Лекция
Привет, сегодня поговорим про поиск ассоциативных правил, обещаю рассказать все что знаю. Для того чтобы лучше понимать что такое поиск ассоциативных правил, rules mining , настоятельно рекомендую прочитать все из категории Интеллектуальный анализ данных.
Выполнена постановка задачи. Рассмотренные формы представления результатов (правила классификации, дерева классификации, математические функции), методом ди построения правил классификации (алгоритм построения правил, метод Naive Bayes), а также методы построения деревьев классификации (методика
"разделяй и властвуй", алгоритм покрытия), методы построения математических функций (общий вид, линейные методы, метод наименьших квадратов, нелинейные методы, Support Vector Machines (SVM), регуляризацийни сети (Regularization Networks), дискретизации и редкие сетки). рассмотрена постановлением
новка задачи поиска ассоциативных правил (формальная постановка задачи, секвенциального анализ, разновидности задач поиска ассоциативных правил),
алгоритмы (алгоритм Apriori, разновидность алгоритма Apriori).
ПЛАН
1 Постановка задачи.
2 Представление результатов (правила классификации, дерева классификации, математические функции).
3 Методы построения правил классификации (алгоритм построения пра вил, метод Naive Bayes).
4 Методы построения деревьев классификации (методика "разделяй и влавствуй ", алгоритм покрытия).
5 Методы построения математических функций (общий вид, линейные методы, метод наименьших квадратов, нелинейные методы, Support Vector
Machines (SVM), регуляризацийни сети (Regularization Networks), дискриминации кретизации и редкие сетки).
6 Постановка задачи поиска ассоциативных правил (формальная постановка задачи, секвенциального анализ, разновидности задачи поиска асоцианых правил).
7 Представление результатов.
8 Алгоритмы (алгоритм Apriori, разновидности алгоритма Apriori).
Одной из наиболее распространенных задач анализа данных является определение часто встречающихся наборов объектов в большом множестве наборов.
Опишем эту задачу в обобщенном виде. Для этого обозначим объекты, составляющие исследуемые наборы (itemsets), следующим множеством:
I = {i1, i2 ,..., i j ,..., in},
где i j — объекты, входящие в анализируемые наборы; n — общее количество объектов.
В сфере торговли, например, такими объектами являются товары, представленные в прайс-листе (табл. 6.1).
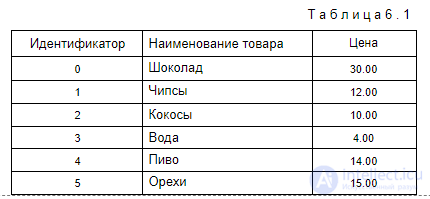
Они соответствуют следующему множеству объектов:
I = {шоколад, чипсы, кокосы, вода, пиво, орехи}.
Наборы объектов из множества I, хранящиеся в БД и подвергаемые анализу, называются транзакциями. Опишем транзакцию как подмножество множества I:
T ={ij | ii I}.
Такие транзакции в магазине соответствуют наборам товаров, покупаемых потребителем и сохраняемых в БД в виде товарного чека или накладной. В них перечисляются приобретаемые покупателем товары, их цена, количество и др. Например, следующие транзакции соответствуют покупкам, совершаемым потребителями в супермаркете:
T1 = {чипсы, вода, пиво};
T2 = {кокосы, вода, орехи}.
Набор транзакций, информация о которых доступна для анализа, обозначим следующим множеством:
D ={T1,T2 ,...,Tr ,...,Tm} ,
где m — количество доступных для анализа транзакций.
Например, в магазине таким множеством будет:
D = {{чипсы, вода, пиво},
{кокосы, вода, орехи},
{орехи, кокосы, чипсы, кокосы, вода},
{кокосы, орехи, кокосы}}.
Для использования методов Data Mining множество D может быть представлено в виде табл. 6.2.
Т а б л и ц а 6 . 2
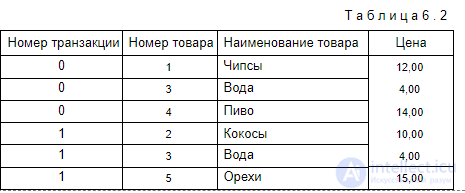

Множество транзакций, в которые входит объект i j , обозначим следующим образом:
Dij ={Tr | ij Tr ; j =1..n; r =1..m} D.
В данном примере множеством транзакций, содержащих объект вода, является следующее множество:
Dвода = {{чипсы, вода, пиво},
{кокосы, вода, орехи},
{орехи, кокосы, чипсы, кокосы, вода}}.
Некоторый произвольный набор объектов (itemset) обозначим следующим образом:
F = {ij | ij I; j =1..n}.
Например,
F = {кокосы, вода}.
Набор, состоящий из k объектов, называется k-элементным набором (в данном примере это 2-элементный набор).
Множество транзакций, в которые входит набор F , обозначим следующим образом:
DF ={Tr | F Tr ; r =1..m} D.
В данном примере:
D{кокосы, вода} = {{кокосы, вода, орехи},
{орехи, кокосы, чипсы, кокосы, вода}}.

Отношение количества транзакций, в которое входит набор F , к общему количеству транзакций называется поддержкой (support) набора F и обозначается Supp(F) :
Supp(F) = | DF | .
| D |
Для набора {кокосы, вода} поддержка будет равна 0,5, т. к. данный набор входит в две транзакции (с номерами 1 и 2), а всего транзакций 4.
При поиске аналитик может указать минимальное значение поддержки интересующих его наборов Suppmin . Набор называется частым (large itemset), если значение его поддержки больше минимального значения поддержки, заданного пользователем:
Supp(F) > Suppmin .
Таким образом, при поиске ассоциативных правил требуется найти множество всех частых наборов:
L= { F |Supp(F) > Suppmin} .
Вданном примере частыми наборами при Suppmin = 0,5 являются следующие:
{чипсы} Suppmin = 0,5; {чипсы, вода} Suppmin = 0,5; {кокосы} Suppmin = 0,75; {кокосы, вода} Suppmin = 0,5;
{кокосы, вода, орехи} Suppmin = 0,5;
{кокосы, орехи} Suppmin = 0,75; {вода} Suppmin = 0,75; {вода, орехи} Suppmin = 0,5; {орехи} Suppmin = 0,75.
При анализе часто вызывает интерес последовательность происходящих событий. При обнаружении закономерностей в таких последовательностях можно с некоторой долей вероятности предсказывать появление событий в будущем, что позволяет принимать более правильные решения.
Последовательностью называется упорядоченное множество объектов. Для этого на множестве должно быть задано отношение порядка.
Тогда последовательность объектов можно описать в следующем виде:
S = {..., ip , ..., iq} , где p < q .
Например, в случае с покупками в магазинах таким отношением порядка может выступать время покупок. Тогда последовательность
S = {(вода, 02.03.2003), (чипсы, 05.03.2003), (пиво, 10.03.2003)}
можно интерпретировать как покупки, совершаемые одним человеком в разное время (вначале была куплена вода, затем чипсы, а потом пиво).
Различают два вида последовательностей: с циклами и без циклов. В первом случае допускается вхождение в последовательность одного и того же объекта на разных позициях:
S = {..., ip , ..., iq , ...}, где p < q, iq = ip.
Говорят, что транзакция T содержит последовательность S , если S T и объекты, входящие в S, входят и в множество Т с сохранением отношения порядка. При этом допускается, что в множестве Т между объектами из последовательности S могут находиться другие объекты.
Поддержкой последовательности S называется отношение количества транзакций, в которое входит последовательность S, к общему количеству транзакций. Последовательность является частой, если ее поддержка превышает минимальную поддержку, заданную пользователем:
Supp(S) > Suppmin .
Задачей секвенциального анализа является поиск всех частых последовательностей:
L = {S |Supp(S) > Suppmin} .
Основным отличием задачи секвенциального анализа от поиска ассоциативных правил является установление отношения порядка между объектами множества I. Данное отношение может быть определено разными способами. При анализе последовательности событий, происходящих во времени, объектами множества I являются события, а отношение порядка соответствует хронологии их появления.
Например, при анализе последовательности покупок в супермаркете наборами являются покупки, совершаемые в разное время одними и теми же покупателями, а отношением порядка в них является хронология покупок:
D = {{(вода), (пиво)},
{(кокосы, вода), (пиво), (вода, шоколад, кокосы)},
{(пиво, чипсы, вода), (пиво)}}.
Естественно, что в этом случае возникает проблема идентификации покупателей. На практике она решается введением дисконтных карт, имеющих уникальный идентификатор. Данное множество можно представить в виде табл. 6.3.

Интерпретировать такую последовательность можно следующим образом: покупатель с идентификатором 1 вначале купил кокосы и воду, затем купил пиво, в последний раз он купил воду, шоколад и кокосы.
Поддержка, например, последовательности {(пиво), (вода)} составит 2/3, т. к. она встречается у покупателей с идентификаторами 0 и 1. У последнего покупателя также встречается набор {(пиво), (вода)}, но не сохраняется последовательность (он купил вначале воду, а затем пиво).
Cеквенциальный анализ актуален и для телекоммуникационных компаний. Основная проблема, для решения которой он используется, — это анализ данных об авариях на различных узлах телекоммуникационной сети. Информация о последовательности совершения аварий может помочь в обнаружении неполадок и предупреждении новых аварий. Данные для такого анализа могут быть представлены, например, в виде табл. 6.4.
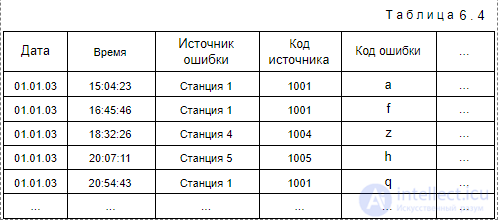
В данной задаче объектами множества I являются коды ошибок, возникающих в процессе работы телекоммуникационной сети. Последовательность Ssid содержит сбои, происходящие на станции с идентификатором sid. Их можно представить в виде пар (eid , t) , где eid — код ошибки, а t — время,
когда она произошла. Таким образом, последовательность сбоев на станции с идентификатором sid будет иметь следующий вид:
Ssid = {(eid1, t1), (eid2 , t2 ), ..., (eidn , tn )}.
Для данных, приведенных в табл. 6.4, транзакции будут следующие:
T1001 = {(a, 15:04:23 01.01.03), (f, 16:45:46 01.01.03), (q, 20:54:43 01.01.03), ... }; T1004 = {(z, 18:32:26 01.01.03), ... };
T1005 = {(h, 20:07:11 01.01.03), ... }.
Отношение порядка в данном случае задается относительно времени появления ошибки (значения t ).
|
(A, 0:12) |
|
(C, 0:25) (A, 0:38) |
|
(D, 0:53) |
|
(A, 1:25) |
|
(C, 1:42) |
(C, 1:51) |
|||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
0:00 |
0:15 |
0:30 |
0:45 |
1:00 |
1:15 |
1:30 |
1:45 |
2:00 |
||||||||
Рис. 6.1. Последовательность сбоев на телекоммуникационной станции
При анализе такой последовательности важным является определение интервала времени между сбоями. Оно позволяет предсказать момент и характер новых сбоев, а следовательно, предпринять профилактические меры. По этой причине при анализе данных интерес вызывает не просто последовательность событий, а сбои, которые происходят друг за другом. Например, на рис. 6.1 изображена временная шкала последовательности сбоев, происходящих на одной станции. При определении поддержки, например, для последовательности {A, C} учитываются только следующие наборы: {(A, 0:12), (C, 0:25)}, {(A, 0:38), (C, 1:42)}, {(A, 1:25), (C, 1:42)}. При этом не учитываются следующие последовательности: {(A, 0:12), (C, 1:42)}, {(A, 0:12), (C, 1:51)}, {(A, 0:38), (C, 1:51)} и {(A, 1:25), (C, 1:51)}, т. к. они не следуют непосредственно друг за другом.
Во многих прикладных областях объекты множества I естественным образом объединяются в группы, которые в свою очередь также могут объединяться в более общие группы, и т. д. Таким образом, получается иерархическая структура объектов, представленная на рис. 6.2.
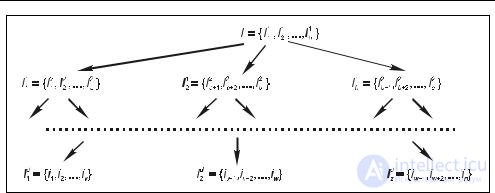
|
|
|
|
Рис. 6.2. Иерархическое представление объектов множества I |
|
Для примера, приведенного в табл. 6.1, такой иерархии может быть следующая категоризация товаров:
|
напитки; |
еда; |
|||
|
• |
алкогольные; |
• |
шоколад; |
|
|
|
|
пиво; |
• |
чипсы; |
|
• |
безалкогольные; |
• |
кокосы; |
|
|
|
|
вода; |
• |
орехи. |
Наличие иерархии изменяет представление о том, когда объект i присутствует в транзакции T . Об этом говорит сайт https://intellect.icu . Очевидно, что поддержка не отдельного объекта, а группы, в которую он входит, больше:
Supp(Iqg ) ≥ Supp(i j ),
где i j Iqg .
Это связано с тем, что при анализе групп подсчитываются не только транзакции, в которые входит отдельный объект, но и транзакции, содержащие все объекты анализируемой группы. Например, если поддержка Supp{кокосы, вода} = 2/4, то поддержка Supp{еда, напитки} = 2/4, т. к. объекты групп еда и напитки входят в транзакции с идентификаторами 0, 1 и 2.
Использование иерархии позволяет определить связи, входящие в более высокие уровни иерархии, поскольку поддержка набора может увеличиваться, если подсчитывается вхождение группы, а не ее объекта. Кроме поиска наборов, часто встречающихся в транзакциях, состоящих из объектов F = {i | i I}
или групп одного уровня иерархии F = {I g | I g I g+1}, можно рассматривать
|
также смешанные наборы объектов и групп |
F = {i, I g | i I g I g+1} . Это по- |
зволяет расширить анализ и получить дополнительные знания.
При иерархическом построении объектов можно варьировать характер поиска изменяя анализируемый уровень. Очевидно, что чем больше объектов во множестве I, тем больше объектов в транзакциях Т и частых наборах. Это в свою очередь увеличивает время поиска и усложняет анализ результатов. Уменьшить или увеличить количество данных можно с помощью иерархического представления анализируемых объектов. Перемещаясь вверх по иерархии, обобщаем данные и уменьшаем их количество, и наоборот.
Недостатком обобщения объектов является меньшая полезность полученных знаний, т. к. в этом случае они относятся к группам товаров, что не всегда приемлемо. Для достижения компромисса между анализом групп и анализом отдельных объектов часто поступают следующим образом: сначала анализируют группы, а затем, в зависимости от полученных результатов, исследуют объекты заинтересовавших аналитика групп. В любом случае можно утверждать, что наличие иерархии в объектах и ее использование в задаче поиска ассоциативных правил позволяет выполнять более гибкий анализ и получать дополнительные знания.
В рассмотренной задаче поиска ассоциативных правил наличие объекта в транзакции определялось только его присутствием в ней (ij T ) или отсут-
ствием (ij T ) . Часто объекты имеют дополнительные атрибуты, как прави-
ло, численные. Например, товары в транзакции имеют атрибуты: цена и количество. При этом наличие объекта в наборе может определяться не просто фактом его присутствия, а выполнением условия по отношению к определенному атрибуту. Например, при анализе транзакций, совершаемых покупателем, может интересовать не просто наличие покупаемого товара, а товара, покупаемого по некоторой цене.
Для расширения возможностей анализа с помощью поиска ассоциативных правил в исследуемые наборы можно добавлять дополнительные объекты. В общем случае они могут иметь природу, отличную от основных объектов. Например, для определения товаров, имеющих больший спрос в зависимости от месторасположения магазина, в транзакции можно добавить объект, характеризующий район.
Решение задачи поиска ассоциативных правил, как и любой задачи, сводится к обработке исходных данных и получению результатов. Обработка над исходными данными выполняется по некоторому алгоритму Data Mining.
Результаты, получаемые при решении этой задачи, принято представлять в виде ассоциативных правил. В связи с этим при их поиске выделяют два основных этапа:
нахождение всех частых наборов объектов;
генерация ассоциативных правил из найденных частых наборов объектов. Ассоциативные правила имеют следующий вид:
если (условие) то (результат)
где условие — обычно не логическое выражение (как в классификационных правилах), а набор объектов из множества I , с которыми связаны (ассоциированы) объекты, включенные в результат данного правила.
Например, ассоциативное правило:
если (кокосы, вода) то (орехи)
означает, что если потребитель покупает кокосы и воду, то он покупает и орехи.
Как уже отмечалось, в ассоциативных правилах условие и результат являются объектами множества I :
если X то Y
где X I,Y I, X Y = φ .
Ассоциативное правило можно представить как импликацию над множеством X Y , где X I,Y I, X Y = φ .
Основным достоинством ассоциативных правил является их легкое восприятие человеком и простая интерпретация языками программирования. Однако они не всегда полезны. Выделяют три вида правил:
полезные правила — содержат действительную информацию, которая ранее была неизвестна, но имеет логичное объяснение. Такие правила могут быть использованы для принятия решений, приносящих выгоду;
тривиальные правила — содержат действительную и легко объяснимую информацию, которая уже известна. Такие правила, хотя и объяснимы, но не могут принести какой-либо пользы, т. к. отражают или известные законы в исследуемой области, или результаты прошлой деятельности. Иногда такие правила могут использоваться для проверки выполнения решений, принятых на основании предыдущего анализа;
непонятные правила — содержат информацию, которая не может быть объяснена. Такие правила могут быть получены или на основе аномальных значений, или глубоко скрытых знаний. Напрямую такие правила нельзя использовать для принятия решений, т. к. их необъяснимость может привести к непредсказуемым результатам. Для лучшего понимания требуется дополнительный анализ.

Ассоциативные правила строятся на основе частых наборов. Так, правила, построенные на основании набора F (т. е. X Y = F ), являются всеми возможными комбинациями объектов, входящих в него.
Например, для набора {кокосы, вода, орехи} могут быть построены следующие правила:
если (кокосы) то (вода); если (кокосы) то (орехи);
если (кокосы) то (вода, орехи); если (вода, орехи) то (кокосы); если (вода) то (кокосы); если (вода) то (орехи);
если (вода) то (кокосы, орехи); если (кокосы, орехи) то (вода); если (орехи) то (вода); если (орехи) то (кокосы);
если (орехи) то (вода, кокосы); если (вода, кокосы) то (орехи).
Таким образом, количество ассоциативных правил может быть очень большим и трудновоспринимаемым для человека. К тому же, не все из построенных правил несут в себе полезную информацию. Для оценки их полезности вводятся следующие величины.
Поддержка (support) — показывает, какой процент транзакций поддерживает данное правило. Так как правило строится на основании набора, то, значит, правило X Y имеет поддержку, равную поддержке набора F , который составляют X и Y :
SuppX Y = SuppF = | DF =X Y | . | D |
Очевидно, что правила, построенные на основании одного и того же набора, имеют одинаковую поддержку, например, поддержка
Supp если (вода, кокосы) то (орехи) = Supp {вода, кокосы, орехи} = 2/4.
Достоверность (confidence) — показывает вероятность того, что из наличия в транзакции набора X следует наличие в ней набора Y . Достоверностью правила X Y является отношение числа транзакций, содержащих наборы X и Y , к числу транзакций, содержащих набор X :
|
ConfX Y |
= |
| DF =X |
Y | |
= |
SuppX Y |
. |
|
|
|
|
||||
|
|
|
| DX |
| |
|
SuppX |
|
Очевидно, что чем больше достоверность, тем правило лучше, причем у правил, построенных на основании одного и того же набора, достоверность будет разная, например:
Conf если (вода) то (орехи) = 2/3;
Conf если (орехи) то (вода) = 2/3;

Conf если (вода, кокосы) то (орехи) = 1;
Conf если (вода) то (орехи, кокосы) = 2/3.
К сожалению, достоверность не позволяет оценить полезность правила. Если процент наличия в транзакциях набора Y при условии наличия в них набора X меньше, чем процент безусловного наличия набора Y , т. е.:
ConfX Y = SuppX Y < SuppY ,
SuppX
это значит, что вероятность случайно угадать наличие в транзакции набора Y больше, чем предсказать это с помощью правила X Y . Для исправления такой ситуации вводится мера — улучшение.
Улучшение (improvement) — показывает, полезнее ли правило случайного угадывания. Улучшение правила является отношением числа транзакций, содержащих наборы X и Y , к произведению количества транзакций, содержащих набор X , и количества транзакций, содержащих набор Y :
|
imprX Y |
= |
| DF |
=X Y |
| |
= |
SuppX Y |
. |
|
|
|
|
|
||||
|
|
|
| DX |
|| DY |
| |
|
SuppX ·SuppY |
|
Например,
imprесли (вода, кокосы) то (орехи) = 0,5/(0,5·0,5) = 2.
Если улучшение больше единицы, то это значит, что с помощью правила предсказать наличие набора Y вероятнее, чем случайное угадывание, если меньше единицы, то наоборот.
В последнем случае можно использовать отрицающее правило, т. е. правило, которое предсказывает отсутствие набора Y :
Xне Y.
Утакого правила улучшение будет больше единицы, т. к. Suppне Y =1−SuppY .
Таким образом, можно получить правило, которое предсказывает результат лучше, чем случайным образом. Правда, на практике такие правила мало применимы. Например, правило:
если (вода, орехи) то не пиво
мало полезно, т. к. слабо выражает поведение покупателя.
Данные оценки используются при генерации правил. Аналитик при поиске ассоциативных правил задает минимальные значения перечисленных величин. В результате те правила, которые не удовлетворяют этим условиям, отбрасываются и не включаются в решение задачи. С этой точки зрения нельзя
объединять разные правила, хотя и имеющие общую смысловую нагрузку. Например, следующие правила:
X ={i1, i2} Y ={i3} ,
X ={i1, i2} Y ={i4}
нельзя объединить в одно:
X={i1, i2} Y ={i3, i4} ,
т.к. достоверности их будут разные, следовательно, некоторые из них могут быть исключены, а некоторые — нет.
Если объекты имеют дополнительные атрибуты, которые влияют на состав объектов в транзакциях, а следовательно, и в наборах, то они должны учитываться в генерируемых правилах. В этом случае условная часть правил будет содержать не только проверку наличия объекта в транзакции, но и более сложные операции сравнения: больше, меньше, включает и др. Результирующая часть правил также может содержать утверждения относительно значений атрибутов. Например, если у товаров рассматривается цена, то правила могут иметь следующий вид:
если пиво.цена < 10 то чипсы.цена < 7.
Данное правило говорит о том, что если покупается пиво по цене меньше 10 р., то, вероятно, будут куплены чипсы по цене меньше 7 р.
Выявление частых наборов объектов — операция, требующая большого количества вычислений, а следовательно, и времени. Алгоритм Apriori описан в 1994 г. Срикантом Рамакришнан (Ramakrishnan Srikant) и Ракешом Агравалом (Rakesh Agrawal). Он использует одно из свойств поддержки, гласящее: поддержка любого набора объектов не может превышать минимальной поддержки любого из его подмножеств:
SuppF ≤ SuppE при E F.
Например, поддержка 3-объектного набора {пиво, вода, чипсы} будет всегда меньше или равна поддержке 2-объектных наборов {пиво, вода}, {вода, чипсы}, {пиво, чипсы}. Это объясняется тем, что любая транзакция, содержащая {пиво, вода, чипсы}, содержит также и наборы {пиво, вода}, {вода, чипсы}, {пиво, чипсы}, причем обратное неверно.
Алгоритм Apriori определяет часто встречающиеся наборы за несколько этапов. На i -м этапе определяются все часто встречающиеся i -элементные наборы. Каждый этап состоит из двух шагов: формирования кандидатов (candidate generation) и подсчета поддержки кандидатов (candidate counting).
Рассмотрим i -й этап. На шаге формирования кандидатов алгоритм создает множество кандидатов из i -элементных наборов, чья поддержка пока не вычисляется. На шаге подсчета кандидатов алгоритм сканирует множество транзакций, вычисляя поддержку наборов-кандидатов. После сканирования отбрасываются кандидаты, поддержка которых меньше определенного пользователем минимума, и сохраняются только часто встречающиеся i -элемент- ные наборы. Во время 1-го этапа выбранное множество наборов-кандидатов содержит все 1-элементные частые наборы. Алгоритм вычисляет их поддержку во время шага подсчета кандидатов.
Описанный алгоритм можно записать в виде следующего псевдокода:
L1 = {часто встречающиеся 1-элементные наборы} для (k=2; Lk-1 <> φ; k++)
Ck = Apriorigen(Fk-1) // генерация кандидатов для всех транзакций t D выполнить
Ct = subset(Ck, t) // удаление избыточных правил для всех кандидатов c Ct выполнить
c.count ++ конец для всех
конец для всех
Lk = { c Ck | c.count >= Suppmin} // отбор кандидатов конец для
Результат = Lk k
Опишем обозначения, используемые в алгоритме:
Lk — множество k-элементных частых наборов, чья поддержка не меньше заданной пользователем. Каждый член множества имеет набор упорядоченных ( i j < ip , если j < p ) элементов F и значение поддержки набора
SuppF > Suppmin :
Lk = {(F1,Supp1), (F2 ,Supp2 ), ..., (Fq ,Suppq )},
где Fj = {i1, i2 ,..., ik } ;
Ck — множество кандидатов k -элементных наборов потенциально частых. Каждый член множества имеет набор упорядоченных ( i j < ip , если j < p ) элементов F и значение поддержки набора Supp .
|
|
|
|
Опишем данный алгоритм по шагам. |
|
|
Øàã 1. Присвоить k = 1 и выполнить |
отбор всех 1-элементных наборов, |
у которых поддержка больше минимально заданной пользователем Suppmin .
Øàã 2. k = k +1.
Øàã 3. Если не удается создавать k-элементные наборы, то завершить алгоритм, иначе выполнить следующий шаг.
Øàã 4. Создать множество k-элементных наборов кандидатов в частые наборы. Для этого необходимо объединить в k-элементные кандидаты (k – 1)- элементные частые наборы. Каждый кандидат c Ck будет формироваться
путем добавления к (k – 1)-элементному частому набору — p элемента из другого (k – 1)-элементного частого набора — q. Причем добавляется последний элемент набора q, который по порядку выше, чем последний элемент набора p (p.itemk–1 < q.itemk–1). При этом первые все (k – 2) элемента обоих наборов одинаковы (p.item1 = q.item1, p.item2 = q.item2, ...,
p.itemk–2 = q.itemk–2).
Это может быть записано в виде следующего SQL-подобного запроса.
insert into Ck
select p.item1, p.item2, ..., p.itemk-1, q.itemk-1 from Lk-1 p, Lk-1 q
where p.item1 = q.item1, p.item2 = q.item2, ..., p.itemk-2 = q.itemk-2, p.itemk-1 < q.itemk-1
Øàã 5. Для каждой транзакции Т из множества D выбрать кандидатов Ct из множества Ck , присутствующих в транзакции Т. Для каждого набора из построенного множества Ck удалить набор, если хотя бы одно из его (k – 1) подмножеств не является часто встречающимся, т. е. отсутствует во множе-
стве Lk 1 . Это можно записать в виде следующего псевдокода:
−
для всех наборов c Ck выполнить
для всех (k-1) – поднаборов s из c выполнить
если (s Lk-1) то удалить c из Ck
Øàã 6. Для каждого кандидата из множества Ck увеличить значение поддержки на единицу.
Øàã 7. Выбрать только кандидатов Lk из множества Ck , у которых значение поддержки больше заданной пользователем Suppmin . Вернуться к шагу 2.
Результатом работы алгоритма является объединение всех множеств Lk для всех k.
Рассмотрим работу алгоритма на примере, приведенном в табл. 6.1, при Suppmin = 0,5 . На первом шаге имеем следующее множество кандидатов C1 (указываются идентификаторы товаров) (табл. 6.5).
|
|
|
Т а б л и ц а 6 . 5 |
|
|
|
|
|
№ |
Набор |
Supp |
|
|
|
|
|
1 |
{0} |
0 |
|
|
|
|
|
2 |
{1} |
0,5 |
|
|
|
|
|
3 |
{2} |
0,75 |
|
|
|
|
|
4 |
{4} |
0,25 |
|
|
|
|
|
5 |
{3} |
0,75 |
|
|
|
|
|
6 |
{5} |
0,75 |
|
|
|
|
Заданной минимальной поддержке удовлетворяют только кандидаты 2, 3, 5 и 6, следовательно:
L1 = {{1}, {2}, {3}, {5}}.
На втором шаге увеличиваем значение k до двух. Так как можно построить 2-элементные наборы, то получаем множество C2 (табл. 6.6).
|
|
|
Т а б л и ц а 6 . 6 |
|
|
|
|
|
№ |
Набор |
Supp |
|
|
|
|
|
1 |
{1, 2} |
0,25 |
|
|
|
|
|
2 |
{1, 3} |
0,5 |
|
|
|
|
|
3 |
{1, 5} |
0,25 |
|
|
|
|
|
4 |
{2, 3} |
0,5 |
|
|
|
|
|
5 |
{2, 5} |
0,75 |
|
|
|
|
|
6 |
{3, 5} |
0,5 |
|
|
|
|
Из построенных кандидатов заданной минимальной поддержке удовлетворяют только кандидаты 2, 4, 5 и 6, следовательно:
L2 = {{1, 3}, {2, 3}, {2, 5}, {3, 5}}.
На третьем шаге перейдем к созданию 3-элементных кандидатов и подсчету их поддержки. В результате получим следующее множество C3 (табл. 6.7).
|
156 |
|
|
Глава 6 |
|
|
|
|
|
Т а б л и ц а 6 . 7 |
|
|
|
|
|
|
|
|
|
№ |
Набор |
Supp |
|
|
|
|
|
|
|
|
|
1 |
{2, 3, 5} |
0,5 |
|
|
|
|
|
|
|
Данный набор удовлетворяет минимальной поддержке, следовательно:
L3 = {{2, 3, 5}}.
Так как 4-элементные наборы создать не удастся, то результатом работы алгоритма является множество:
L = L1 L2 L3 = {{1}, {2}, {3}, {5}, {1, 3}, {2, 3}, {2, 5}, {3, 5}, {2, 3, 5}}.
Для подсчета поддержки кандидатов нужно сравнить каждую транзакцию с каждым кандидатом. Очевидно, что количество кандидатов может быть очень большим и нужен эффективный способ подсчета. Гораздо быстрее и эффективнее использовать подход, основанный на хранении кандидатов в хэш-дереве. Внутренние узлы дерева содержат хэш-таблицы с указателями на потомков, а листья — на кандидатов. Это дерево используется при быстром подсчете поддержки для кандидатов.
Хэш-дерево строится каждый раз, когда формируются кандидаты. Первоначально дерево состоит только из корня, который является листом, и не содержит никаких кандидатов-наборов. Каждый раз, когда формируется новый кандидат, он заносится в корень дерева, и так до тех пор, пока количество кандидатов в корне-листе не превысит некоего порога. Как только это происходит, корень преобразуется в хэш-таблицу, т. е. становится внутренним узлом, и для него создаются потомки-листья. Все кандидаты распределяются по узлам-потомкам согласно хэш-значениям элементов, входящих в набор. Каждый новый кандидат хэшируется на внутренних узлах, пока не достигнет первого узла-листа, где он и будет храниться, пока количество наборов опять же не превысит порога.
После того как хэш-дерево с кандидатами-наборами построено, легко подсчитать поддержку для каждого кандидата. Для этого нужно "пропустить" каждую транзакцию через дерево и увеличить счетчики для тех кандидатов, чьи элементы также содержатся и в транзакции, Ck ∩Ti = Ck . На корневом
уровне хэш-функция применяется к каждому объекту из транзакции. Далее, на втором уровне, хэш-функция применяется ко вторым объектам и т. д. На k-м уровне хэшируется k -элемент, и так до тех пор, пока не достигнем листа. Если кандидат, хранящийся в листе, является подмножеством рассматриваемой транзакции, увеличиваем счетчик поддержки этого кандидата на единицу.
После того как каждая транзакция из исходного набора данных "пропущена" через дерево, можно проверить, удовлетворяют ли значения поддержки кандидатов минимальному порогу. Кандидаты, для которых это условие выполняется, переносятся в разряд часто встречающихся. Кроме того, следует запомнить и поддержку набора, которая пригодится при извлечении правил. Эти же действия применяются для нахождения (k + 1)-элементных наборов и т. д.
Алгоритм AprioriTid является разновидностью алгоритма Apriori. Отличительной чертой данного алгоритма является подсчет значения поддержки
кандидатов не при сканировании множества D , а с помощью множества Ck ,
являющегося множеством кандидатов (k-элементных наборов) потенциально частых, в соответствие которым ставится идентификатор TID транзакций, в которых они содержатся.
Каждый член множества Ck является парой вида < TID, Fk > , где каждый Fk является потенциально частым k -элементным набором, представленным в
транзакции с идентификатором TID. Множество C1 = D соответствует множеству транзакций, хотя каждый объект в транзакции соответствует одно-
объектному набору в множестве C1 , содержащем этот объект. Для k >1
множество Ck генерируется в соответствии с алгоритмом, описанным ниже.
Член множества Ck , соответствующий транзакции Т, является парой следующего вида:
< T.TID,{c Ck | c T} > .
Подмножество наборов в Ck с одинаковыми TID (т. е. содержатся в одной и той же транзакции) называется записью. Если транзакция не содержит ни од-
ного k -элементного кандидата, то Ck не будет иметь записи для этой тран-
закции. То есть количество записей в Ck может быть меньше, чем в D , особенно для больших значений k . Кроме того, для больших значений k каждая запись может быть меньше, чем соответствующая ей транзакция, т. к. в транзакции будет содержаться мало кандидатов. Однако для малых значений k каждая запись может быть больше, чем соответствующая транзакция,
т. к. Ck включает всех кандидатов k-элементных наборов, содержащихся в транзакции.
Другой разновидностью алгоритма Apriori является алгоритм MSAP (Mining Sequential Alarm Patterns), специально разработанный для выполнения секвенциального анализа сбоев телекоммуникационной сети.
Он использует следующее свойство поддержки последовательностей: для любой последовательности Lk ее поддержка будет меньше, чем поддержка
последовательностей из множества Lk 1 .
−
Алгоритм MSAP для поиска событий, следующих друг за другом, использует понятие "срочного окна" (Urgent Window). Это позволяет выявлять не просто одинаковые последовательности событий, а следующие друг за другом. В остальном данный алгоритм работает по тому же принципу, что и Apriori.
Из материала, изложенного в данной главе, можно сделать следующие выводы.
Задачей поиска ассоциативных правил является определение часто встречающихся наборов объектов в большом множестве наборов.
Секвенциальный анализ заключается в поиске частых последовательностей. Основным отличием задачи секвенциального анализа от поиска ассоциативных правил является установление отношения порядка между объектами.
Наличие иерархии в объектах и ее использование в задаче поиска ассоциативных правил позволяет выполнять более гибкий анализ и получать дополнительные знания.
Результаты решения задачи представляются в виде ассоциативных правил, условная и заключительная часть которых содержит наборы объектов.
Основными характеристиками ассоциативных правил являются поддержка, достоверность и улучшение.
Поддержка (support) показывает, какой процент транзакций поддерживает данное правило.
Достоверность (confidence) показывает, какова вероятность того, что из наличия в транзакции набора условной части правила следует наличие в ней набора заключительной части.
Улучшение (improvement) показывает, полезнее ли правило случайного угадывания.
Задача поиска ассоциативных правил решается в два этапа. На первом выполняется поиск всех частых наборов объектов. На втором из найденных частых наборов объектов генерируются ассоциативные правила.
Алгоритм Apriori использует одно из свойств поддержки, гласящее: поддержка любого набора объектов не может превышать минимальной поддержки любого из его подмножеств.
К сожалению, в одной статье не просто дать все знания про поиск ассоциативных правил. Но я - старался. Если ты проявишь интерес к раскрытию подробностей,я обязательно напишу продолжение! Надеюсь, что теперь ты понял что такое поиск ассоциативных правил, rules mining и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Интеллектуальный анализ данных

Комментарии