Лекция
Привет, Вы узнаете о том , что такое базы данных в java, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое базы данных в java , настоятельно рекомендую прочитать все из категории ООП и практические JAVA.
Для хранения данных мы можем использовать различные базы данных - Oracle, MS SQL Server, MySQL, Postgres и т.д. Все эти системы управления базами данных имеют свои особенности. Главное, что их объединяет это взаимодействие с хранилищем данных посредством команд SQL. И чтобы определить единый механизм взаимодействия с этими СУБД в Java еще начиная с 1996 был введен специальный прикладной интерфейс API, который называется JDBC.
То есть если мы хотим в приложении на языке Java взаимодействовать с базой данных, то необходимо использовать функциональные возможности JDBC. Данный API входит в состав Java , в частности, для работы с JDBC в программе Java достаточно подключить пакет java.sql. Для работы в Java EE есть аналогичный пакет javax.sql, который расширяет возможности JDBC.
Работа с базами данных в Java выполняется с помощью JDBC (Java Database Connectivity) - стандартного интерфейса программирования, который позволяет взаимодействовать с различными типами баз данных.
Вот пример шагов для работы с базой данных в Java:
Загрузите драйвер базы данных: Для каждой базы данных существует соответствующий драйвер JDBC, который нужно загрузить в свой проект. Обычно это делается с помощью оператора Class.forName().
Установите соединение с базой данных: Для установки соединения с базой данных используйте класс Connection. Вы можете указать параметры подключения, такие как имя пользователя и пароль.
Создайте запрос: Для выполнения запросов к базе данных в Java используйте интерфейс Statement. Вы можете выполнить любой SQL-запрос, включая запросы на добавление, обновление и удаление данных.
Получите результаты: Результаты запроса можно получить с помощью интерфейса ResultSet. Вы можете использовать ResultSet для получения отдельных значений или для итерации по результатам запроса.
Закройте соединение: После того, как вы закончили работу с базой данных, закройте соединение с помощью метода Connection.close().
Пример кода:
import java.sql.*;
public class Example {
public static void main(String[] args) {
try {
// Загрузка драйвера базы данных
Class.forName("com.mysql.jdbc.Driver");// Установка соединения с базой данных
Connection con = DriverManager.getConnection("jdbc:mysql://intellect.icu:3306/mydatabase", "root", "password");// Создание запроса
Statement stmt = con.createStatement();
ResultSet rs = stmt.executeQuery("SELECT * FROM mytable");// Получение результатов запроса
while(rs.next())
System.out.println(rs.getString(1) + " " + rs.getString(2) + " " + rs.getString(3));// Закрытие соединения
con.close();
} catch(Exception e) {
System.out.println(e);
}
}
}
Это пример простого приложения, которое устанавливает соединение с базой данных MySQL, выполняет запрос на выборку данных из таблицы и выводит результаты в консоль. Однако, обычно для работы с базами данных в Java используются библиотеки ORM, такие как Hibernate или JPA.
Однако не все базы данных могут поддерживаться через JDBC. Для работы с определенной СУБД также необходим специальный драйвер. Каждый разработчик определенной СУБД обычно предоставляет свой драйвер для работы с JDBC. То есть если мы хотим работать с MySQL, то нам потребуется специальный драйвер для работы именно MySQL. Как правило, большинство драйверов доступны в свободном доступе на сайтах соответствующих СУБД. Обычно они представляют JAR-файлы. И преимущество JDBC как раз и состоит в том, что мы абстрагируемся от строения конкретной базы данных, а используем унифицированный интерфейс, который един для всех.
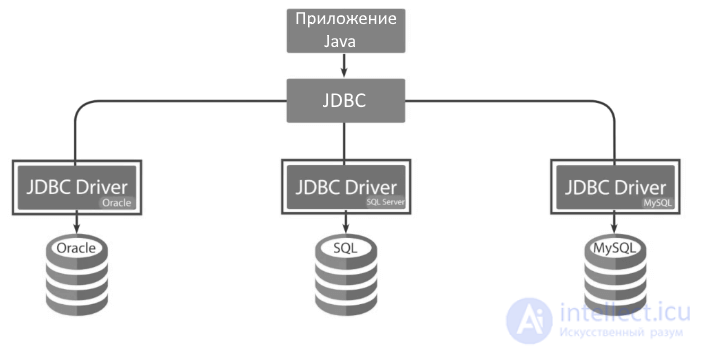
Для взаимодействия с базой данных через JDBC используются запросы SQL. В то же время возможности SQL для работы с каждой конкретной СУБД могут отличаться. Например, в MS SQL Server это T-SQL, в Oracle - это PL/SQL. Но в целом эти разновидности языка SQL не сильно отличаются.
DBC (Java Database Connectivity) - это стандартный интерфейс программирования, который позволяет взаимодействовать с различными типами баз данных из приложений, написанных на языке Java. Он обеспечивает унифицированный способ доступа к базам данных, независимо от используемого типа базы данных.
Интерфейс JDBC включает в себя следующие ключевые компоненты:
DriverManager - класс, который управляет списком зарегистрированных драйверов JDBC.
Driver - интерфейс, который определяет методы, необходимые для взаимодействия с конкретной базой данных.
Connection - интерфейс, который представляет собой соединение с базой данных. Он позволяет выполнять SQL-запросы и получать результаты.
Statement - интерфейс, который позволяет выполнить SQL-запрос и получить результаты в виде объекта ResultSet.
ResultSet - интерфейс, который представляет собой набор строк, возвращенных SQL-запросом. Он позволяет итерироваться по результатам запроса и получать значения полей.
PreparedStatement - интерфейс, который представляет собой предварительно скомпилированный SQL-запрос. Он позволяет многократно использовать один и тот же запрос с разными параметрами.
CallableStatement - интерфейс, который представляет собой вызываемую процедуру или функцию базы данных. Он позволяет передавать параметры в вызываемую процедуру и получать результаты.
Некоторые приложения обрабатывают данные, которые пользователь должен ввести после запуска программы. Например, калькулятор, прежде чем посчитать сумму двух чисел, ждет, когда получит их от пользователя. И слагаемые, и сумма впоследствии нигде не сохраняются, и когда калькулятор будет запущен снова, пользователю понадобится ввести новые данные для обработки.
Другие программы запоминают какие-то небольшие сведения о предыдущих сеансах работы. Например, игра «Сапер» (и многие другие) поддерживают список игроков, набравших наибольшее число очков в предыдущих играх. Эта информация чаще всего хранится в небольшом файле произвольного формата и извлекается из него при запуске программы или при выборе пользователем соответствующего пункта меню.
Многие программные продукты предназначены для обработки большого количества данных, которые невозможно каждый раз запрашивать у пользователя. Более того, основная задача современных приложений может заключаться не столько в обработке, сколько в хранении и поиске данных. А для больших объемов данных обычные файлы не подходят – для того, чтобы найти запись, удовлетворяющую нужным условиям, файл нужно просмотреть от начала до конца.
Поэтому большинство современных приложений накапливают данные в базе данных и взаимодействуют с этой базой данных посредством СУБД. СУБД берет на себя все заботы по организации оптимального размещения данных на жестком диске, выборке нужных данных, их защите от несанкционированного доступа и т.д. Приложению остается только обращаться к СУБД с соответствующими запросами на добавление, редактирование, поиск нужной информации в БД.
Последние несколько лет наибольшей популярностью пользуются реляционные базы данных, в которых данные хранятся в форме таблиц. Существует несколько десятков популярных реляционных СУБД. Они различаются по ряду параметров: производительность, масштабируемость, защищенность, стоимость, дополнительные возможности по манипулированию данными и т.д., но в их основе лежит одна и та же математическая модель.
Все реляционные СУБД поддерживают стандартизированный язык запросов SQL. С его помощью можно создавать таблицы (т.е. задавать структуру БД), заполнять их данными, осуществлять выборку нужных данных по запросу.
Разработчики, знакомые с SQL, могут использовать для хранения данных своего приложения любую реляционную СУБД, не тратя много времени на то, чтобы разобраться с особенностями ее функционирования.
Программа, использующая для хранения данных реляционную СУБД, должна каким-то образом соединяться с конкретной базой данных, посылать ей SQL-запросы и анализировать полученный результат.
Существует универсальный, не зависящий от языка программирования, механизм взаимодействия программ с СУБД – интерфейс открытого доступа к данным ODBC. Это низкоуровневый API, который можно использовать для работы с любой реляционной БД, обращаясь к базе данных через системные вызовы. Единственное требование: в системе должен быть установлен нужный ODBC-драйвер (иногда он может не входить в дистрибутив СУБД, поэтому понадобится найти его и установить отдельно).
Пользоваться низкоуровневым API достаточно трудоемко. Гораздо удобнее работать с библиотекой того языка, на котором разрабатывается вся программа – в нашем случае Java.
Язык Java предоставляет собственный интерфейс для взаимодействия с реляционными БД. Он называется JDBC (Java Database Connectivity). С точки зрения программирования можно рассматривать JDBC просто как набор классов, позволяющих легко осуществлять такие действия как:
Java-классы, используемые для работы с реляционной БД, взаимодействуют с этой БД посредством так называемого JDBC-драйвера. Это посредник между библиотеками Java и внутренним механизмом СУБД. JDBC-драйверы бывают нескольких видов.
Самый доступный вариант – драйвер моста JDBC-ODBC. Он присутствует в дистрибутиве Java SDK по умолчанию, так что его поиск и установка в систему не требуется. Этот драйвер преобразует все обращения к интерфейсу JDBC в обращения к интерфейсу ODBC.
Другой вариант – драйвер, полностью написанный на Java. Такой драйвер преобразует запросы JDBC непосредственно в запросы, специфичные для конкретной базы данных. Такие драйвера разработаны практически для всех популярных СУБД, однако необходимо нужный драйвер найти и интегрировать его с собственной программой.
И в том и в другом случае программный код одинаков, за исключением команды, загружающей нужный драйвер. Но второй вариант предпочтительнее по двум причинам.
Чтобы приступить к организации хранения данных программы в БД (посредством механизма JDBC), необходимо выбрать СУБД, с которой будет работать программа, установить ее и настроить и после этого создать собственно базу данных. База данных обычно не создается во время работы приложения, а поставляется в его составе уже в готовом виде (хотя, возможно, незаполненная). Это логично, поскольку структура БД (описание ее таблиц), как правило, остается неизменной.
Мы будем использовать СУБД Firebird, одними из основных преимуществ которой являются бесплатность и открытость. Кроме того, для данной СУБД доступен как ODBC-, так и JDBC-драйвер (JDBC-драйвер называется Jaybird). Хотя, как было отмечено выше, для разработки программы нам потребуется только один из них (и мы будем использовать Jaybird), ODBC-драйвер для используемой СУБД всегда полезно иметь под рукой – всегда может появиться потребность написать взаимодействующую с ней программу на другом языке программирования.
Firebird – это мощная компактная реляционная СУБД с архитектурой клиент-сервер. Она может выполняться на разнообразных клиентских и серверных платформах, включая Windows, Linux, MacOS.
Ядро Firebird состоит из двух основных программ: сервер баз данных и клиентская библиотека (их также называют сервер Firebird и клиент Firebird). Взаимодействие с БД осуществляется через сервер, который должен быть установлен и запущен на компьютере, где физически располагаются и сами БД. Клиентская библиотека используется для связи с сервером баз данных с удаленных рабочих станций. Поэтому она должна быть установлена на компьютере, где функционирует приложение, обращающееся к БД. Заметим, что:
В качестве примера локального приложения будем рассматривать программу, предназначенную для учета домашних расходов. Эта программа хранит в БД информацию о сделанных покупках и генерирует на основе этой информации различные отчеты. Очевидно, что каждый пользователь, устанавливающий ее на свой компьютер, должен работать только с собственной базой данных.
Примером распределенного приложения будет задача №1 – электронное голосование. Пользователи могут устанавливать программу голосования на разных компьютерах (подключенных к общей сети). Но БД, в которой хранятся сведения о поданных голосах, одна на всех, и расположена она на компьютере, где установлен сервер Firebird.
Установка Firebird в домашних условиях не вызывает никаких проблем. Вам понадобится дистрибутив этой программы (который можно скачать в Интернете, получить у преподавателя или прямо здесь).
Краткое руководство по установке Firebird можно получить на сайте http://www.firebirdsql.org/file/documentation/html/en/firebirddocs/qsg3/firebird-3-quickstartguide.html.
Firebird, как и ряд других СУБД (например, MySQL) по умолчанию не имеет графического интерфейса (такого, как в Microsoft Access). Все действия, начиная от создания базы данных, придется выполнять через утилиты командной строки посредством SQL-запросов.
Однако можно воспользоваться графическим средством администрирования баз данных Firebird, предлагаемым сторонним разработчиком. В частности, существуют две хороших бесплатных программы: IB Expert (установить) и FlameRobin (установить). Далее мы будем ссылаться только на IB Expert, обладающую большими возможностями и более простым интерфейсом.
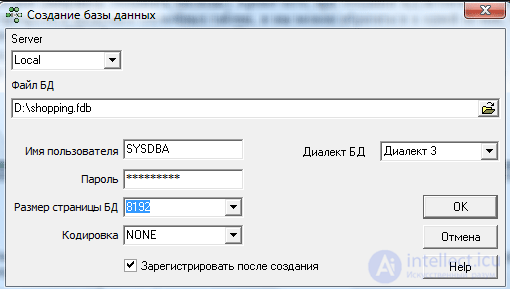
База данных создается оператором CREATE DATABASE, которому необходимо указать:
Например, следующая команда создает базу данных shopping.fdb:
CREATE DATABASE 'D:\data\shopping.fdb' page_size 8192 user 'SYSDBA' password 'masterkey';
Разумеется, путь к файлу БД следует заменить на тот, который нужен вам.
Имя пользователя и пароль в этой команде взяты не произвольно. Пользователь SYSDBA — это администратор СУБД Firebird, обладающий всевозможными привилегиями. Он региструруется в системе при установке сервера Firebird и в операционной системе Windows имеет по умолчанию пароль masterkey (точнее, masterke, поскольку Firebird считает значимыми только первые 8 символов пароля). В OC Linux при установке генерируется случайный пароль, который записывается в файл /opt/firebird/SYSDBA.password.
Атрибут page_size означает размер внутренней страницы базы данных. Дополнительную информацию можно найти в литературе по Firebird.
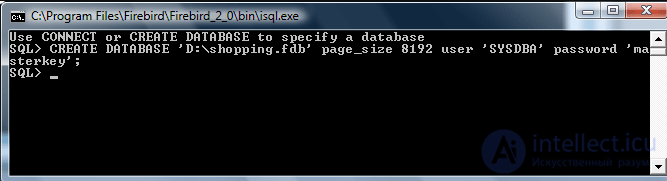
Для того, чтобы выполнить команду CREATE DATABASE (а также осуществить любые другие SQL-запросы к базе данных), предназначена утилита командной строки isql, которую можно найти в каталоге bin.
При запуске появляется следующее приглашение:
SQL>
Теперь можно выполнить нашу команду. Будет создана база данных и снова появится приглашение, показывающее, что мы соединены с нею и можем обращаться с SQL-запросами (например, создавать таблицы).
Кроме того, при создании БД автоматически конструируется несколько служебных таблиц, и мы можем обратиться к одной из них, чтобы убедиться, что БД действительно создана. Например, выполнить запрос
SELECT * FROM RDB$RELATIONS;
Если БД создалась корректно, на экран будет выдано достаточно большое количество данных. «Пустая» БД на самом деле хранит метаданные о своих характеристиках, которых по мере создания новых таблиц будет становиться все больше. Чтобы закончить работу с isql, выполните команду
QUIT;
С помощью графического средства администрирования создать новую БД значительно проще. Например, в IB Expert можно выполнить команду База данных --> Создать базу..., после чего в появившемся диалоговом окне заполнить соответствующие поля. Однако графического средства под рукой может не быть, в то время, как утилиты командной строки являются частью Firebird.
Разработка любой БД начинается с определения ее структуры (схемы). Необходимо решить, из каких таблиц будет состоять база данных, из каких полей (столбцов) они будут состоять, каким образом будут связаны друг с другом. Бессмысленно начинать строить базу данных когда ее структура не определена и не зарисована на бумаге либо, что гораздо предпочтительнее, в специализированной программе, такой как ERWIN, Rational Rose Data Modeler или DBDesigner. Об этом говорит сайт https://intellect.icu . DBDesigner к тому же является бесплатным и свободно распространяемым программным средством.
Профессиональные разработчики начинают с разработки модели «сущность-связь» (ER-модели). Они определяют сущности (информация о которых должна храниться в БД), их атрибуты (какая именно информация), и связи между ними. После этого достаточно легко преобразовать ER-модель в реляционную модель.
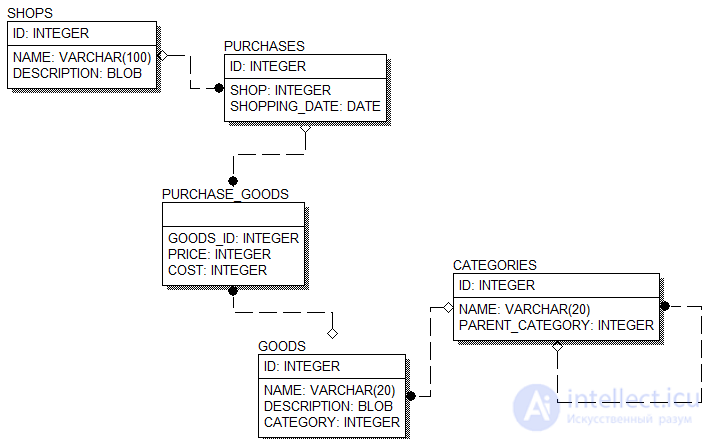
Программа для учета домашних расходов будет хранить информацию о:
Соответственно БД будет состоять из четырех таблиц: CATEGORIES, GOODS, SHOPS, PURCHASES, а также одной вспомогательной таблицы для хранения связи типа многие-ко-многим между сущностями ТОВАР и ПОКУПКА. Структура БД будет следующей:
Создать таблицы БД можно с помощью графического средства администрирования IB Expert. Для этого необходимо соединиться с БД командой База данных --> Подключиться к базе, предварительно зарегистрировав ее командой База данных --> Зарегистрировать базу, после чего в контекстном меню узла Таблицы выбрать команду Новая таблица... Откроется редактор, похожий на конструктор таблиц Microsoft Access, в котором и описываются поля новой таблицы.
Профессиональный разработчик баз данных (и/или программ, использующих базы данных) для создания таблиц БД напишет SQL-код, состоящий из операторов CREATE. Имея этот код (сохраненный в обычном текстовом файле с расширением .sql), можно в любой момент воссоздать базу данных «с нуля», просто запустив его на выполнение.
Впрочем, можно поступить совсем хитро: создать таблицу в IB Expert, а затем на вкладке Скрипт окна просмотра и редактирования таблицы (оно появится, если дважды щелкнуть по названию существующей таблицы) посмотреть SQL-запрос, используемый для ее создания, и скопировать этот запрос в отдельный файл.
Таблицы для программы учета домашних расходов создаются посредством пяти операторов CREATE TABLE. Они не представляют никаких трудностей для того, кто немного знаком с языком SQL (а знание SQL обязательно для выполнения упражнений этой главы).
Следует заметить, что диалекты языка SQL для различных СУБД могут отличаться. Так, например, СУБД MySQL позволяет при описании поля указать атрибуты PRIMARY KEY или AUTO INCREMENT. В SQL-диалекте Firebird таких атрибутов нет. Чтобы указать первичный ключ таблицы, используется отдельный параметр.
CREATE TABLE CATEGORIES (ID INTEGER NOT NULL,NAME VARCHAR(50),PARENT_CATEGORY INTEGER,PRIMARY KEY (ID));
CREATE TABLE GOODS (
ID INTEGER NOT NULL,
NAME VARCHAR(100),
DESCRIPTION BLOB SUB_TYPE 1 SEGMENT SIZE 80,
CATEGORY INTEGER,PRIMARY KEY (ID)
);
CREATE TABLE SHOPS (
ID INTEGER NOT NULL,
NAME VARCHAR(100),
DESCRIPTION BLOB SUB_TYPE 1 SEGMENT SIZE 80,
PRIMARY KEY (ID)
);
CREATE TABLE PURCHASES (
ID INTEGER NOT NULL,
SHOPPING_DATE DATE,
SHOP INTEGER,
PRIMARY KEY (ID)
);
CREATE TABLE PURCHASE_GOODS(
PURCHASE_ID INTEGER,
GOODS_ID INTEGER,
PRICE INTEGER,
COST INTEGER
);
Отметим, что тип BLOB описывает поле для хранения произвольных данных любого объема и формата. Параметр SUB TYPE 1 указывает, что данные в этом поле будут храниться текстовые, а назначение параметра SEGMENT SIZE 80 в нашем примере значения не имеет.
СУБД Firebird поддерживает ограничения целостности на внешние ключи. Т.е. можно указать, что данное поле таблицы является внешним ключом и СУБД не позволит записывать в это поле значения, отсутствующие в первичном ключе связанной таблицы. Ограничение на внешний ключ можно задать в самом операторе CREATE TABLE, а можно отдельным оператором после того, как все таблицы будут созданы. Последний случай для сложной БД предпочтительней, поскольку не нужно внимательно следить за порядком создания таблиц (ведь внешний ключ может быть описан только тогда, когда таблица, на которую он ссылается, уже существует).
Например, следующий оператор создает ограничение целостности для внешнего ключа PARENT_CATEGORY таблицы CATEGORIES, который ссылается на ту же самую таблицу (поле PARENT_CATEGORY указывает на родительскую категорию, для которой данная категория является подкатегорией):
ALTER TABLE CATEGORIES ADD CONSTRAINT FK_CATEGORIESFOREIGN KEY (PARENT_CATEGORY) REFERENCES CATEGORIES (ID)ON DELETE SET NULL;
Параметр ON DELETE SET NULL показывает, что при удалении родительской категории следует установить значение внешнего ключа для всех ее покатегорий в NULL. Если значение параметра ON DELETE равно CASCADE, то при удалении строки, на которую ссылаются внешние ключи других строк, они также будут удалены.
Для создания остальных ограничений целостности на внешние ключи используются следующие операторы:
ALTER TABLE GOODS
ADD CONSTRAINT FK_GOODSFOREIGN KEY (CATEGORY) REFERENCES CATEGORIES (ID)ON UPDATE SET NULL;
ALTER TABLE PURCHASES
ADD CONSTRAINT FK_PURCHASESFOREIGN KEY (SHOP) REFERENCES SHOPS (ID)ON DELETE SET NULL;
ALTER TABLE PURCHASE_GOODS
ADD CONSTRAINT FK1_PURCHASE_GOODSFOREIGN KEY (GOODS_ID) REFERENCES GOODS (ID)ON DELETE CASCADE;
ALTER TABLE PURCHASE_GOODS
ADD CONSTRAINT FK2_PURCHASE_GOODSFOREIGN KEY (PURCHASE_ID) REFERENCES PURCHASES (ID)ON DELETE CASCADE;
Очень удобно, когда при добавлении в таблицу новой записи, значение первичного ключа указывать не нужно, поскольку оно генерируется автоматически. Многие диалекты языка SQL позволяют в операторе CREATE TABLE указать для поля первичного ключа инструкцию AUTO INCREMENT, но СУБД Firebird такой возможности не предоставляет. Для того, чтобы значение первичного ключа таблицы генерировалось автоматически, необходимо:
Мы не будем изучать полный синтаксис триггеров Firebird, а просто рассмотрим, каким образом с помощью триггеров и генераторов можно организовать автозаполнение первичного ключа на примере таблицы CATEGORIES.
Сначала создадим генератор:
CREATE GENERATOR CATEGORIES_ID_GEN;
SQL-запрос на создание тригера будет выглядеть следующим образом:
SET TERM ^ ;CREATE TRIGGER SET_CATEGORIES_ID FOR CATEGORIESACTIVE BEFORE INSERT POSITION 0ASBEGINif (NEW.ID is NULL) THENNEW.ID = GEN_ID(CATEGORIES_ID_GEN, 1);END^SET TERM ; ^
По аналогии создаются генераторы и триггеры для автозаполнения первичных ключей таблиц GOODS, SHOPS и PURCHASES.
Полный SQL-код создания базы данных SHOPPINGS можно посмотреть в файле createDB.sql. Вы можете повторить процедуру создания БД «с нуля», выполнив содержащиеся в этом файле операторы или воспользовавшись графическим средством администрирования (IB Expert или FlameRobin). А можно взять файл с уже готовой базой данных и приступить непосредственно к изучению JDBC (осваивая процесс создания БД на примере своего основного задания). Кстати, именно таким образом — в виде готового файла — базы данных чаще всего и распространяются вместе с приложениями.
Прежде чем приступить к работе с интерфейсом JDBC, необходимо ознакомиться с механизмом обработки исключений языка Java. Ранее мы не затрагивали исключения, поскольку в них не было необходимости (хотя профессиональные Java-программисты весьма активно используют этот механизм). Однако практически все методы, которые рассматриваются ниже, могут возбуждать исключения и в обязательном порядке требуют их обработки.
Во время выполнения программы может возникнуть аварийная ситуация. Такое случается при попытке деления на нуль, выходе индекса за границы массива, отсутствии файла, который необходимо загрузить и т.д.
Исключение — это объект, который описывает аварийную ситуацию, произошедшую в некотором фрагменте кода. Оно создается в тот момент, когда возникает аварийная ситуация и вбрасывается в метод, вызвавший ошибку.
Аварийные ситуации бывают двух видов: проверяемые и непроверяемые.
Непроверяемые исключения не требуют от программиста специальных действий по их отслеживанию (хотя программист и может предпринять их по собственной инициативе). К таким исключениям относятся:
Возникновение такой ситуации означает, что в программе, скорее всего, допущена грубая ошибка и наилучший выход — исправить ее, переписав программный код. Поэтому Java просто выводит в консоль диагностическое сообщение и прекращает выполнение программы.
Однако есть множество потенциальных ошибок, которые не означают неизгладимой порочности программы, но препятствуют ее дальнейшему выполнению. Например, программа не может открыть требуемый файл (он заблокирован или отсутствует), установить сетевое соединение или отправить запрос к базе данных. Безусловно, если файл открыть не удалось, бессмысленно выполнять следующие команды (скажем, читающие или записывающие данные в этот файл). Но «вылетать» программе вовсе не обязательно. Достаточно вывести сообщение об ошибке и предоставить пользователю возможность решить самому, закрывать или не закрывать программу.
Такие аварийные ситуации называются проверяемыми. Java обязывает программиста в обязательном порядке предусмотреть реакцию программы на эти ситуации.
Для этого те методы, выполнение которых может вызвать аварийную ситуацию, содержат в своем объявлении перечень таких ситуаций (в виде классов соответствующих объектов-исключений). А те методы, которые их вызывают, должны предусматривать реакцию на все эти ситуации. Реакция может быть, в принципе, нулевой — т.е. программа спокойно игнорирует ошибку и продолжает работать дальше, — но и она должна быть указана явным образом.
Говорят, что первые из этих методов возбуждают исключения, а вторые — обрабатывают их.
В принципе, вместо возбуждения исключений методы могли бы просто возвращать значение типа boolean (true или false), сигнализирующее об успехе или неуспехе его выполнения, а программист мог осуществить проверку с помощью оператора if. Но механизм исключений оказывается предпочтительнее по ряду причин. В частности:
При вызове метода, возбуждающего исключения (одной или нескольких разновидностей) программа должна предусматривать возможность его обработки. Для этого используется блок обработки исключений try{} catch(){}.
Общая форма блока обработки исключений:
try {// блок кода, способный вызвать исключения}
catch (ExceptionType1 ex) {
// обработчик исключения типа ExceptionType1
} catch (ExceptionType2 ex) {
// обработчик исключения типа ExceptionType2
}// ...
finally {
// блок кода для обработки перед выходом из try
}
Вызов метода, возбуждающего исключение, помещается в фигурные скобки после ключевого слова try. При этом в фигурные скобки может быть заключена не одна команда, а несколько (включая те команды, которые никаких исключений возбуждать не могут). По сути, все тело метода можно заключить в единый блок try{}.
По окончании блока try{} следует один или несколько блоков catch(){}. В круглых скобках после ключевого слова catch описывается переменная, имеющая тип отлавливаемого исключения. Далее в фигурных скобках следует обработчик исключения — набор команд, которые должны будут выполниться, если в блоке try{} произойдет исключение данного типа. При этом та часть блока try{}, до выполнения которой, вследствии возникшего исключения дело не дошло, выполнена не будет.
Все классы-исключения являются наследниками класса Throwable и наследуют от него полезный метод printStackTrace(). Он выводит сообщения обо всех методах, встретившихся на пути исключения: сначала метод, в котором исключение возникло, затем метод, вызвавший этот метод и т.д., вплоть до метода, в котором исключение было остановлено в блоке try{}. Либо, если исключение неотслеживаемое и не перехватывается, до самого метода main(). Метод printStackTrace() для неотслеживаемых исключений вызывается по умолчанию, что позволяет найти точное место возникновения ошибки.
Вы можете пронаблюдать это. Создайте два класса. В первом классе опишите метод, возвращающий объект второго класса, но в теле этого метода поместите только одну команду return null. Во втором классе опишите любой метод с пустой реализацией. В методе main() опишите переменную типа второго класса и присвойте ей результат работы первого метода (это будет null, но на этапе компиляции программы Java об этом «не догадается»). Затем напишите команду, использующую эту переменную для обращения ко второму методу. Запустите программу и пронаблюдайте возникшее исключение и трассировку (распечатку последовательности методов, приведших к этому исключению), выведенную в консоль.
У класса Throwable два непосредственных наследника: Error и Exception. Они не добавляют новых методо, а служат, чтобы разделить классы-исключения на две большие группы: классы-ошибки и собственно классы-исключения. Классы-ошибки (наследники Error) описывают аварийные ситуации, произошедшие в виртуальной машине Java, их не рекомендуется использовать в обычной программе. Классы-исключения, являющиеся наследниками Exception, можно и даже нужно обрабатывать.
Мы затронули краешек иерархии классов-исключений (на самом деле эта иерархия очень большая, порядка двухсот классов, разбросанных по самым различным пакетам), чтобы отметить простую и важную деталь: после блока try{} можно указать один-единственный блок catch{}, у которого в круглых скобках будет описан объект класса Exception. Этот блок будет обрабатывать все возможные исключения, которые могут возникнуть в блоке try{}.
Наконец, в конструкции try{} catch(){} может присутствовать необязательная часть: блок finally{}. Он содержит команды, которые должны быть выполнены, несмотря ни на что: возникло исключение или не возникло, было оно обработано в catch{} или не было. В любом случае в финале будет выполнен данный блок команд
.
Рассмотрим простой пример. Пусть известно, что метод dangerousMethod1() объекта importantObject способен вызвать исключение класса A, а метод dangerousMethod1() — исключение класса B. Предположим, мы программируем метод work(), который должен последовательно обратиться к обоим этим методам, но в случае возникновения исключения никаких особых действий предпринимать не нужно. В этом случае используем следующий код:
public void work() {
try {
importantObject.dangerousMethod1();
importantObject.dangerousMethod2();
} catch (A ex) {
} catch (B ex) {
}
}
или даже короче (пользуясь тем, что и A, и B — наследники класса Exception).
public void work() {
try {
importantObject.dangerousMethod1();
importantObject.dangerousMethod2();
} catch ( Exception ex) {
}
}
Метод, в котором возбуждается исключение, может не знать, каким образом следует его обрабатывать. В то же время использовать пустой обработчик, который просто «глушит» это исключение может быть нежелательно. В некоторых случаях целесообразно выбросить исключение наружу, где его сможет обработать метод более высокого уровня — тот, в котором вызывается данный метод.
Чтобы выбросить исключение, необходимо:
catch{}) использовать ключевое слово throw. После него указывается объект, который будет выброшен в качестве исключения.try{} catch(){}.Пусть в рассмотренном выше примере метод work() способен обрабатывать (правда, по-прежнему ничего не делая) исключение класса A, но как поступить с исключением класса B не знает, поэтому выбрасывает его наружу в надежде, что метод, вызвавший его, окажется более компетентен.
public void work()
throws B {
try {
importantObject.dangerousMethod1();
importantObject.dangerousMethod2();
} catch (A ex) {} catch (B ex) {throw ex;}}
Можно «научить» метод возбуждать собственные исключения, а не только те, которые «пойманы» им в блоке try{} catch(){}. Для этого используется та же директива throw, а в заголовке метода — ключевое слово throws, но объект класса-исключения необходимо создать «вручную», вызвав его конструктор.
JDBC-драйвер Jaybird, полностью написанный на Java, не требует установки с помощью инсталлятора. Достаточно распаковать архив в любую подходящую папку.
Для того, чтобы программа, которой предстоит работать с базой данных, «нашла» соответствующий драйвер, следует указать ей пути к jar-архивам, входящим в состав Jaybird. Это делается на вкладке Classpath в окне конфигурации запуска (Run --> Run... --> Java Application). Выберите в дереве узел User Entries и нажмите кнопку Add External JARs... (добавить внешние jar-архивы). Добавьте все файлы с расширением .jar, которые присутствуют в каталоге, куда вы распаковали Jaybird, а также в подкаталоге lib. В результате должно получиться примерно то, что изображено на рисунке.
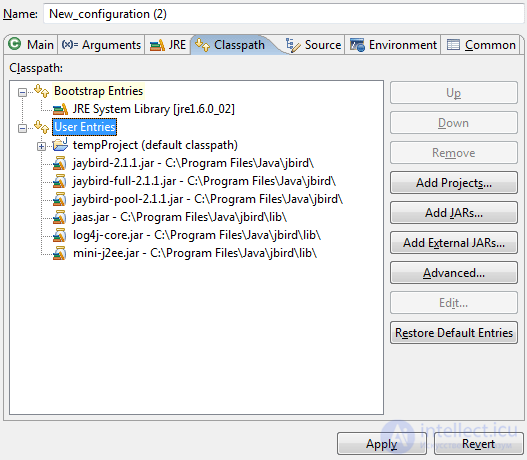
Для того, чтобы начать работу с базой данных Firebird, необходимо выполнить два обязательных действия:
Зарегистрировать JDBC-драйвер Firebird можно следующей командой:
Class.forName("org.firebirdsql.jdbc.FBDriver");
В механизм работы этой команды мы здесь вдаваться не будем: желающие могут найти подробности в литературе, рекомендованной для дополнительного изучения. Отметим только, что метод forName() возбуждает исключение типа ClassNotFoundException (требуемый класс не найден и не может быть загружен), которое возникнет в том случае, если на вкладке Classpath были неверно прописаны пути к драйверу Jaybird, либо драйвер оказался не тот.
Чтобы получить соединение с базой данных (которое представляет собой объект класса Connection), необходимо обратиться к методу getConnection(), определенному в классе DriverManager.
Существует четыре версии этого метода, но чаще всего используется вариант с тремя строковыми параметрами. Первый параметр описывает источник данных (то есть, ту базу данных, с которой мы собираемся работать), второй – имя пользователя и третий – пароль для доступа к БД.
Источник данных представляет собой URL-строку следующего формата:
jdbc:название_подпротокола:дополнительные параметры
Здесь название_подпротокола зависит от используемой СУБД и JDBC-драйвера. При использовании СУБД Firebird и драйвера Jaybird в качестве названия протокола следует использовать firebirdsql.
Дополнительные параметры соответствуют формату URL и могут содержать адрес узла в сети, на котором функционирует сервер Firebird (если Firebird-сервер установлен на том же компьютере, на котором запускается программа, то используется адрес 127.0.0.1 или его псевдоним localhost), номер порта (для СУБД Firebird – 3050), собственно имя файла БД.
Например, если файл с базой данных имеет адрес D:\data\shopping.fdb, источник данных задается строкой «jdbc:firebirdsql:localhost/3050:D:\\data\\shopping.fdb» (не забываем, что разделители «\» в пути к файлу необходимо удваивать, поскольку «\» является в Java специальным символом).
Метод getConnection(String dataSource, String user, String password) — статический (как и все методы класса DriverManager), поэтому обратиться к нему можно, не создавая никакого объекта — напрямую через имя класса:
Connection connection = DriverManager.getConnection("jdbc:firebirdsql:localhost/3050:D:\\data\\shopping.fdb", "SYSDBA", "masterkey");
Эта команда должна вернуть соединение с базой данных, хранящейся в файле D:\data\shopping.fdb, установленное от имени администратора SYSDBA с паролем masterkey.
Метод getConnection() возбуждает исключение класса SQLException, если соединение с требуемой базой данных не удается.
Заметим, что классы Connection, DriverManager и другие классы для работы с БД посредством JBDC-интерфейса содержатся в пакетах java.sql и javax.sql.
Программа учета домашних расходов должна уметь добавлять в базу данных информацию о новых товарах, их категориях, покупках и магазинах, а также извлекать из БД информацию, необходимую для построения различных отчетов.
Необходимо определить, какие классы программы будут отвественны за взаимодействие с базой данных. На первый взгляд достойными кандидатами являются:
Второй вариант, безусловно, более соответствует сущности объектно-ориентированного программирования, при котором каждый класс ответственен за хранение и обработку собственных данных. Однако и он имеет недостаток, а именно: код, взаимодействующий с базой данных, оказывается распределен по многим классам. В случае, если изменится структура базы данных, параметры соединения с ней или даже возникнет необходимость перевести программу на использование другой СУБД, придется изменять многие фрагменты программы, что всегда чревато скрытыми ошибками.
Есть третий вариант: ввести отдельный класс-посредник, чье единственное назначение — взаимодействие с базой данных. Остальные классы будут обращаться к БД, вызывая методы этого класса. Тогда весь код, в котором происходит работа с БД, окажется собран в одном месте программы и при необходимости можно будет изменять его, не затрагивая остальных классов.
Класс-посредник для взаимодействия с БД назовем DBManager. Все его поля и методы можно объявить статическими.
Для сохранения в БД новых данных класс DBManager должен иметь четыре метода: saveCategory(), saveShop(), saveGoods() и savePurchase(). Относительно же загрузки данных могут быть различные варианты. Наиболее простой с точки зрения программирования, хотя и не оптимальный с точки зрения эффективности — завести единственный метод loadData(), который будет вызываться в начале работы программы и загружать в память программы все содержимое БД, создавая объекты классов Category, Shop, Goods, Purchase.
Остановимся пока на этом варианте.
Заметим, что, поскольку обращение к БД осуществляется в каждом методе DBManager, в начале каждого метода понадобится устанавливать соединение описанным выше способом. Напрашивается мысль о том, чтобы выделить эти действия в отдельный вспомогательный метод класса DBManager.
Более того, возникает вопрос: а действительно ли каждый раз следует устанавливать соединение? Что если пользователь ввел в программу описание нескольких, скажем, товаров и нажал кнопку «Сохранить»? Очевидно, в этом случае метод saveGoods() будет вызываться в цикле несколько раз подряд и каждый раз снова соединяться с БД абсолютно неэффективно.
Поэтому используем достаточно распространенный прием программирования. Заведем отдельное поле, которое будет хранить объект класса Connection — текущее соединение с базой данных. Кроме того, создадим вспомогательный метод getConnection(), который будет устанавливать соединение только если оно не было установлено ранее, а иначе — возвращать объект, созданный ранее.
Таким образом, класс DBManager будет выглядеть следующим образом:
public class DBManager {private static final String dataSource ="jdbc:firebirdsql:localhost/3050:D:\\data\\shopping.fdb";private static final String userID = "sysdba";private static final String password = "masterkey";private static final String driverClass = "org.firebirdsql.jdbc.FBDriver";
private static Connection connection = null;
private static Connection getConnection(){
try {
if (connection == null || connection.isClosed()) {
Class.forName(driverClass);
connection = DriverManager.getConnection(dataSource, userID, password);
}}
catch (SQLException exception) {JoptionPane.showMessageDialog(null, exception.getMessage());}
catch (ClassNotFoundException exception) {JoptionPane.showMessageDialog(null, exception.getMessage());}
return connection;
}// МЕТОДЫ ДЛЯ СОХРАНЕНИЯ И ЗАГРУЗКИ ДАННЫХ...}
Мы объявили параметры подключения к БД строковыми константами, что улучшило наглядность нашего кода, и ввели поле connection для хранения текущего подключения (изначально равно null). В методе getConnection() проверяется, существует ли подключение и не было ли оно по какой-то причине закрыто. Последняя проверка осуществляется методом isClosed() класса Connection. Обратите внимание, ошибки разыменовывания нулевого указателя в строке
if (connection == null || connection.isClosed()) {
произойти не может, поскольку логический оператор «или» || будет выполнять вызов connection.isClosed() только в том случае, если первая часть условия connection == null ложна. А иначе логическое выражение в скобках сразу получит значение true и до второй его части дело не дойдет. Именно этим оператор || отличается от оператора | (см. главу 1).
Для направления SQL-запросов к БД необходимо создать объект класса Statement. Для этого следует вызвать метод createStatement() у объекта Connection, представляющего собой активное соединение с базой данных.
В простых программах используется метод createStatement() без параметров. Но для профессиональной работы с базами данных рекомендуется ознакомиться с более мощным вариантом этого метода с тремя параметрами.
Чтобы отправить SQL-запрос типа UPDATE, INSERT или DELETE (а также команды CREATE TABLE и DROP TABLE), используется метод executeUpdate(String query), параметром которого и является строка запроса.
Например, чтобы добавить в таблицу CATEGORIES категорию «Игрушки» (не имеющую родительской категории), можно выполнить команду:
statement.executeUpdate("INSERT INTO CATEGORIES (NAME, PARENT_CATEGORY) VALUES ('Пампушки', NULL)");
где statement — предварительно созданный объект класса Statement.
Разумеется, такая жестко прописанная команда не имеет смысла. Нам нужен метод saveCategory(), который будет сохранять в БД произвольную категорию, передаваемую ему в качестве параметра. Для того, чтобы это было возможно, класс Category должен иметь методы:
getName() — возвращает имя категории;
getParent() — возвращает ссылку на родительскую категорию или null, если таковой нет
getID() — возвращает значение первичного ключа данной категории в базе данных. Не зная этого значения сохранить связь с родительской категорией будет невозможно.
Код метода будет выглядеть следующим образом:
public static void saveCategory(Category category){
try {
Statement statement = getConnection().createStatement();
String parentID;
if (category.getCategory() == null) parentID = "NULL";
else parentID = category.getCategory().getID();
String query = "INSERT INTO CATEGORIES (NAME, PARENT_CATEGORY) VALUES ('" +category.getName() + "', " + parentID + ");";statement.executeUpdate(query);}
catch (SQLException exception) {
JoptionPane.showMessageDialog(null, exception.getMessage());
}
}
Как видно из примера, метод executeUpdate() возбуждает исключение SQLException, и это следует предусмотреть.
Для того, чтобы извлечь из БД информацию, используется SQL-запрос типа SELECT. Результатом его выполнения всегда является таблица. В простейшем случае она может совпадать с одной из таблиц хранящихся в БД (например, запрос SELECT * FROM CATEGORIES вернет таблицу CATEGORIES целиком).
SQL-запрос типа SELECT направляется базе данных из Java-программы методом executeQuery(String query) класса Statement. Параметром метода является строка, содержащая SQL-запрос.
Метод executeQuery() возвращает результат типа ResultSet, представляющий собой набор строк результирующей таблицы, а также курсор, указывающий на одну из этих строк.
Изначально курсор не показывает никуда. Его можно передвинуть на первую строку результата, вызвав метод next(). Следующий вызов метода next() передвинет курсор на вторую строку и так далее, до тех пор, пока строки не закончатся. После этого вызов метода next() приведет к ошибке.
Метод next() возвращает true, если переход курсора на новую строку осуществлен удачно и false, если строки кончились.
Таким образом, все строки результата выполнения запроса SELECT легко перебрать в цикле while следующего вида:
// query — некоторый запрос типа SELECT
ResultSet rs = statement.executeQuery(query);
while (rs.next()) {
// обработка очередной строки результатов запроса
}
Строка, на которую указывает курсор, может быть обработана. А именно: зная имя и тип данных столбца результирующей таблицы, можно извлечь данные из ячейки, находящейся на пересечении этого столбца и текущей строки.
Для этого в классе ResultSet определено множество методов, возвращающих результат определенного типа: getInt(), getString(), getDate(), универсальный метод getObject() и т.д. Параметром этих методов может являться строка — имя столбца или число, обозначающее порядковый номер столбца в результирующей таблице (начиная с нуля).
Пусть, например, метод loadData() должен загружать из БД наименования всех категорий товаров и помещать их в список List. Тогда код этого метода может быть следующим:
public static List loadData(){
try {
List result = new Vector();
Statement statement = getConnection().createStatement();
ResultSet rs = statement.executeQuery("SELECT * FROM CATEGORIES");
while (rs.next()) {
String categoryName = rs.getString("NAME");result.add(categoryName);
}
return result;
} catch (SQLException exception)
{
JoptionPane.showMessageDialog(null, exception.getMessage());
}return null;
// Если произошло исключение, список не возвращается
}
Следует учитывать следующий важный факт: один объект Statement может поддерживать не более одного объекта ResultSet. При следующем вызове метода executeQuery() предыдущий ResultSet будет закрыт и попытка выполнить метод next() или любой из методов get как раз приведет к генерации исключения SQLException.
На практике используются фреймворки с ORM, которые ускоряют и упрощают разработку, т.к. чистые запросы при этом пишутся крайне редко
Исследование, описанное в статье про базы данных в java, подчеркивает ее значимость в современном мире. Надеюсь, что теперь ты понял что такое базы данных в java и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории ООП и практические JAVA
Комментарии
Оставить комментарий
ООП и практические JAVA
Термины: ООП и практические JAVA