Лекция
Привет, Вы узнаете о том , что такое mapreduce в mongodb, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое mapreduce в mongodb , настоятельно рекомендую прочитать все из категории Базы данных MongoDB.
MapReduce - это подход к обработке данных, который имеет два серьезных преимущества по сравнению с традиционными решениями. Первое и самое главное преимущество - это производительность. Теоретически MapReduce может быть распараллелен, что позволяет обрабатывать огромные массивы данных на множестве ядер/процессоров/машин. Как уже упоминалось, это пока не является преимуществом MongoDB. Вторым преимуществом MapReduce является возможность описывать обработку данных нормальным кодом. По сравнению с тем, что можно сделать с помощью SQL, возможности кода внутри MapReduce намного богаче и позволяют расширить рамки возможного даже без использования специализированных решений.
режде всего, еще раз поясним смысл основополагающих функций вычислительной модели :
Для обработки данных в соответствии с вычислительной моделью MapReduce следует определить обе эти функции, указать имена входных и выходных файлов, а также параметры обработки.
Сама вычислительная модель состоит из 3-хшаговой комбинации вышеприведенных функций :
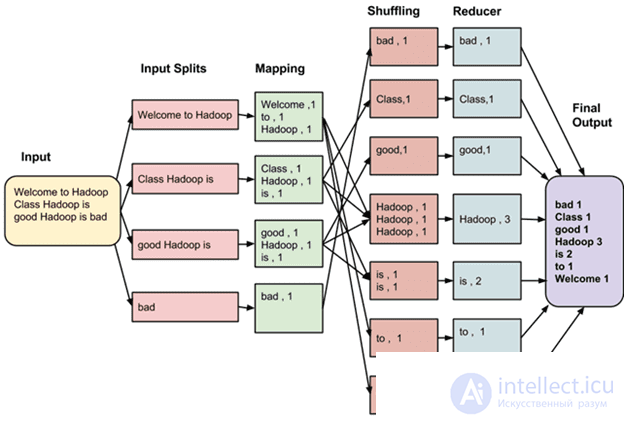
Принцип работы MapReduce
MapReduce - это стремительно приобретающий популярность шаблон, который уже можно использовать почти везде; реализации уже имеются в C#, Ruby, Java, Python. Должен предупредить, что на первый взгляд он может показаться очень непривычным и сложным. Не расстраивайтесь, не торопитесь и поэкспериментируйте с ним самостоятельно. Это стоит того - не важно, используете вы MongoDB или нет.
MapReduce - процесс двухступенчатый. Сначала делается map (отображение), затем - reduce (свертка). На этапе отображения входные документы трансформируются (map) и порождают (emit) пары ключ=>значение (как ключ, так и значение могут быть составными). При свертке (reduce) на входе получается ключ и массив значений, порожденных для этого ключа, а на выходе получается финальный результат. Посмотрим на оба этапа и на их выходные данные.
В нашем примере мы будем генерировать отчет по дневному количеству хитов для какого- либо ресурса (например, веб-страницы). Это hello world для MapReduce. Для наших задач мы воспользуемся коллекцией hits с двумя полями: resource и date. Желаемый результат - это отчет в разрезе ресурса, года, месяца, дня и количества.
Пусть в hits лежат следующие данные:
resource date index Jan 20 2010 4:30 index Jan 20 2010 5:30 about Jan 20 2010 6:00 index Jan 20 2010 7:00 about Jan 21 2010 8:00 about Jan 21 2010 8:30 index Jan 21 2010 8:30 about Jan 21 2010 9:00 index Jan 21 2010 9:30 index Jan 22 2010 5:00
На выходе мы хотим следующий результат:
resource year month day count index 2010 1 20 3 about 2010 1 20 1 about 2010 1 21 3 index 2010 1 21 2 index 2010 1 22 1
(Прелесть данного подхода заключается в хранении результатов; отчеты генерируются быстро и рост данных контролируется - для одного ресурса в день будет добавляться максимум один документ.)
Давайте теперь сосредоточимся на понимании концепции. Об этом говорит сайт https://intellect.icu . В конце главы в качестве примера будут приведены данные и код.
Первым делом рассмотрим функцию отображения. Задача функции отображения - породить значения, которые в дальнейшем будут использоваться при свертке. Порождать значения можно ноль или более раз. В нашем случае - как чаще всего бывает - это всегда будет делаться один раз. Представьте, что map в цикле перебирает каждый документ в коллекции hits. Для каждого документа мы должны породить ключ, состоящий из ресурса, года, месяца и дня, и примитивное значение - единицу:
function() {
var key = {
resource: this.resource,
year: this.date.getFullYear(),
month: this.date.getMonth(),
day: this.date.getDate()
};
emit(key, {count: 1});
}
this ссылается на текущий рассматриваемый документ. Надеюсь, результирующие данные прояснят для вас картину происходящего. При использовании наших тестовых данных, в результате получим:
{resource: 'index', year: 2010, month: 0, day: 20} => [{count: 1}, {count: 1}, {count:1}]
{resource: 'about', year: 2010, month: 0, day: 20} => [{count: 1}]
{resource: 'about', year: 2010, month: 0, day: 21} => [{count: 1}, {count: 1}, {count:1}]
{resource: 'index', year: 2010, month: 0, day: 21} => [{count: 1}, {count: 1}]
{resource: 'index', year: 2010, month: 0, day: 22} => [{count: 1}]
Понимание этого промежуточного этапа дает ключ к пониманию MapReduce. Порожденные данные собираются в массивы по одинаковому ключу. .NET и Java разработчики могут рассматривать это как тип IDictionary>(.NET) или HashMap (Java).
Давайте изменим нашу map-функцию несколько надуманным способом:
function() {
var key = {resource: this.resource, year: this.date.getFullYear(), month: this.date.getMonth(), day: this.date.getDate()};
if (this.resource == 'index' && this.date.getHours() == 4) {
emit(key, {count: 5});
} else { emit(key, {count: 1}); }
}
Первый промежуточный результат теперь изменится на:
{resource: 'index', year: 2010, month: 0, day: 20} => [{count: 5}, {count: 1}, {count:1}]
Обратите внимание, как каждый emit порождает новое значение, которое группируется по ключу.
Reduce-функция берет каждое из этих промежуточных значений и выдает конечный результат. Вот так будет выглядеть наша функция:
function(key, values) {
var sum = 0;
values.forEach(function(value) {
sum += value['count'];
}); return {count: sum};
};
На выходе получим:
{resource: 'index', year: 2010, month: 0, day: 20} => {count: 3}
{resource: 'about', year: 2010, month: 0, day: 20} => {count: 1}
{resource: 'about', year: 2010, month: 0, day: 21} => {count: 3}
{resource: 'index', year: 2010, month: 0, day: 21} => {count: 2}
{resource: 'index', year: 2010, month: 0, day: 22} => {count: 1}
Технически в MongoDB результат выглядит так:
_id: {resource: 'home', year: 2010, month: 0, day: 20}, value: {count: 3}
Это и есть наш конечный результат.
Если вы были внимательны, вы должны были спросить себя: почему мы просто не написали sum = values.length? Это было бы эффективным подходом, если бы мы суммировали массив единиц. На деле reduce не всегда вызывается с полным и совершенным набором промежуточных данных. Например вместо того, чтобы быть вызванным с:
{resource: 'home', year: 2010, month: 0, day: 20} => [{count: 1}, {count: 1}, {count:1}]
Reduce может быть вызван с:
{resource: 'home', year: 2010, month: 0, day: 20} => [{count: 1}, {count: 1}]
{resource: 'home', year: 2010, month: 0, day: 20} => [{count: 2}, {count: 1}]
Конечный результат тот же самый (3), однако он получается немного разными путями. Таким образом, reduce должен всегда быть идемпотентным. То есть, вызывая reduce несколько раз, мы должны получать такой же результат, что и вызывая его один раз.
Мы не станем рассматривать этого здесь, однако распространена практика последовательных сверток, когда требуется выполнить сложный анализ.
С MongoDB мы вызываем у коллекции команду mapReduce. mapReduce принимает функцию map, функцию reduce и директивы для результата. В консоли мы можем создавать и передавать JavaScript функции. Из большинства библиотек вы будете передавать строковое представление функции (которое может выглядеть немного ужасно). Сперва давайте создадим набор данных:
db.hits.insert({resource: 'index', date: new Date(2010, 0, 20, 4, 30)});
db.hits.insert({resource: 'index', date: new Date(2010, 0, 20, 5, 30)});
db.hits.insert({resource: 'about', date: new Date(2010, 0, 20, 6, 0)});
db.hits.insert({resource: 'index', date: new Date(2010, 0, 20, 7, 0)});
db.hits.insert({resource: 'about', date: new Date(2010, 0, 21, 8, 0)});
db.hits.insert({resource: 'about', date: new Date(2010, 0, 21, 8, 30)});
db.hits.insert({resource: 'index', date: new Date(2010, 0, 21, 8, 30)});
db.hits.insert({resource: 'about', date: new Date(2010, 0, 21, 9, 0)});
db.hits.insert({resource: 'index', date: new Date(2010, 0, 21, 9, 30)});
db.hits.insert({resource: 'index', date: new Date(2010, 0, 22, 5, 0)});
Теперь можно создать map и reduce функции (консоль MongoDB позволяет вводить многострочные конструкции):
var map = function() {
var key = {resource: this.resource, year: this.date.getFullYear(), month: this.date.getMonth(), day: this.date.getDate()};
emit(key, {count: 1});
};
var reduce = function(key, values) {
var sum = 0;
values.forEach(function(value) {
sum += value['count'];
});
return {count: sum};
};
Мы выполним команду mapReduce над коллекцией hits следующим образом:
db.hits.mapReduce(map, reduce, {out: {inline:1}})
Если вы выполните код, приведенный выше, вы увидите ожидаемый результат. Установив out в inline мы указываем, что mapReduce должен непосредственно вернуть результат в консоль. В данный момент размер результата ограничен 16 мегабайтами. Вместо этого мы могли бы написать {out: 'hit_stats'}, и результат был бы сохранен в коллекцию hit_stats:
db.hits.mapReduce(map, reduce, {out: 'hit_stats'});
db.hit_stats.find();
В таком случае все существовавшие данные из коллекции hit_stats были бы вначале удалены. Если бы мы написали {out: {merge: 'hit_stats'}}, существующие значения по соответствующим ключам были бы заменены на новые, а другие были бы вставлены. И наконец, можно в out использовать reduce функцию - для более сложных случаев.
Третий параметр принимает дополнительные значения - например, можно сортировать, фильтровать или ограничивать анализируемые данные. Мы также можем передать метод finalize, который применится к результату возвращенному этапом reduce.
Это первая глава, в которой мы осветили совершенно новую для вас тему. Если вы испытываете неудобства, всегда можно обратиться к другим стредствам агрегирования и более простым сценариям. Впрочем, MapReduce является одной из наиболее важных функций MongoDB. Чтобы научиться писать map и reduce функции, необходимо четко представлять и понимать, как выглядят ваши данные и как они преобразовываются по пути через map и reduce.
Исследование, описанное в статье про mapreduce в mongodb, подчеркивает ее значимость в современном мире. Надеюсь, что теперь ты понял что такое mapreduce в mongodb и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Базы данных MongoDB

Комментарии