовых слов. Черные квадраты показывают усредненную вероятность знания тестовых слов (по 120 на квадрат). Синие кривые соответствуют аппроксимации тестовых данных функцией (1) . Визуально выбранная функция хорошо аппроксимирует полученные результаты для всех 7 респондентов.
Для количественной оценки качества аппроксимации были сопоставлены две оценки словарного запаса. Одна была получена интегрированием измеренной функции знания (черные квадраты на Рис. 1), другая – интегрированием аппроксимирующих функций. Результаты показаны в Табл. 2. Разница оценок оказалась не больше 6%, что может считаться хорошим результатом.
Табл. 2. Валидация выбора функции знания слов. Сравнение оценок словарного запаса, полученных через аппроксимацию (по формуле (2) ) и прямым интегрированием функции знания. Респонденты описаны в Табл. 1.
| Респондент | A | B | C | D | E | F | G |
|---|---|---|---|---|---|---|---|
| Оценка словарного запаса через аппроксимацию (по формулам (1) и (2) | 55600 | 67800 | 79800 | 86600 | 96000 | 97900 | 110100 |
| Оценка словарного запаса (интегрирование без аппроксимаций) | 58900 | 72200 | 82400 | 87300 | 97000 | 99000 | 110500 |
| Разница оценок | 5.6% | 6.1% | 3.2% | 0.8% | 1.1% | 1.1% | 0.4% |
Методика теста позволяет использовать любое количество тестовых слов. При этом, очевидно, что чем больше слов используется – тем точнее получается оценка. Однако не все тестовые слова дают одинаковый вклад в измерение. Например, для респондента с большим словарным запасом вероятность знания очень простых слов близка к единице, поэтому использование большого количества простых тестовых слов не увеличит точность теста. То же верно и наоборот – для респондента с маленьким словарным запасом вероятность знания очень сложных слов близка к нулю, то есть такому респонденту бессмысленно предъявлять сложные тестовые слова. Тест работает в два этапа. На первом этапе респонденту предъявляется 40 тестовых слов. По результатам этого этапа делается приблизительная оценка словарного запаса. Второй этап состоит из 80 слов, которые выбираются исходя из приблизительной оценки – слишком простые или сложные тестовые слова на этом этапе не присутствуют. Таким образом, тест в два этапа является адаптивным, так как тестовые слова второго этапа подбираются под каждого респондента индивидуально.
Для того чтобы проверить, действительно ли такой адаптивный подход более оптимален, чем неадаптивный (в один этап), было проведено следующее исследование. С помощью результатов расширенной версии теста (1200 слов), пройденного респондентом E (см. Табл. 1), были промоделированы различные варианты теста в два этапа. При этом варьировалось количество вопросов на первом и втором этапе. Результаты представлены на Рис. 2). Вертикальная ось показывает полное количество тестовых слов в двух этапах, горизонтальная – количество слов на втором этапе. Цвет кодирует точность теста (стандартное отклонение, полученное по 1000 реализаций теста со случайно выбранными тестовыми словами). Горизонтальная пунктирная линия соответствует фиксированному полному количеству тестовых слов (120). Самая левая точка на ней соответствует, по сути, тесту в один этап (120 тестовых слов на первом этапе, 0 – на втором), при движении по этой линии вправо количество тестовых слов на втором этапе увеличивается, на первом – уменьшается (сумма при этом остается постоянной). Точность теста вдоль этой линии непостоянна и имеет максимум в области около 80 тестовых слов на втором этапе. Действительно, для теста в один этап (120 слов) стандартное отклонение оценки словарного запаса – 4.8%, для теста в два этапа (40+80 слов) – 4.1%. Эту разницу можно интерпретировать и по-другому. Для того, чтобы обеспечить точность теста в два этапа с оптимальным количеством слов (40+80=120), потребовался бы тест в один этап, состоящий из 150 тестовых слов, что на целых 25% больше.
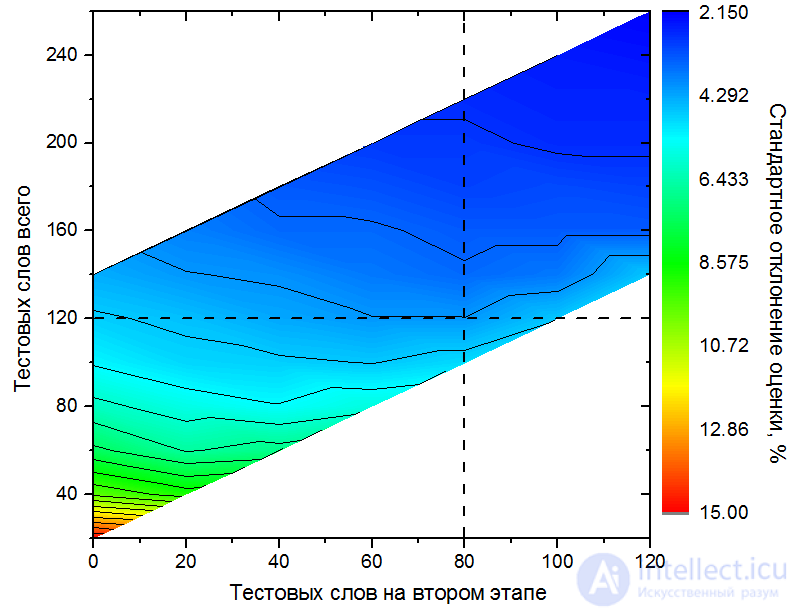
Рис. 2. Оптимизация количества тестовых слов на первом и втором этапе на примере результатов респондента E. Каждое значение стандартного отклонения оценки словарного запаса получено по 1000 прохождениям теста со случайным образом выбранными тестовыми словами. Сплошные линии отмечают контуры одинаковых значений стандартного отклонения.
Оценка точности теста проводилась с помощью следующей процедуры. Для каждого респондента, прошедшего расширенную версию теста, было промоделировано прохождение стандартной версии теста – 40 тестовых слов на первом этапе, 80 – на втором. Количество тестовых слов, используемых в стандартной версии теста, в десять раз меньше полного их количества в базе теста, поэтому каждое прохождение - уникальное. Даже если один и тот же человек будет проходить тест раз за разом, тестовые слова будут повторяться достаточно редко. Если бы такие прохождения приводили к значительно различным оценкам, это говорило бы либо о неработоспособности метода, либо о плохом выборе тестовых слов. Было промоделировано 5000 таких прохождений каждым респондентам, чтобы тестовые слова попали в тест в разных комбинациях. Полученные распределения оценок оказались нормальными (Гауссовыми), для них были рассчитаны средние значения и стандартные отклонения. Эти значения сравнивались с точными оценками словарного запаса каждого респондента, полученными по расширенной версии теста (1200 слов). Результаты сравнения приведены в Табл. 3.
Табл. 3. Сравнение точности оценок словарного запаса, полученных по расширенной версии теста (1200 слов), с оценками, полученными по стандартной версии теста (два этапа, 40+80 слов). Для подсчета средних и стандартных отклонений стандартный тест моделировался для каждого респондента 5000 раз.
Можно сделать следующие выводы. Первый этап стандартной версии теста – 40 слов – приводит к несмещенной оценке словарного запаса. Разница между средним значением этой оценки и точным значением оказалась в пределах 4%. Стандартное отклонение этой оценки велико – до 14%. Это значит, что, пройдя тест несколько раз, один и тот же респондент может получить значительно отличающиеся результаты. Другими словами, точность такой оценки невысока. Это легко понять, так как число используемых тестовых слов невелико. Оценка, полученная по двум этапам, также является несмещенной (разница с точной оценкой – в пределах 4%). Однако, стандартное отклонение этой оценки (оно же – точность теста) значительно лучше – в пределах 7%. Полученные величины стандартных отклонений как функция величины словарного запаса приведены на Рис. 3.
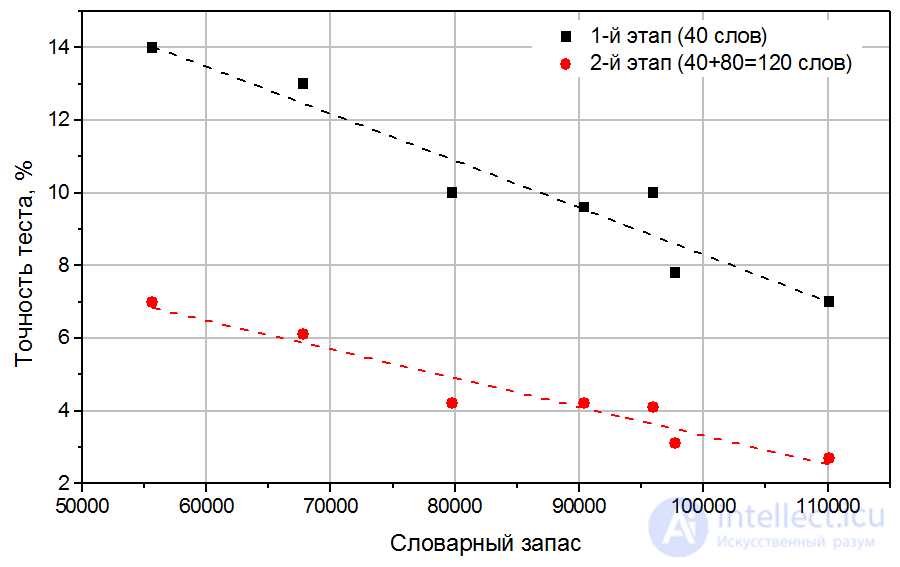
Рис. 3. Точность оценки (стандартное отклонение) словарного запаса, оцененное по 1-ому этапу теста (40 слов, красный), и по двум этапам (40+80 слов, синий). Каждая точка соответствует одному респонденту (A-E от меньших значений словарного запаса к большим, см. Табл. 3).
Абсолютная точность теста, как оказалась, лежит в пределах от 3000 до 4000 слов. Это означает, что с вероятностью в 67% оценка, полученная по тесту, будет лежать в пределах плюс-минус 4000 слов от реального значения словарного запаса; с вероятностью в 95% - в пределах плюс-минус 8000 слов.
Классическая теория тестов позволяет рассчитать коэффициент надежности теста – показатель, характеризующий как повторяемость, так и точность его результатов. Для на достаточно большой (19 тысяч) репрезентативной выборке респондентов, прошедших тест (и не отметивших ни одного слова-ловушки), был применен метод расщепления теста [Ким 2007]. Для каждого респондента был известен список из 120 тестовых слов, а также его ответы. Этот список был расщеплен на две равные половины, по которым независимо производилась оценка словарного запаса. Таким образом получилось 19 тысяч пар оценок. Коэффициент корреляции между этими оценками оказался равным 0.90. Так как оценка, полученная по половине (60) тестовых слов, имеет заниженную точность, коэффициент корреляции был скорректирован по методу Спирмена-Брауна. Итоговый коэффициент надежности оказался равным 0.95. Такое высокое значение надежности подтверждает то, что тест может использоваться для измерений словарного запаса как на групповом, так и на индивидуальном уровне.
Предварительные результаты были зафиксированы после прохождения интернет-теста 150 тысячами человек (все – носители русского языка). Из них 123 тысячи прошли тест аккуратно, не отметив ни одного слова-ловушки. Таким образом, было отсеяно 18% неаккуратных прохождений. На Рис. 4 показаны перцентили полученного распределения словарного запаса в зависимости от возраста респондентов. Например, самая нижняя кривая (10-ый перцентиль) для 20 лет дает 40 тысяч слов. Это означает, что 10% респондентов этого возраста имеют словарный запас ниже этого значения, а 90% — выше. Выделенная синим центральная кривая (медиана) соответствует такому словарному запасу, что половина респондентов соответствующего возраста показали результат хуже, и половина — лучше. Самая верхняя кривая — 90-ый перцентиль — отсекает результат, выше которого показали только 10% респондентов с максимальным словарным запасом.
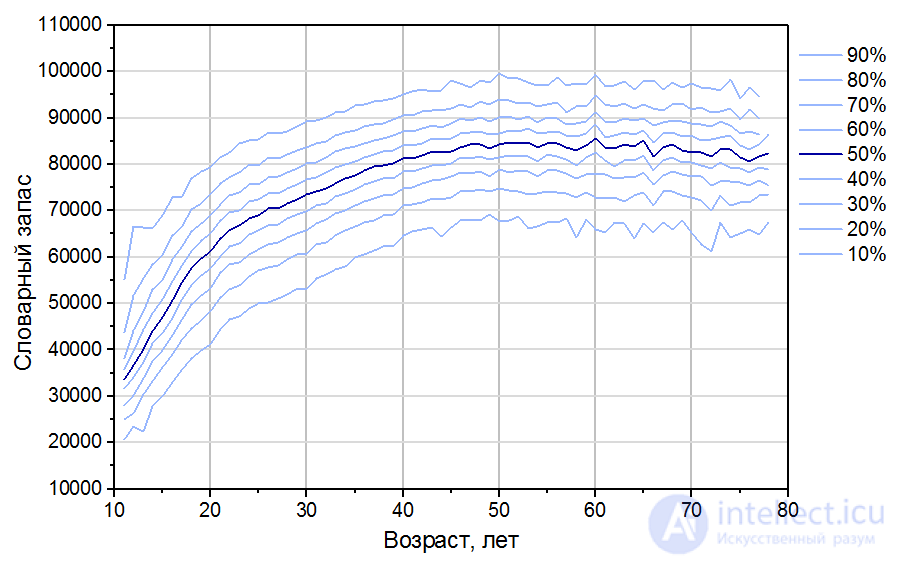
Рис. 4. Предварительные результаты теста (123 тысячи респондентов). Сплошные кривые соответствуют перцентилям от 10 до 90%, темно-синяя центральная кривая – медиана.
Полученные данные позволяют сделать следующие выводы.
Необходимо заметить, что полученные предварительные результаты не дают представления о словарном запасе среднестатистического носителя русского языка, так как выборка респондентов, прошедших интернет-тест, не является репрезентативной ни для России, ни для всего множества русскоговорящих людей.
Во-первых, уровень образования респондентов, прошедших тест, значительно выше общероссийского — 65% респондентов имеют высшее образование, тогда как в России таких только 23% (по данным всероссийской переписи населения 2010 года [Росстат ].
Во-вторых, интернет-тест нашли и прошли в основном активные пользователи интернета, что делает выборку специфичной (в основном для пожилых людей).
В-третьих, выборка респондентов была также значительно смещена самим желанием пройти тест на словарный запас. Логично предположить, что полученные по такой особенной выборке результаты словарного запаса должны быть несколько выше среднестатистических.
Для того, чтобы представить полученные данные в перспективе, был рассчитан процент покрытия Национального Корпуса Русского Языка различным количеством слов, отсортированных по частотности (см. Рис. 5). Из этих данных, например, видно, что 450 самых частотных слов составляют половину всех словоупотреблений корпуса, в то время как на остальную половину приходится уже 135+ тысяч слов. Процент покрытия позволяет оценить, сколько слов нужно знать, чтобы понимать некий усредненный текст. Как было экспериментально установлено, для понимания текста необходимо знание от 95 до 98% содержащихся в нем слов [Laufer and Ravenhorst-Kalovski 2010]. Это, по полученным данным, соответствует от 26 до 42 тысячам слов.
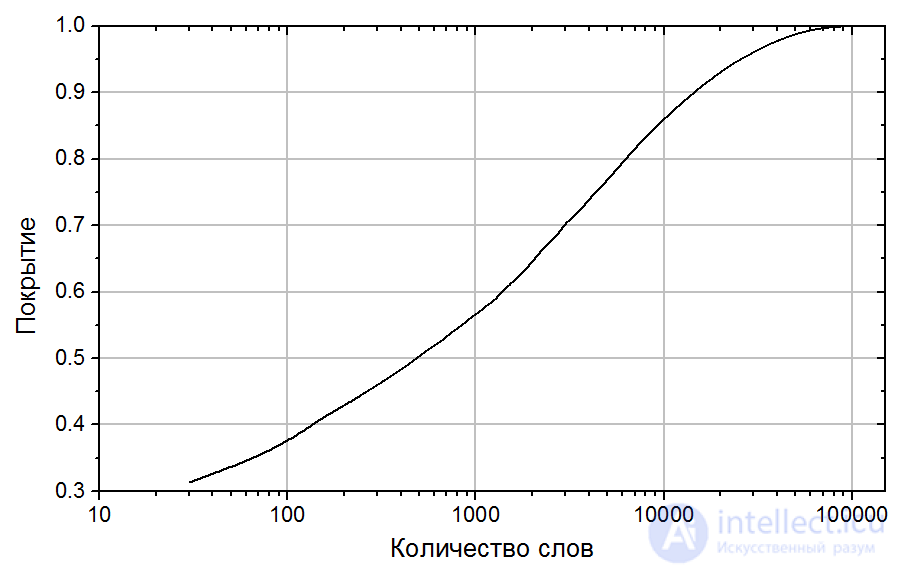
Рис. 5. Процент покрытия Национального Корпуса Русского Языка различным количеством слов, отсортированных по частотности.
Сколько слов в английском языке? Oxford English Dictionary содержит около 500 000 словарных статей, не учитывая специфические научные слова и выражения (которых насчитывается еще порядка 500 000). А как вы думаете, какой средний словарный запас иностранного языка дает вам средняя школа за время обучения? Правильный ответ – около 2500 слов. Мало ли этого набора? Тут уже надо исходить из ваших целей. Для общения с иностранцами на деловые темы – однозначно мало. Для чтения несложных текстов в интернете – более чем достаточно. Если быть точнее:
400–500 слов – активный словарный запас для владения языком на базовом (пороговом) уровне.
800–1000 слов – активный словарный запас для того, чтобы объясниться; или пассивный словарный запас для чтения на базовом уровне.
1500–2000 слов – активный словарный запас, которого вполне хватит для того, чтобы обеспечить повседневное общение в течение всего дня: или пассивный словарный запас, достаточный для уверенного чтения.
3000–4000 слов – в общем, достаточно для практически свободного чтения газет или литературы по специальности.
Около 8000 слов – обеспечивают полноценное общение для среднего европейца. Практически не нужно знать больше слов для того, чтобы свободно общаться как устно, так и письменно, а также читать литературу любого рода.
К этим данным пришел известный шведский полиглот Эрик Гуннемарк, основатель Международной ассоциации `Amici Linguarum` (`Друзья языков`). Более того, он составил набор минимального количества слов и выражений, которые необходимо знать, для порогового уровня владения языком, назвав их Минилекс и Минифраз.
Интересно, а какой средний уровень словарного запаса у рядового пользователя сети и у вас лично? Об этом расскажу дальше.

В результате исследования, проведенного совместной американо-бразильской группой, были выявлены интересные результаты. Например, на нижеприведенном графике показано, как увеличивается словарный запас с возрастом у носителей языка (в данном случае английского).
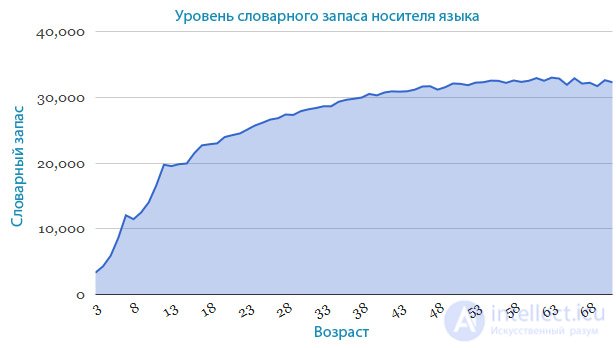
В опросе приняло участие 200.000 человек, что говорит о его высокой точности. Из графика видно, что между 3 и 16 годами наш словарный запас растет со скоростью 4 новых слова в день (если быть точнее, 3.8 слова). В возрасте от 16 до 50 лет темп роста сокращается до 1 в день (точнее 0.85). И наконец, после 50 словарный запас остается примерно на одном уровне.
А какой средний запас английских слов у пользователей интернета, для которых английский язык не является родным? На этот вопрос ответит диаграмма ниже.
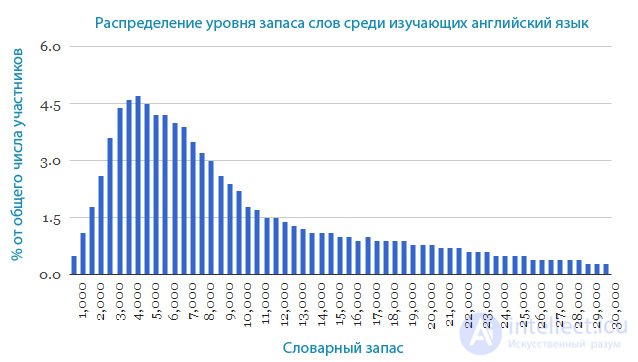
В ней не учтены пользователи с запасом слов ниже 1000. Как мы видим, большая часть пользователей, изучающих английский язык (4,7%), имеет личный словарный запас на уровне 4500 слов. Вы можете проверить уровень своих знаний всего за пару минут (ссылка в конце статьи) и сравнить его с данными показателями.
Давайте посмотрим на некоторые другие интересные выводы. На следующей диаграмме приведена активность учеников в классных занятиях (ответы на вопросы, общение) от уровня словарного запаса.
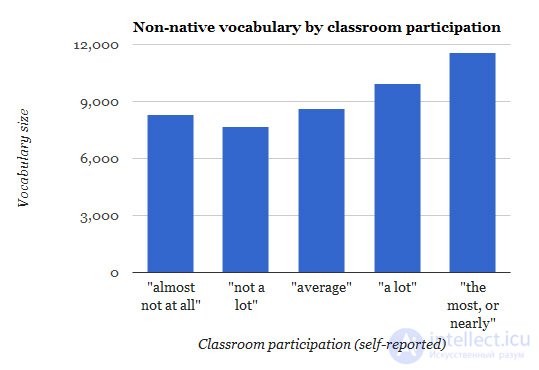
Как и ожидалось, ученики с наилучшим знанием слов участвуют в процессе урока наиболее активно, но это не является основополагающим фактором.
Следующая диаграмма отвечает на вопрос: как часто вы пользуетесь знаниями английского языка в жизни (при просмотре телевизора, путешествуя, слушая песни и т. д.)

Опять же с ростом словарного запаса учащиеся чаще начинают использовать язык в повседневной жизни, причем те, кто сталкивается с английским языком часто, имеет вдвое больший запас слов.
Если вы путешествовали в англоязычные страны, как долго вы там находились?

Из диаграммы мы видим, что люди с запасом от 7000 до 10 000 слов находятся за границей в общей сложности менее года. Каждый последующий год пребывания в англоязычной стране в среднем прибавляет к вашему первоначальному запасу 850 слов, что соответствует 2,35 слову в день (в сравнении с американским подростком, чей запас слов увеличивается на 0,85 слова в день).
• Занимаетесь регулярно. Лучше понемногу ежедневно, чем раз в неделю несколько часов подряд.
• Носите с собой распечатанные карточки слов, либо пользуйтесь соответствующими мобильными приложениями.
• Читаете как можно больше, даже если плохо воспринимается текст (об этом методе рекомендую прочитать книгу Николая Замяткина, который советует учить читать тексты без использования словаря).
• Учите как можно больше наизусть.
• Наклейте стикеры на различные предметы в комнате с английским значением и переводом.
• Регулярно повторяйте слова, желательно проговаривая их вслух. Даже русские слова забываются, если их долго не повторять и не использовать.
• Для трудно запоминаемых слов используйте ассоциации. Чем ярче образ, создаваемый ассоциацией, тем лучше запомниться слово.
• Язык — крепость, и штурмовать ее надо со всех сторон и всеми средствами, поэтому любая практика — основа успеха, поэтому используйте малейшую возможность, чтобы говорить, читать, писать на изучаемом языке.
• Не бойтесь ошибок. На них учатся! Излишняя скромность здесь не помогает, а некоторая самоуверенность не помешает.
• Используйте время, которое обычно безнадежно пропадает — поездки в городском транспорте, ожидание приема и т. д.
В заключение будут рассмотрены преимущества и недостатки теста, а также направления его дальнейшего улучшения.
К преимуществам теста можно отнести следующее.
Во-первых, тест очень быстр - прохождение занимает около 5 минут.
Во-вторых, тест является адаптивным (за счет тестирования в два этапа) и подходит для проверки широкого диапазона словарных запасов.
В-третьих, тест полностью автоматизирован и не требует ручной обработки.
Недостатки теста являются следствием его быстроты. Формат опроса «знаю/не знаю», позволяющий получить ответы на большое количество тестовых вопросов и делающий тест быстрым и точным, подразумевает некоторую вольность трактовки «знания» каждым респондентом. Даже если респондент пометил тестовое слово как знакомое, это не значит, что он владеет всеми аспектами знания (стилистическими, морфологическими, смысловыми и прочее) этого слова. Поэтому тест измеряет размер, но не качество словарного запаса. Тест также не может быть использован в тех случаях, когда респонденту выгодно получить высокий результат, так как контроль честности прохождения довольно прост и не позволит надежно выявить респондентов, целенаправленно пытающихся повысить свои результаты.
Дальнейшее улучшение теста возможно по двум направлением. Во-первых, его надежность может быть повышена добавлением заданий с множественными вариантами ответа. Это позволит лучше контролировать, действительно ли респонденты понимают значения тестовых слов, которые они отмечают как знакомые. Во-вторых, математический аппарат теста может быть изменен в соответствии с современной теорией тестов (Item Response Theory [Аванесов 2005]). Это позволит выявить наиболее «качественные» тестовые слова, использование которых приведет к сокращению длины теста при сохранении его точности.
Использование IRT в тестах на словарный запас имеет еще одно важное следствие. Результаты таких тестов сильно зависят от того, каким образом разработчики решили вопрос построения словарных семей (то есть какие слова были посчитаны за самостоятельные, а какие – за производные). Это приводит к тому, что сравнивать между собой результаты разных тестов сложно – один и тот же респондент по разным тестам может получить значительно отличающиеся результаты. Если же тесты выполнены по методологии IRT, их результаты должны быть одинаковы, пусть и выраженные в несколько абстрактных баллах (логитах), что может дать возможность сравнивать результаты разных тестов.
В заключение, эта статья об словарный запас подчеркивает важность того что вы тут, расширяете ваше сознание, знания, навыки и умения. Надеюсь, что теперь ты понял что такое словарный запас и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Создание электронных словарей, тезаурусов, онтологий
Часть 1 Словарный запас иностранного и родного языка
Часть 2 Немного советов при изучении слов - Словарный запас иностранного и
Ответы на вопросы для самопроверки пишите в комментариях, мы проверим, или же задавайте свой вопрос по данной теме.
Комментарии
Оставить комментарий
Создание электронных словарей, тезаурусов, онтологий
Термины: Создание электронных словарей, тезаурусов, онтологий