Лекция
Привет, Вы узнаете о том , что такое Инструмент командной строки FST, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое Инструмент командной строки FST , настоятельно рекомендую прочитать все из категории Индексирование большого набора ключей с помощью конечных автоматов.
Инструмент командной строки FST
Я создал инструмент командной строки FST как способ легко поиграть с данными и демонстрацию того, как использовать базовую библиотеку. Я не намерен делать это само по себе особенно полезным, но в этом сообщении в блоге он подойдет как способ проведения экспериментов с реальными данными.
В этом разделе я сделаю очень краткий обзор команды, а затем сразу перейду к экспериментам с реальными данными.
Если вы не хотите играть с этим инструментом, вам не обязательно его загружать. А именно, в этом разделе я обычно показываю команды, которые я выполняю, вместе с их результатами, когда это возможно.
В настоящее время единственный способ получить команду - скомпилировать ее из исходного кода. Для этого вам сначала нужно установить Rust и Cargo . (Текущая стабильная версия Rust будет работать. В дистрибутив версии входят как Rust, так и Cargo.)
После установки Rust клонируйте fstрепозиторий и соберите:
$ git clone git://github.com/BurntSushi/fst $ cd fst $ cargo build --release --manifest-path ./fst-bin/Cargo.toml
На моей довольно мощной системе компиляция занимает чуть меньше минуты.
После завершения компиляции fstдвоичный файл будет расположен по адресу ./fst-bin/target/release/fst.
Инструмент fstкомандной строки имеет несколько команд. Некоторые из них служат чисто диагностической роли (например, «Я хочу посмотреть на конкретное состояние в лежащем в основе преобразователе»), тогда как другие более утилитарны. В этой статье мы остановимся на последнем.
Вот команды:
setИ mapкоманды имеют решающее значение, поскольку они обеспечивают средства для создания Таблицы FST из простых данных.
Начнем с простого примера, который мы можем легко визуализировать. Рассмотрим карту от аббревиатуры месяца до его числового положения в григорианском календаре. Наши необработанные данные - это простой файл CSV:
jan,1 feb,2 mar,3 apr,4 may,5 jun,6 jul,7 aug,8 sep,9 oct,10 nov,11 dec,12
Мы можем создать упорядоченную карту из этих данных с помощью fst mapкоманды:
$ fst map months months.fst
Если наши данные уже были отсортированы, мы могли бы передать --sortedфлаг:
$ fst map --sorted months months.fst
--sortedФлаг указывает fstкоманду , что он может построить FST в потоковом режиме, что очень быстро. Без --sortedфлага он должен сначала отсортировать данные.
Если мы хотим визуализировать базовый преобразователь, это легко, если вы graphvizустановили (что предоставляет dotкоманду, используемую ниже):
$ fst dot months.fst | dot -Tpng > months.png $ $IMAGE_VIEWER months.png
И вы должны увидеть что-то вроде этого:
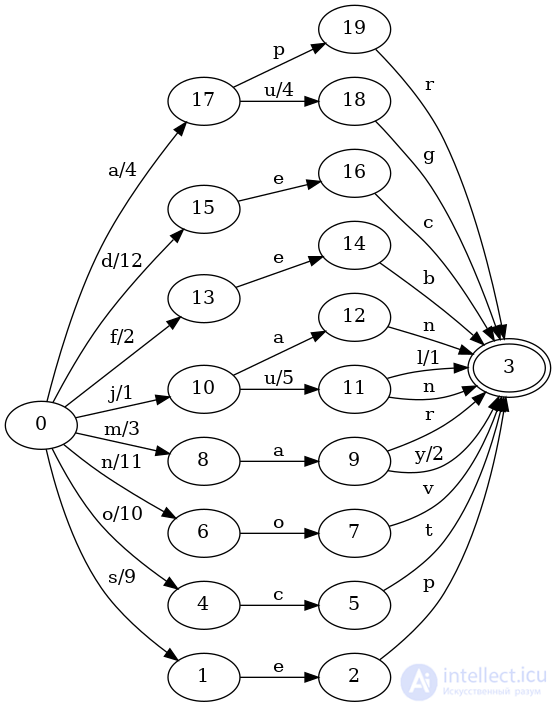
Поскольку набор данных невелик, поиск по нему не так интересен, но давайте все же попробуем несколько запросов. Перечислить их все легко с помощью fst rangeкоманды:
$ fst range months.fst apr aug dec feb jan jul jun mar may nov oct sep
Передача --outputsфлага также показывает значения:
$ fst range months.fst apr,4 aug,8 dec,12 ...
Как следует из названия команды, мы также можем ограничить наши результаты определенным диапазоном:
$ fst range months.fst -s j -e o jan jul jun mar may nov
Или даже нечеткий поиск, ища все месяцы на расстоянии Левенштейна 1с jun:
$ fst fuzzy months.fst jun jan jul jun
У большинства этих команд есть несколько дополнительных опций. Вы можете проверить их, запустив fst CMD --help.
Наконец, мы собираемся быстро взглянуть на то, каково использовать конечные автоматы в качестве структур данных для реальных данных.
Словарь
С чего еще нам начать? Большинство пользователей систем на базе Unix уже имеют под рукой значительную коллекцию уникальных отсортированных ключей: словарь.
В моей системе он расположен по адресу /usr/share/dict/words(который на самом деле является символической ссылкой /usr/share/dict/american-english). Он содержит 119,095уникальные слова и имеет 1.1 MBразмер.
Поскольку он уже отсортирован, мы можем передать --sortedфлаг для создания набора:
$ fst set --sorted /usr/share/dict/words words.fst real 0m0.118s user 0m0.090s sys 0m0.007s maximum resident set size: 9.4 MB
Полученный words.fstв настоящее время 324 KB, что 29.4%от исходного размера файла. Для сравнения: одни и те же сжатые данные (LZ77) имеют вид 302 KB( 27.4%), а те же xzсжатые данные (LZMA) - это 232 KB( 21.1%). Настройки по умолчанию использовались со стандартными утилитами командной строки gzipи xz.
С этого момента я представлю эти результаты в более удобной табличной форме. Как только наборы данных станут большими, я перестану использовать, xzпотому что это займет слишком много времени.
Время представлено как время настенных часов, в основном потому, что это удобно, и время быстро станет достаточно большим, чтобы в шуме возникли небольшие отклонения.
Вот первая таблица для набора данных словаря, в котором есть 119,095ключи:
| Формат | Время | Максимальный объем памяти | Космос |
|---|---|---|---|
| гладкий | - | - | 1100 КБ |
| FST | 0.12s | 9,4 МБ | 324 КБ (29,4%) |
| GZIP | 0.15s | 1,8 МБ | 302 КБ (27,4%) |
| XZ | 0.35s | 30,1 МБ | 232 КБ (21,1%) |
Цель сравнения структуры данных FST с другими алгоритмами сжатия - обеспечить базовое сравнение. Не обязательно быть лучше или быстрее, чем LZ77, LZMA или что-то еще, но это полезные ориентиры. В частности, напомним, что FST на самом деле является структурой данных даже в сжатом состоянии. Общие схемы сжатия, такие как LZ77 или LZMA, плохо подходят для простого произвольного доступа или поиска. Точно так же ни алгоритмы LZ77, ни LZMA не требуют сортировки входных данных до того, как сжатие может работать, что является требованием FST. Следовательно, это не совсем сравнение яблок с яблоками.
Гутенберг
Одним из возможных вариантов использования структуры данных на основе FST является указатель терминов в системе полнотекстового поиска. Действительно, Lucene использует FST именно для этой цели . Следовательно, имеет смысл протестировать FST с помощью словесных ключей.
Я выбрал корпус Гутенберга для этого теста, потому что его легко получить, он свободно доступен и казался достаточно приличным представлением того, что может быть в полнотекстовой базе данных.
После того, как я загрузил весь Gutenberg на свой жесткий диск, я объединил весь простой текст, разделил на пробелы, отсортировал все токены, полученные в результате разделения, и удалил дубликаты. Об этом говорит сайт https://intellect.icu . (Я также убрал знаки препинания и применил к каждому токену строчные буквы ASCII. Токены с более экзотическими буквами Unicode были оставлены как есть.)
Результирующий набор данных содержит 3,539,670уникальные термины. Вот таблица сравнения других форматов сжатия:
| Формат | Время | Максимальный объем памяти | Место на диске |
|---|---|---|---|
| гладкий | - | - | 41 МБ |
| FST | 2.04s | 21,8 МБ | 22 МБ (53,7%) |
| GZIP | 2.50s | 1,8 МБ | 13 МБ (31,7%) |
| XZ | 14.66s | 97,5 МБ | 10 МБ (24,0%) |
В этом случае мы смогли превзойти скорость gzip, что довольно приятно. К сожалению, FST был только 53.7%размером исходных данных, тогда как в предыдущем примере FST словаря был 29.4%исходных данных. В то время как gzipи по- xzпрежнему выполнять довольно хорошо, их степень сжатия также пострадали. Это может означать, что в данных меньше избыточности.
Мы также должны рассмотреть, как выглядит время для создания FST, если бы токены не были отсортированы заранее.
Если токены из набора данных еще не были отсортированы (т. Е. Мы не можем передать --sortedфлаг fst setкоманде), то это займет немного больше времени. Для набора данных Гутенберга время перескакивает 5.58sи использует 129 MB память.
Стоит сделать паузу, чтобы сказать, что на самом деле происходит, когда --sortedфлаг не передан. В частности, структура данных FST должна быть построена путем вставки ключей в лексикографическом порядке. Это означает, что мы должны сначала отсортировать данные. Проблема с сортировкой заключается в том, что самое простое решение - загрузить все ключи в память, а затем выполнить сортировку. Однако, как мы увидим в будущих наборах данных, это не всегда возможно.
Вместо этого fstкоманда разделит входные данные на несколько частей и отсортирует их по отдельности. После сортировки чанк записывается на диск /tmpкак собственный FST. После того, как все фрагменты отсортированы и преобразованы в FST, мы объединяем все FST в один.
«Пакетная» часть этого процесса способствовала 129 MBиспользованию памяти. В частности, размер пакета по умолчанию - это 100,000ключи, и fstкоманда будет сортировать несколько пакетов параллельно. Уменьшение размера пакета уменьшит объем памяти, необходимый процессу.
Однако это все еще не объясняет общего использования памяти! Фактически, часть «размера резидентного набора», сообщаемая timeкомандой, включает данные, считанные из карт памяти, которые постоянно находятся в памяти. Поскольку все промежуточные FST, созданные из каждого пакета, должны быть полностью прочитаны, чтобы их объединить, из этого следует, что ОС должна была прочитать все данные из каждого FST в память. Примечательно, что эти данные на самом деле не являются частью кучи в нашем процессе. Это означает, что если ваша система нуждается в этом, ОС может фактически заменить неиспользуемую память, которая была первоначально заявлена картой памяти, не обязательно влияя на производительность построения (поскольку после того, как часть FST считана и обработана, она больше не нужна ).
Короче говоря, использование памяти при использовании FST и карт памяти может быть сложно проанализировать.
Заголовки Википедии
Предположим, у вас есть огромная коллекция статей, и вы хотите создать действительно быстрый сервис автозаполнения для заголовков каждой из этих статей. Почему бы не использовать FST для хранения названий? Поиск будет очень быстрым. (Elasticsearch использует FST для своего автозаполнения .)
Для этого варианта использования я не искал дальше Википедии. Он содержит огромную коллекцию статей и служит хорошим репрезентативным примером того, как могут выглядеть реальные данные.
На самом деле загрузить всю Википедию довольно просто . Как только XML каждой статьи оказался на моем диске, я написал быструю программу для извлечения заголовка из каждой статьи в отдельный файл. Затем я отсортировал названия. Всего на диске есть 15,777,626заголовки статей 384 MB.
Давайте посмотрим на сравнительную таблицу для этого набора данных.
| Формат | Время | Максимальный объем памяти | Место на диске |
|---|---|---|---|
| гладкий | - | - | 384 МБ |
| FST | 18.31s | 34,1 МБ | 157 МБ (40,9%) |
| GZIP | 13.08s | 1,8 МБ | 91 МБ (23,7%) |
| XZ | 140.53s | 97,6 МБ | 68 МБ (17,7%) |
Наша степень сжатия улучшилась по сравнению с набором данных Гутенберга, но мы стали немного медленнее, чем gzipв процессе.
DOI URL
На этом этапе я изо всех сил пытался найти настоящие наборы данных, которые были бы огромными и свободно доступными. Конечно, я мог сгенерировать связку случайных ключей - или попытаться приблизительно представить, как будут выглядеть настоящие данные, - но это было крайне неудовлетворительно.
Затем я наткнулся на набор данных DOI Интернет-архива , содержащий почти 50,000,000URL-адреса журнальных статей. ( DOI - это идентификатор цифрового объекта .)
Набор данных DOI содержит 49,118,091URL-адреса и занимает место 2800 MBна диске. Давайте посмотрим на сравнительную таблицу.
| Формат | Время | Максимальный объем памяти | Место на диске |
|---|---|---|---|
| гладкий | - | - | 2800 МБ |
| FST | 27.40s | 17,6 МБ | 113 МБ (4,0%) |
| GZIP | 40.39s | 1,8 МБ | 176 МБ (6,3%) |
| XZ | 716.60s | 97,6 МБ | 66 МБ (2,6%) |
Это довольно круто. На этом наборе данных построение FST выполняется быстрее, gzip и степень сжатия у него лучше. Эти данные представляют собой особый случай; однако, поскольку в ключах есть смехотворное количество избыточной структуры. Поскольку это все URL-адреса журнальных статей, существуют длинные последовательности URL-адресов, которые выглядят в основном одинаково, но с немного другим суффиксом. Это почти идеально подходит для FST, поскольку он сжимает префиксы. (Честно говоря, здесь тоже подойдет дерево.)
Обычное сканирование
Я не мог остановиться на наборе данных DOI. 50,000,000ключи большие, и их сжатие всего за 27секунды - хороший результат, но я не рассматриваю его как репрезентативный пример реальных рабочих нагрузок, поэтому было жаль, что самый большой набор данных, который мне пришлось попробовать с FST, также оказался почти лучший сценарий.
Я разместил свой conunudrum на / r / rust , и ta-da, erickt заново научил меня Common Crawl , о котором я совершенно забыл.
Common Crawl огромен . Петабайты огромные. Я честолюбив, но не совсем , что амбициозная. К счастью, хорошие ребята из Common Crawl публикуют свой набор данных в виде ежемесячного дайджеста. Я выполнил сканирование в июле 2015 года, размер которого превышает 145 ТБ.
Это все еще слишком велико. Скачивание всех этих данных и их обработка займет много времени. К счастью, специалисты Common Crawl снова прибегают к помощи: они делают индекс всех файлов «WAT» доступными. Файлы «WAT» содержат метаданные о каждой просканированной странице и не включают фактический необработанный документ. Среди этих метаданных есть URL-адрес, который мне и нужен.
Несмотря на сужение объема, загрузка такого большого объема данных через кабельный модем со скоростью 2 МБ / с не доставит удовольствия. Итак, я создал c4.8xlargeэкземпляр EC2 и начал загружать все URL-адреса из архива сканирования за июль 2015 года с помощью этого сценария оболочки:
#!/bin/bash
set -e
url="https://aws-publicdatasets.s3.amazonaws.com/$1"
dir="$(dirname "$1")"
name="$(basename "$1")"
fpath="$dir/${name}.urls.gz"
mkdir -p "$dir"
if [ ! -r "$fpath" ]; then
curl -s --retry 5 "$url" \
| zcat \
| grep -i 'WARC-TARGET-URI:' \
| awk '{print $2}' \
| gzip > "$fpath"
fi
Если сохранить как dl-wat, можно было бы запустить его так:
$ zcat wat.paths.gz | xargs -P32 -n1 dl-wat
И бац, у нас есть 32 параллельных процесса, извлекающих все URL-адреса из архива сканирования. Как только это будет сделано, все, что нам нужно сделать, это получить catфайлы URL (из которых будет по одному для каждого watфайла).
Общее количество URL-адресов, которые я получил, было 7,563,934,593и занимает 612 GB на диске в несжатом виде. После сортировки и дедупликации общее количество URL-адресов есть 1,649,195,774и занимает 134 GBна диске.
Теперь мы можем приступить к созданию нашего FST. Поскольку сортировка URL-адресов займет очень много времени, мы просто позволим fstкоманде сделать это за нас. А именно, в сравнительной таблице ниже показано время, которое потребовалось для первоначального построения из несортированных данных, а также время, которое потребовалось для повторного запуска процесса для отсортированного списка URL-адресов.
| Формат | Время | Максимальный объем памяти | Место на диске |
|---|---|---|---|
| гладкий | - | - | 134 ГБ |
| fst (отсортировано) | 82 мин. | 56 МБ | 27 ГБ (20,1%) |
| fst (несортированный) | 240 минут | ? | тем же |
| GZIP | 36 минут | 1,8 МБ | 15 ГБ (11,2%) |
| XZ | - | - | - |
Мои инстинкты относительно того, что URL-адреса DOI являются «идеальным случаем», похоже, подтверждаются этими результатами. А именно, мы вернулись к более реалистичной степени сжатия 20.1%, хотя мы все еще сильно проигрываем gzip.
Нет цифр для, xzпотому что это, вероятно, займет очень много времени.
Еще один момент, о котором стоит упомянуть, - это время, которое потребовалось для создания этого FST. А именно, он содержит в 32 раза больше ключей, чем набор данных DOI, но его выполнение заняло в 182 раза больше времени. На самом деле у меня пока нет полного ответа на этот вопрос. По моим оценкам, кеш, используемый для повторного использования состояний, может снизить производительность, если он заполнен. Другая оценка состоит в том, что, поскольку набор данных DOI имел такую избыточную структуру, ключи можно было обрабатывать быстрее. А именно, большинство ключей, вероятно, привело к компиляции очень небольшого количества состояний. К сожалению, это будет крепкий орешек, потому что FST для набора данных Common Crawl настолько велик, что его трудно проверить с помощью традиционных инструментов.
У меня нет измерения максимальной памяти, используемой несортированным процессом построения, но, как я помню, из наблюдений htopбыло то, что использование разделяемой памяти процессом стало довольно высоким (десятки ГБ). По моим оценкам, это было отражением отображаемой памяти из файлов во время слияния временных FST. Действительно, я мог наблюдать, как его использование разделяемой памяти значительно снижается, когда я запускал такую команду:
$ cat lots of huge files > /dev/null
А именно, читая много больших файлов с помощью cat, я заставил операционную систему выделить часть своего кэша страниц для файлового ввода-вывода, не связанного с fstпроцессом. Поскольку так много его было посвящено fstпроцессу, ОС начала забирать часть из fstпроцесса, и использование общей памяти в fst процессе начало падать.
Действительно, если вы создадите свой собственный большой FST, а затем выполните следующую команду:
$ fst range large.fst | wc -l
и посмотрите, htopпока он работает, вы должны увидеть, как использование совместно используемой и резидентной памяти растет одновременно. Например, в наборе данных DOI использование резидентной памяти постоянно 3 MBбольше, чем использование общей памяти, но оба увеличиваются примерно до 113 MB(размер DOI FST), после чего все ключи были перечислены.
Наконец, давайте взглянем на то, что значит запросить этот огромный FST. Например, возможно, мы хотим найти все URL-адреса Википедии, которые были проиндексированы. Мы можем выбрать поиск по регулярному выражению:
$ fst grep /data/common-crawl/201507/urls.fst 'http://en.wikipedia.org/.*' | wc -l 97054
Когда я впервые запустил эту команду, это заняло 2целые секунды! Что с этим? Что ж, если я снова запустил ту же команду, она завершится примерно через 0.1 секунды. Это большая разница. В самом деле, это потому, что FST не был в памяти, и ОС потребовалось время, чтобы прочитать данные, необходимые для доступа в память. (В частности, это диск с вращающейся ржавчиной, поэтому мы действительно платим за время физического поиска и ввод-вывод файлов. Напомним, что формат FST на диске способствует произвольному доступу.)
Действительно, вывод time -vсообщит нам, что были 164ошибки страниц, которые потребовали, чтобы ОС вышла и выполнила файловый ввод-вывод для устранения. При последующих вызовах это число упало до, 0поскольку эти части файла все еще находились в памяти.
Для быстрого сравнения я скопировал Common Crawl FST на SSD, очистил свой кеш страницы и повторно выполнил тот же grepзапрос. Я подтвердил, что были приблизительно 164ошибки страниц. Общее время выполнения составляло всего несколько 0.16секунд (по сравнению с 2секундами для вращающегося диска с холодным кешем страниц). Повторный запуск снова снижает его до 0.1секунд. Таким образом, использование SSD почти делает кеш страницы неприменимым для быстрых запросов.
Если верить Интернету, мы создали самый большой в мире FST (по количеству ключей). Ура!
Производительность запроса
Серьезным упущением в предыдущих экспериментах являются тесты производительности запросов. Это упущение сделано намеренно, потому что я еще не придумал для него хороший тест. Ключевой частью тестирования производительности запросов является моделирование реальных запросов под нагрузкой. В частности, в идеале он должен включать одновременный запрос нескольких FST и то, что происходит, когда части FST удаляются из кэша страниц операционной системы.
С учетом сказанного, все же стоит понять, на что похожа производительность запросов. Для этого у меня есть микро-тест, который сравнивает членство в двух разных наборах данных между fst::Set, std::collections::HashSetи std::collections::BTreeSet. fst::Set- это заданная структура данных, обсуждаемая в этой статье, представленная FST. HashSetпредставляет собой набор, реализованный с помощью хеш-таблицы. BTreeSetупорядоченный набор, реализованный с помощью btree.
Первый набор данных - это случайная выборка 100,000слов из набора данных Гутенберга. Наш тест ищет случайное слово из набора данных (так что он проверяет только членство в наборе, где ответ всегда «да»).
fst_contains 575 ns/iter btree_contains 134 ns/iter hash_fnv_contains 63 ns/iter hash_sip_contains 84 ns/iter
(Время в наносекундах на операцию. То есть в этом наборе данных членство в наборе для структуры данных FST занимает около 575 наносекунд.)
Названия тестов должны указывать на то, что тестируется. (Разница между hash_fnv_containsи hash_sip_containsзаключается в типе используемой хеш-функции. Первая использует стандартный хэш Fowler-Noll-Vo, а вторая - SipHash, которая криптографически безопасна и медленнее.)
Это демонстрирует, что структуры данных на основе FST действительно имеют худшую производительность поиска, чем классические структуры данных общего назначения. Однако история не так уж и плоха. В этом тесте FST работают 5xмедленнее, чем btrees. Конкретная причина, по которой FST может быть медленнее, заключается в том, что ему нужно выполнять больше работы для декодирования состояний и переходов в базовой машине. Это отличный пример случая, когда алгоритмическая временная сложность не вызывает смеха. В частности, время поиска для таблиц FST является , O(k)где kдлина ключа в то время как время поиска для btrees это O(klogn), где n это количество элементов в наборе. Разница в том, что btree, вероятно, имеет гораздо более быстрый доступ к своим ключам, несмотря на необходимость проводить больше сравнений.
Давайте посмотрим на другой набор данных: 100,000URL-адреса Википедии (из набора данных Common Crawl).
fst_contains 1,169 ns/iter btree_contains 415 ns/iter hash_fnv_contains 101 ns/iter hash_sip_contains 107 ns/iter
Ключи в этом наборе данных немного длиннее (URL-адреса), чем в предыдущем наборе данных (слова из Гутенберга), что объясняет, почему время для всех структур данных увеличилось. Здесь интересно отметить, что поиск структуры данных FST теперь выполняется 2.8xмедленнее, чем поиск btree. Фактически, это именно то, что можно было ожидать с учетом вышеупомянутых гарантий временной сложности. А именно, btree необходимо выполнять lognсравнения, при этом каждое сравнение требует определенных kшагов. С другой стороны, FST нужно выполнить kшаги только один раз. Поскольку этот набор данных имеет гораздо более длинные ключи, стоимость каждогоk шаги увеличились, что снижает производительность поиска по btree по сравнению с FST. Моя гипотеза состоит в том, что по мере роста числа ключей и длины у FST он будет становиться все быстрее и быстрее, чем btree.
Обработка хэш-карты, вероятно, немного сложнее, поскольку время, необходимое для вычисления хеш-кода, равно O(k). Этого достаточно, чтобы получить соответствующее значение. Теоретически хэш-карта может занять O(n)время для поиска в худшем случае, но, по моему опыту, беспокоиться об этом редко (если только вы не реализуете хеш-карту!).
Исследование, описанное в статье про Инструмент командной строки FST, подчеркивает ее значимость в современном мире. Надеюсь, что теперь ты понял что такое Инструмент командной строки FST и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Индексирование большого набора ключей с помощью конечных автоматов
Комментарии
Оставить комментарий
Индексирование большого набора ключей с помощью конечных автоматов
Термины: Индексирование большого набора ключей с помощью конечных автоматов