Лекция
Привет, Вы узнаете о том , что такое стирание типа, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое стирание типа, вывод типов, утиная типизация, приведение типа , настоятельно рекомендую прочитать все из категории ООП и практические JAVA.
В языках программирования , тип стирание является время загрузки процесс , посредством которого явные аннотации типа удаляется из программы, прежде чем он будет выполнен на время выполнения . Операционная семантика, которая не требует, чтобы программы сопровождались типами, называется семантикой стирания типов , в отличие от семантики передачи типов . Возможность предоставления семантики стирания типа - это своего рода принцип абстракции , гарантирующий, что выполнение программы во время выполнения не зависит от информации о типе. В контексте универсального программирования противоположность стирания типа называется овеществление .
Обобщения проверяются на правильность типа во время компиляции. Затем информация об общем типе удаляется в процессе, называемом стиранием типа . Например, 
будет преобразован в неуниверсальный тип List, который обычно содержит произвольные объекты. Проверка во время компиляции гарантирует, что результирующий код является правильным по типу.
Из-за стирания типа параметры типа не могут быть определены во время выполнения. Например, когда ArrayList рассматривается во время выполнения, не существует общий способ , чтобы определить , является ли, до того типа стирания, это был 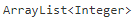
или  . Многих это ограничение не устраивает. Есть частичные подходы. Например, можно исследовать отдельные элементы, чтобы определить, к какому типу они принадлежат; например, если an
. Многих это ограничение не устраивает. Есть частичные подходы. Например, можно исследовать отдельные элементы, чтобы определить, к какому типу они принадлежат; например, если an ArrayList содержит Integer, то этот ArrayList мог быть параметризован Integer(однако он мог быть параметризован любым родительским элементом Integer, например Numberили Object).
Демонстрируя это, следующий код выводит "Equal":

Другой эффект стирания типа заключается в том, что универсальный класс не может расширять класс Throwable каким-либо образом, прямо или косвенно:

Причина, по которой это не поддерживается, связана со стиранием типа:

Из-за стирания типа среда выполнения не знает, какой блок catch выполнять, поэтому компилятор запрещает это.
Дженерики Java отличаются от шаблонов C ++ . Дженерики Java генерируют только одну скомпилированную версию универсального класса или функции независимо от количества используемых типов параметризации. Кроме того, среде выполнения Java не нужно знать, какой параметризованный тип используется, потому что информация о типе проверяется во время компиляции и не включается в скомпилированный код. Следовательно, создание экземпляра класса Java параметризованного типа невозможно, поскольку для создания экземпляра требуется вызов конструктора, который недоступен, если тип неизвестен.
Например, следующий код не может быть скомпилирован:

Поскольку во время выполнения существует только одна копия на универсальный класс, статические переменные используются всеми экземплярами класса независимо от их параметра типа. Следовательно, параметр типа нельзя использовать в объявлении статических переменных или в статических методах.
Обратная операция называется выводом типа . Хотя стирание типа может использоваться как простой способ определить типизацию на неявно типизированных языках (неявно типизированный термин хорошо типизирован тогда и только тогда, когда это стирание хорошо типизированного явно типизированного лямбда-термина ), это не всегда приводит к алгоритму проверки неявно типизированных терминов.
вывод типов (англ. type inference) — в программировании возможность компилятора самому логически вывести тип значения у выражения. Впервые механизм вывода типов был представлен в языке ML, где компилятор всегда выводит наиболее общий полиморфный тип для всякого выражения. Это не только сокращает размер исходного кода и повышает его лаконичность, но и нередко повышает повторное использование кода .
Вывод типов характерен для функциональных языков программирования, хотя со временем он был частично реализован и в объектно-ориентированных языках (C#, D, Visual Basic .NET, Nim, C++11, Vala, Java[a]), где ограничивается возможностью опустить тип идентификатора в определении с инициализацией (см. синтаксический сахар). Например:
var s = "Hello, world!"; // Тип переменной s (от string) выведен исходя из инициализатора
Алгоритм Хи́ндли — Ми́лнера — механизм вывода типов выражений, реализуемый в языках программирования, основанных на системе типов Хиндли — Милнера, таких как ML (первый язык этого семейства), Standard ML, OCaml, Haskell, F#, Fortress и Boo. Язык Nemerle использует этот алгоритм с рядом необходимых изменений .
Механизм вывода типов основан на возможности автоматически полностью или частично выводить тип выражения, полученного при помощи вычисления некоторого выражения. Так как этот процесс систематически производится во время трансляции программы, транслятор часто может вывести тип переменной или функции без явного указания типов этих объектов. Во многих случаях можно опускать явные декларации типов — это можно делать для достаточно простых объектов, либо для языков с простым синтаксисом. Например, в языке Haskell реализован достаточно мощный механизм вывода типов, поэтому указание типов функций в этом языке программирования не требуется. Программист может указать тип функции явно для того, чтобы ограничить ее использование только для конкретных типов данных, либо для более структурированного оформления исходного кода.
Для того, чтобы получить информацию для корректного вывода типа выражения в условиях отсутствия явной декларации типа этого выражения, транслятор либо собирает такую информацию из явных деклараций типов подвыражений (переменных, функций), входящих в изучаемое выражение, либо использует неявную информацию о типах атомарных значений. Такой алгоритм не всегда помогает определить тип выражения, особенно в случаях использования функций высших порядков и параметрического полиморфизма достаточно сложной природы. Поэтому в сложных случаях, когда есть необходимость избежать неоднозначностей, рекомендуется явно указывать тип выражений.
Сама модель типизации основана на алгоритме вывода типов выражений, который имеет своим источником механизм получения типов выражений, используемый в типизированном λ-исчислении, который был предложен в 1958 г. Х. Карри и Р. Фейсом. Далее уже́ Роджер Хиндли в 1969 г. расширил сам алгоритм и доказал, что он выводит наиболее общий тип выражения. В 1978 г. Робин Милнер независимо от Р. Хиндли доказал свойства эквивалентного алгоритма. И, наконец, в 1985 г. Луис Дамас окончательно показал, что алгоритм Милнера является законченным и может использоваться для полиморфных типов. В связи с этим алгоритм Хиндли — Милнера иногда называют также и алгоритмом Дамаса — Милнера.
Система типов определяется в модели Хиндли — Милнера следующим образом:
 являются типами выражений.
являются типами выражений. и
и  — типы выражений, то тип
— типы выражений, то тип  является типом выражений.
является типом выражений. является типом выражений.
является типом выражений.Выражения, типы которых вычисляются, определяются довольно стандартным образом:
 и
и  — выражения, то (
— выражения, то ( ) — выражение. — переменная, а
) — выражение. — переменная, а  — выражение, то
— выражение, то  — выражение.
— выражение.Говорят, что тип является экземпляром типа , когда имеется некое преобразование  такое, что:
такое, что:

При этом обычно полагается, что на преобразования типов накладываются ограничения, заключающиеся в том, что:


Сам алгоритм вывода типов состоит из двух шагов — генерация системы уравнений и последующее решение этих уравнений.
Построение системы уравнений основано на следующих правилах:
 — в том случае, если связывание
— в том случае, если связывание  находится в
находится в  .
. — в том случае, если
— в том случае, если  , где
, где  и
и  .
. — в том случае, если
— в том случае, если  , где
, где  это с добавленным связыванием .
это с добавленным связыванием .В этих правилах под символом {\displaystyle \Gamma } понимается набор связываний переменных с их типами:

Решение построенной системы уравнений основано на алгоритме унификации. Об этом говорит сайт https://intellect.icu . Это достаточно простой алгоритм. Имеется некоторая функция {\displaystyle u} , которая принимает на вход уравнение типов и возвращает подстановку, которая делает левую и правую части уравнения одинаковыми («унифицирует» их). Подстановка — это просто проекция переменных типов на сами типы. Такие подстановки могут вычисляться различными способами, которые зависят от конкретной реализации алгоритма Хиндли — Милнера.
, которая принимает на вход уравнение типов и возвращает подстановку, которая делает левую и правую части уравнения одинаковыми («унифицирует» их). Подстановка — это просто проекция переменных типов на сами типы. Такие подстановки могут вычисляться различными способами, которые зависят от конкретной реализации алгоритма Хиндли — Милнера.
Неявная типизация, латентная типизация или утиная типизация (англ. Duck typing) в ООП-языках — определение факта реализации определенного интерфейса объектом без явного указания или наследования этого интерфейса, а просто по реализации полного набора его методов.
Название термина пошло от английского «duck test» («утиный тест»), который в оригинале звучит как:
Если это выглядит как утка, плавает как утка и крякает как утка, то это, вероятно, и есть утка.
Считается, что объект реализует интерфейс, если он содержит все методы этого интерфейса, независимо от связей в иерархии наследования и принадлежности к какому-либо конкретному классу. Таким образом, корректность использования объекта в качестве значения определенного интерфейса определяется либо статически, компилятором, на основании анализа класса, к которому относится объект и проверки реализации им необходимого набора методов, либо динамически, на основании информации о типах среды выполнения.
Такой подход позволяет полиморфно работать с объектами, которые не связаны в иерархии наследования. Достаточно, чтобы все эти объекты поддерживали необходимый набор методов.
Другим близким подходом является структурные подтипы в OCaml, где типы объектов совместимы, если совместимы сигнатуры их методов, независимо от объявленного наследования, причем все это проверяется во время компиляции программы.
Утиная типизация решает такие проблемы иерархической типизации, как:
Утиная типизация практически незаменима в прикладных языках сценариев («скриптов»), где приходится работать с внешними по отношению к программе (скрипту) документами (веб-страницы, текстовые и табличные документы), иерархия объектов которых недоступна.
Утиная типизация поддерживается в том числе в языках: Prolog, D, Perl, Smalltalk, Python, Objective-C, Ruby, JavaScript, TypeScript, Groovy, ColdFusion, Boo, Lua, Go, Scala.
Выделяют приведения типов:
Явное приведение задается программистом в тексте программы с помощью:
Неявное приведение выполняется транслятором (компилятором или интерпретатором) по правилам, описанным в стандарте языка. Стандарты большинства языков запрещают неявные преобразования.
В слабо типизированных объектно-ориентированных языках, таких как C++, механизм наследования реализуется посредством приведения типа указателя на текущий объект к базовому классу (в типобезопасных, таких как OCaml, понятие о приведении типов отсутствует принципиально, и допустимость обращения к компоненту подтипа контролируется механизмом проверки согласования типов на этапе компиляции, а в машинном коде остается прямое обращение).
Неявное приведение типов происходит в следующих случаях:
switch значение приводится к целочисленному типу;if, for, while, do-while значение приводится к типу bool.Например, при выполнении бинарной арифметической операции значения операндов приводятся к одному типу. При наследовании указатели производного класса приводятся к указателям базового класса.
Рассмотрим пример на языке C.

При выполнении операций сравнения и при присваивании переменные разных типов неявно приводятся к одному типу.
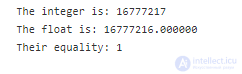
При неявных преобразованиях возможны побочные эффекты. Например, при приведении числа вещественного типа к целому типу дробная часть отсекается (округление не выполняется) . При обратном преобразовании возможно понижение точности из-за различий в представлении вещественных и целочисленных чисел. Например, в переменной типа float (число с плавающей точкой одинарной точности по стандарту IEEE 754), нельзя сохранить число 16 777 217 без потери точности, а в 32-битной переменной целого типа int — можно. Из-за потери точности операции сравнения одного и того же числа, представленного целым и вещественным типами (например, int и float), могут давать ложные результаты (числа могут быть не равны).

Приведенный код выведет следующее, если размер int — 32 бита и компилятор поддерживает стандарт IEEE 754:
Для явного приведения типов имя типа указывается в круглых скобках перед переменной или выражением. Рассмотрим пример.
int X;
int Y = 200;
char C = 30;
X = (int)C * 10 + Y; // переменная С приводится к типу int
Для вычисления последнего выражения компилятор выполняет примерно следующие действия:
C символьного типа char явно приводится к целочисленному типу int путем расширения разрядности;int. Правый операнд — константа 10, а такие константы по умолчанию имеют тип int. Так как оба операнда оператора «*» имеют тип int, неявное приведение типов не выполняется. Результат умножения тоже имеет тип int;int. Правый операнд — переменная Y имеет тип int. Так как оба операнда оператора «+» имеют тип int, неявное приведение к общему типу не выполняется. Результат сложения тоже имеет тип int;X имеет тип int. Правый операнд — результат вычисления выражения, записанного справа от знака «=», тоже имеет тип int. Так как оба операнда оператора «=» имеют одинаковый тип, неявное приведение типов не выполняется.Но даже при этом возможны ошибки. Тип char может быть как знаковым (signed char), так и беззнаковым (unsigned char); результат зависит от реализации компилятора и такое поведение разрешено стандартом. Значение беззнакового типа char при преобразовании к знаковому типу int может оказаться отрицательным из-за особенностей реализации машинных инструкций на некоторых процессорах. Чтобы избежать неоднозначностей, рекомендуется явно указывать знаковость для типа char.
В языке C++ существует пять операций для явного приведения типа. Первая операция — круглые скобки ((type_to)expression_from) поддерживается для сохранения совместимости с C. Остальные четыре операции записываются в виде
Рассмотрим пример.
 // переменной y будет присвоено значение -2
// переменной y будет присвоено значение -2
Громоздкие ключевые слова являются напоминанием программисту о том, что приведение типа чревато проблемами.
static_cast Назначение: допустимые приведения типов.
Операция static_cast аналогична операции «круглые скобки» с одним исключением: она не выполняет приведение указателей на неродственные типы (для этого применяется операция reinterpret_cast).
Применение:
int → enum class) или приводит к предупреждению «Возможная потеря точности» (double → float);void* и наоборот;конструктор может иметь большее число аргументов, но для них должны быть заданы значения по умолчанию;

?:» к одному типу (значения 2-го и 3-го операндов должны иметь одинаковый тип);Ограничения на expression_from: нет.
Ограничения на type_to: должен существовать способ преобразования значения выражения expression_from к типу type_to, с помощью operator type_to или конструктора.
Производит ли операция static_cast код: в общем случае да (например, вызов перегруженной операции приведения типа или конструктора).
Источники логических ошибок: зависят от того, что собираетесь делать операцией. Возможны переполнения, выход за диапазон и даже (для преобразования указателей) порча памяти.
Примеры.
dynamic_cast Назначение: приведение вниз по иерархии наследования, с особым поведением, если объект не имеет нужного типа.
Операция получает информацию о типе объекта expression_from с помощью RTTI. Если тип будет type_to или его подтипом, приведение выполняется. Иначе:
std::bad_cast.Ограничения на expression_from: выражение должно быть ссылкой или указателем на объект, имеющий хотя бы одну виртуальную функцию.
Ограничения на type_to: ссылка или указатель на дочерний по отношению к expression_from тип.
Производит ли операция dynamic_cast код: да.
Логические ошибки возможны, если операции передать аргумент, не имеющий тип type_to, и не проверить указатель на равенство NULL (соответственно не обработать исключение std::bad_cast).
const_castНазначение: снятие/установка модификатора(ов) const, volatile и/или mutable. Часто это применяется, чтобы обойти неудачную архитектуру программы или библиотеки, для стыковки Си с Си++, для передачи информации через обобщенные указатели void*, для одновременного написания const- и не-const-версии функции (в Си++14 существует обход через decltype(auto) ).
Ограничения на expression_from: выражение должно возвращать ссылку или указатель.
Ограничения на type_to: тип type_to должен совпадать с типом выражения expression_from с точностью до модификатора(ов) const, volatile и mutable .
Производит ли операция const_cast код: нет.
Источники логических ошибок: программа может изменить неизменяемый объект. Иногда это может привести к ошибке сегментации, иногда подпрограмма может не ожидать , что память, которую она предоставила для чтения, вдруг изменили.
Для примера рассмотрим код динамической библиотеки.
При загрузке библиотеки в память процесса создает новый сегмент данных, в котором размещаются глобальные переменные. Код функции SomeDllFunction() находится в библиотеке и при вызове возвращает указатель на скрытый член глобального объекта класса string. Операция const_cast используется для удаления модификатора const.
reinterpret_cast Назначение: каламбур типизации — назначение ячейке памяти другого типа (не обязательно совместимого с данным) с сохранением битового представления.
Объект, возвращаемый выражением expression_from, рассматривается как объект типа type_to.
Ограничения на expression_from: выражение должно возвращать значение порядкового типа (любой из целых, логический bool или перечислимый enum), указатель или ссылку.
Ограничения на type_to:
expression_from возвращает значение порядкового типа или указатель, тип type_to может быть порядковым типом или указателем.expression_from возвращает ссылку, тип type_to должен быть ссылкой.Производит ли операция reinterpret_cast код: нет.
Источники логических ошибок. Объект, возвращаемый выражением expression_from, может не иметь типа type_to. Нет никакой возможности проверить это, всю ответственность за корректность преобразования программист берет на себя.
Рассмотрим примеры.

Исследование, описанное в статье про стирание типа, подчеркивает ее значимость в современном мире. Надеюсь, что теперь ты понял что такое стирание типа, вывод типов, утиная типизация, приведение типа и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории ООП и практические JAVA




Комментарии
Оставить комментарий
ООП и практические JAVA
Термины: ООП и практические JAVA