Лекция
Привет, Вы узнаете о том , что такое регулярные выражения в mysql, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое регулярные выражения в mysql, rlike, regexp mysql, экранирование спецсимволов mysql , настоятельно рекомендую прочитать все из категории MySql (Maria DB).
СУБД MySQL имеет различные инструменты для осуществления поиска, среди которых оператор LIKE, осуществляющий простейшие операции поиска, оператор RLIKE, предоставляющий возможности поиска по регулярным выражениям.
Регулярные выражения - это специальные шаблоны для поиска подстроки в тексте. С их помощью можно решить одной строчкой такие задачи: «проверить, содержит ли строка цифры», «найти в тексте все адреса email», «заменить несколько идущих подряд знаков вопроса на один».



Оператор LIKE предназначен для сравнения строк с использованием простейших регулярных выражений. Оператор часто используется в конструкции WHERE и возвращает 1 или 0.
Сравнение строк не зависит от регистра, если не используется ключевое слово BINARY, означающее что строку следует рассматривать как двоичную последовательность.
Вместе с оператором LIKE возможно использование специальных символов:
"%" — Соответствует любому количеству символов и их отсутствию тоже.
"_" — Соответствует одному символу.
Поиск символов "%" и "_" осуществляется при помощи конструкций "\%" и "\_".
Пример использования:
select name, family from personal where name like 'A%В_'
//Этим скриптом мы выберем все записи поле name у которых
//начинается с буквы А и предпоследняя буква этого поля В.
Оператор можно использовать с отрицанием: NOT LIKE.
В этом случае в выборку попадут записи не удовлетворяющие заданным условиям.
Оператор RLIKE
Оператор RLIKE (а также синоним REGEXP)производит поиск в соответствии с регулярными выражениями, что позволяет задать более гибкие условия поиска, однако при этом данный оператор работает медленнее нежели оператор LIKE.
Существует несколько диалектов регулярных выражений. В СУБД MySQL реализация ориентирована на соответствие стандарту POSIX.
Регулярное выражение это шаблон применяемый к заданному тексту с лева на право. Например регулярное выражение содержащее обычный текст, например 'монитор', соответствует строке содержащей такую подстроку например: 'мониторинг', 'мониторы', 'большие мониторы', и т.п.
Пример:
select NAME from market where NAME RLIKE 'кекс'
Результат работы:
КЕКС К ЧАЮ В АССОРТ. 225ГР.
СУХАЯ СМЕСЬ ДЛЯ КЕКСА АТЛАНТА
МИНИ КЕКСЫ 6ШТ
Из таблицы market_cards будут выбраны все записи где поле NAME содержит слово 'кекс' при этом неважно в каком месте строки это слово (или точнее сказать сочетание символов) расположено.
Чтобы привязать искомое выражение к началу строки либо к концу используются символы:
'^' — привязывает к началу строки.
'$' — привязывает к концу строки.
Пример:
1) select NAME from market_cards where NAME RLIKE '^кекс'
2) select NAME from market_cards where NAME RLIKE 'кекс$'
3) select NAME from market_cards where NAME RLIKE '^кекс$'
Результат работы:
Первый запрос вернйт нам записи типа:
КЕКСЫ МИНИ КОВИС 200ГР.
КЕКС К ЧАЮ ХАРРИС 225ГР.
КЕКСЫ 7 ДНЕЙ МАГДАЛЕН.
Второй и третий запросы ничего не вернут, поскольку не найдут записей оканчивающихся на слово 'кекс'
Гораздо чаще необходимо привязываться ни к концу или началу строки, а к концу или началу слова.
Такую задачу реализуют последовательности:
[[:<:]] — Начало слова.
[[:>:]] — Конец слова.
Пример:
select NAME from market where NAME RLIKE '[[:<:]]медведь[[:>:]]'
Результат:
ИГРУШКА МЕДВЕДЬ МИТЕНЬКА РЮКЗАК
ИГРУШКА МЕДВЕДЬ МИТЬКА
МЕДВЕДЬ КОРИЧНЕВЫЙ
ИГРУШКА МЕДВЕДЬ МИТЬКА
Еще один специальный символ:
'|' — Аналогичен по смыслу (или), например 'мама|мать' — будут выбраны все строки включающие и 'мама' и 'мать'.
В регулярном выражении возможно использование других спецсимволов и классов символов:
[abc] — будут выбраны записи с любым из символов a,b,c.
[0-9] — любая из цифр. (аналогичен по смыслу [0123456789]).
[а-я] — любая из букв от а до я.
[а-я0-9] — любая буква русского алфавита либо цифра.
[^0-9] — означает любое значение кроме цифры. (в подобных случаях '^' — своего рода отрицание).
Для определения специальных последовательностей внутри строк:
'\t' — символ табуляции.
'\f' — конец файла.
'\n' — символ перевода строки.
'\r' — символ возврата каретки.
'\\' — символ обратного слэша \.
Кроме этого действуют классы символов POSIX регулярных выражений:
[:alnum:] — алфавитно цифровые символы.
[:alpha:] — символы алфавита.
[:blank:] — символы пробела и табуляции.
[:cntrl:] — управляющие символы.
[:digit:] — десятичные цифры (0-9).
[:graph:] — графические (видимые) символы.
[:lower:] — символы алфавита в нижнем регистре.
[:print:] — графические или невидимые символы.
[:punct:] — знаки препинания.
[:space:] — символы пробела, табуляции, новой строки или возврата каретки.
[:upper:] — символы алфавита в верхнем регистре.
[:xdigit:] — шестнадцатеричные цифры.
(Алфавитные символы — могут быть как русскими так и английскими.)
Выражения в квадратных скобках соответствуют только одному символу и часто употребляются с квантификаторами, которые следуют сразу за символом и изменяют количествое его вхождений в строку.
? — символ либо входит в строку один раз, либо вообще в нее не входит.
* — любое число вхождений символа в строку, в том числе и ноль.
+ — одно или более вхождений символа в строку.
Оператор RLIKE можно использовать с отрицанием NOT RLIKE — в этом случае результатом его работы будет выборка строк не соответствующих заданным параметрам.
SELECT * FROM Table WHERE title REGEXP "dog|cat|mouse";
эта конструкция найдет все или
не очень хорошее рещение через конкатенацию and:
SELECT * FROM Table
WHERE title REGEXP "dog" AND title REGEXP "cat" AND title REGEXP "mouse"
Регулярное выражение будет выглядеть следующим образом:
SELECT * FROM Table
WHERE title REGEXP "(dog.*cat.*mouse)|(dog.*mouse.*cat)|(mouse.*dog.*cat)
|(mouse.*cat.*dog)|(cat.*dog.*mouse)|(cat.*mouse.*dog)"
|
|
|
[.characters.]
выражение в скобках (написанное с использованием [and]) соответствует упорядоченной последовательности символов . Об этом говорит сайт https://intellect.icu . Символы - это либо одиночный символ, либо символьное имя типа новой строки. В следующей таблице перечислены допустимые имена символов.
В следующей таблице указаны допустимые имена символов и соответствующие им символы. Для символов, заданных как числовые значения, значения представлены в восьмеричном.
| Name | Character | Name | Character |
|---|---|---|---|
NUL |
0 |
SOH |
001 |
STX |
002 |
ETX |
003 |
EOT |
004 |
ENQ |
005 |
ACK |
006 |
BEL |
007 |
alert |
007 |
BS |
010 |
backspace |
'\b' |
HT |
011 |
tab |
'\t' |
LF |
012 |
newline |
'\n' |
VT |
013 |
vertical-tab |
'\v' |
FF |
014 |
form-feed |
'\f' |
CR |
015 |
carriage-return |
'\r' |
SO |
016 |
SI |
017 |
DLE |
020 |
DC1 |
021 |
DC2 |
022 |
DC3 |
023 |
DC4 |
024 |
NAK |
025 |
SYN |
026 |
ETB |
027 |
CAN |
030 |
EM |
031 |
SUB |
032 |
ESC |
033 |
IS4 |
034 |
FS |
034 |
IS3 |
035 |
GS |
035 |
IS2 |
036 |
RS |
036 |
IS1 |
037 |
US |
037 |
space |
' ' |
exclamation-mark |
'!' |
quotation-mark |
'"' |
number-sign |
'#' |
dollar-sign |
'$' |
percent-sign |
'%' |
ampersand |
'&' |
apostrophe |
'\'' |
left-parenthesis |
'(' |
right-parenthesis |
')' |
asterisk |
'*' |
plus-sign |
'+' |
comma |
',' |
hyphen |
'-' |
hyphen-minus |
'-' |
period |
'.' |
full-stop |
'.' |
slash |
'/' |
solidus |
'/' |
zero |
'0' |
one |
'1' |
two |
'2' |
three |
'3' |
four |
'4' |
five |
'5' |
six |
'6' |
seven |
'7' |
eight |
'8' |
nine |
'9' |
colon |
':' |
semicolon |
';' |
less-than-sign |
'<' |
equals-sign |
'=' |
greater-than-sign |
'>' |
question-mark |
'?' |
commercial-at |
'@' |
left-square-bracket |
'[' |
backslash |
'\\' |
reverse-solidus |
'\\' |
right-square-bracket |
']' |
circumflex |
'^' |
circumflex-accent |
'^' |
underscore |
'_' |
low-line |
'_' |
grave-accent |
'`' |
left-brace |
'{' |
left-curly-bracket |
'{' |
vertical-line |
'|' |
right-brace |
'}' |
right-curly-bracket |
'}' |
tilde |
'~' |
DEL |
177 |
SELECT '~' REGEXP '[[.~.]]';-> 1SELECT '~' REGEXP '[[.tilde.]]';-> 1
напрмер чтобы найти программист "C++" можно использовать
select * from `job` where LCASE(title RLIKE "[[:<:]]c[.+.][.+.
[=character_class=]
В выражении в скобках (написанном с использованием [and]), [= character_class =] представляет класс эквивалентности. Он соответствует всем символам с одинаковым значением сортировки, включая и самого себя. Например, если o и (+) являются членами класса эквивалентности, все [[= o =]], [[= (+) =]] и [o (+)] являются синонимами. Класс эквивалентности не может использоваться в качестве конечной точки диапазона.
[:character_class:]
В выражении скобки (написанном с использованием [и]), [: character_class:] представляет класс символов, который соответствует всем символам, принадлежащим этому классу. В следующей таблице перечислены стандартные имена классов. Эти имена обозначают классы символов, определенные на странице руководства ctype (3). Конкретный язык может содержать другие имена классов. Класс символов не может использоваться в качестве конечной точки диапазона.
| Character Class Name | Meaning |
|---|---|
alnum |
Alphanumeric characters |
alpha |
Alphabetic characters |
blank |
Whitespace characters |
cntrl |
Control characters |
digit |
Digit characters |
graph |
Graphic characters |
lower |
Lowercase alphabetic characters |
print |
Graphic or space characters |
punct |
Punctuation characters |
space |
Space, tab, newline, and carriage return |
upper |
Uppercase alphabetic characters |
xdigit |
Hexadecimal digit characters |
| Character Class Name | Meaning |
|---|
SELECT 'intellect' REGEXP '[[:alnum:]]+';-> 1SELECT '!!' REGEXP '[[:alnum:]]+';-> 0
[[:<:]], [[:>:]]
Эти маркеры обозначают границы слов. Они соответствуют началу и концу слов, соответственно. Слово - последовательность символов слова, которым не предшествуют или не сопровождаются символами слов. Символ слова является алфавитно-цифровым символом в классе alnum или символом подчеркивания (_).
SELECT 'a word a' REGEXP '[[:<:]]word[[:>:]]';-> 1SELECT 'a xword a' REGEXP '[[:<:]]word[[:>:]]';-> 0
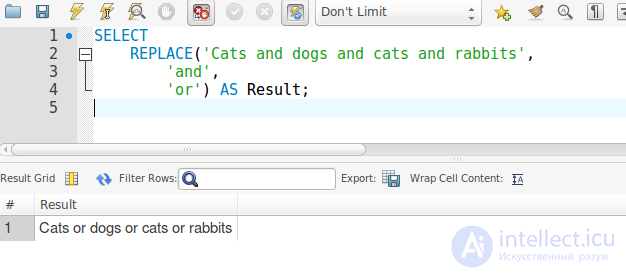
Функция MySQL REPLACE()позволяет заменить все вхождения подстроки другой строкой. Это позволяет вам делать такие вещи, как заменять все вхождения одного слова другим словом и т. Д.
В этой статье демонстрируется его использование.
Вот как выглядит синтаксис:
ЗАМЕНИТЬ (str, from_str, to_str)
Где strстрока, содержащая подстроку / s. from_str- это подстрока, которую вы хотите заменить другой строкой. И to_strэто новая строка, которая заменит старую строку.
Вот простой пример:
В этом случае мы просто меняем слово andна слово or. Поскольку это слово было три раза, все три были заменены.
Важно помнить, что REPLACE() функция чувствительна к регистру
Представленные результаты и исследования подтверждают, что применение искусственного интеллекта в области регулярные выражения в mysql имеет потенциал для революции в различных связанных с данной темой сферах. Надеюсь, что теперь ты понял что такое регулярные выражения в mysql, rlike, regexp mysql, экранирование спецсимволов mysql и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории MySql (Maria DB)
если делать поиск по словам в mysql 8.0 то ошибка почему?
FROM feedback
WHERE title RLIKE ' [[:<:]] iолрл'
Error Code: 3685. Illegal argument to a regular expression.
ICU для [[:<:]]начальная_часть_слова[[:>:]] нет(тоесть нет поддерки уникода). Для ICU вы можете использовать \ b или \\b для соответствия границ слов; удвоить обратную косую черту, потому что MySQL интерпретирует его как escape-символ в строках.В MySQL реализована поддержка регулярных выражений с использованием International Components for Unicode (ICU), которая обеспечивает полную поддержку Unicode и является многобайтовой безопасностью. (До MySQL 8.0.4 MySQL использовала реализацию регулярных выражений Генри Спенсера, которая работает побайтово и не является многобайтовой безопасностью.
используйте так REGEXP_LIKE(title, "\\biолрл" )
Комментарии
Оставить комментарий
Базы данных - MySql (Maria DB)
Термины: Базы данных - MySql (Maria DB)