Лекция
Привет, сегодня поговорим про mysql вопросы и ответы на собеседование, обещаю рассказать все что знаю. Для того чтобы лучше понимать что такое mysql вопросы и ответы на собеседование , настоятельно рекомендую прочитать все из категории MySql (Maria DB).

1. Что такое реляционная база данных?
Реляционная база данных - это база данных, основанная на реляционной модели данных. Реляционная модель ориентирована на организацию данных в виде двумерных таблиц. Каждаяреляционная таблица представляет собой двумерный массив и обладает следующими свойствами:
тип (числовой, символьный и т. д.);
1.2 какие типы ключей вы знаете? назначение
1.3 что такое блокировки? какие виды бывают
1.4 расскажите механизм блокировок на примере движков Mycam Innodb
1.5 назначение транцакции
1.6 уровни изолированности транзакций
1.7 какие вы знаете не реляционные данные? какая их область применения?
2. Что такое первичный ключ?
Первичный ключ (primary key) - столбец, значения которого во всех строках различны. Первичные ключи могут быть логическими (естественными) и суррогатными (искусственными). Так, для воображаемой таблицы “Users” первичным ключом может стать столбец e-mail (ведь теоретически не может быть двух пользователей с одинаковым e-mail). Но на практике лучше использовать суррогатные ключи, т.к. их применение позволяет абстрагировать ключи от реальных данных. Кроме того, первичные ключи менять нельзя, но что если у пользователя сменится e-mail?
Суррогатный ключ представляет собой дополнительное поле в базе данных. Как правило, это порядковый номер записи (хотя вы можете задавать их на свое усмотрение, контролируя, чтобы они были уникальны).
3. Что такое нормализация и денормализация?
Нормализация - это процесс приведения базы данных к виду, в котором она будет соответствовать правилам нормальных форм. Нормализация сводит к минимуму количество избыточной
информации. Ее целью является сохранять данные только один раз, но в нужном месте.
Нормализованная база данных исключает дублирование и многократное обслуживание данных, а также появление проблем с целостностью данных, возникающих при повторном вводе одинаковых данных.
Денормализация - это процесс осознанного приведения базы данных к виду, в котором она не будет соответствовать правилам нормализации. Обычно это необходимо для повышения производительности и скорости извлечения данных за счет увеличения избыточности данных.
Если приложению необходимо часто выполнять выборки, которые занимают слишком много времени (например, объединение данных из множества таблиц), то следует рассмотреть возможность проведения денормализации.
Возможное решение следующее: вынести результаты выборки в отдельную таблицу. Это позволит увеличить скорость выполнения запросов, но также означает появление необходимости в постоянном обслуживании этой новой таблицы.
Прежде чем приступать к денормализации, необходимо убедится, что ожидаемые результаты
оправдывают издержки, с которыми придется столкнуться.
4. Что такое mysql_pconnect? Чем он отличается от mysql_connect?
При использовании функции mysql_connect() каждый раз открывается новое соединение с базой данных. После вызова mysql_close() или после завершения работы скрипта соединение закрывается.
Отличия mysql_pconnect() заключаются в том, что, во-первых, при вызове функции сначала
ищется уже открытое (постоянное) соединение с базой (persistent connection), если его нет - создается новое. Во-вторых, после завершения работы скрипта и при вызове mysql_close() соединение с базой MySQL не закрывается, а остается открытым для последующего использования.
5. Что такое MyISAM и InnoDB?
MyISAM и InnoDB - это типы движков таблиц.
6. Чем они отличаются?
MyISAM
- не поддерживает транзакции и с этим связаны его основные недостатки и преимущества;
- в большинстве случаев он быстрее, так как нет расходов на транзакции;
- занимает меньше дискового пространства;
- меньше расход памяти на обновления;
- полнотекстовый индекс;
- быстрый INSERT, SELECT.
InnoDB
- поддержка транзакций;
- построчная блокировка. UPDATE не блокирует всю таблицу;
- отлично ведет себя при смешанной нагрузке (insert|select|update|delete).
7. Как сделать индекс в MySQL?
Для первичных ключей (PRIMARY KEY) индекс создается автоматически.
8. Что такое SQL-инъекция?
SQL-инъекции - встраивание вредоносного кода в запросы к базе данных. С использованием SQL-инъекций злоумышленник может не только получить закрытую информацию из базы данных, но и, при определенных условиях, внести туда изменения.
Уязвимость по отношению к SQL-инъекциям возникает из-за того, что пользовательская инфор мация попадает в запрос к базе данных без должной обработки: чтобы скрипт не был уязвим, требуется убедиться, что все пользовательские данные попадают во все запросы к базе данных
в экранированном виде.
9. Существует ли универсальная защита от SQL-инъекций?
Для этих целей в PHP есть специальные функций для работы со строками:
strip_tags() - вырезает теги HTML и PHP из строки.
htmlspecialchars() - конвертирует только специальные символы (’&’, ‘”‘, ”’, ‘<’ и ‘>’) в HTML сущности (’&’, ‘"’…). Используется для фильтрации вводимых пользователем данных для защиты от XSS-атак.
htmlentities() - конвертирует все символы в строке (кроме букв) в мнемоники HTML. Используется для защиты от XSS, являясь более гибким аналогом htmlspecialchars.
stripslashes() - удаляет заэкранированные символы (после преобразования в сущности предыдущими функциями их незачем экранировать). Обычно используется в связке с провероч-
ной функцией get_magic_quotes_gpc(), показывающей текущую установку конфигурации magic_quotes_gpc. Эта конфигурация влияет на то, как будут обрабатываться специальные символы,
содержащиеся в данных, передаваемых пользователем (массивы $_GET, $_POST, $_COOKIE). При magic_quotes_gpc = 1 эти спецсимволы (одиночные и двойные кавычки, обратный слэш, байт
NULL) автоматически экранируются. При magic_quotes_gpc = 0 все данные передаются в таком
виде, в каком их ввел пользователь. В последнем случае в целях безопасности требуется обрабатывать передаваемые данные.
mysql_real_escape_string - мнемонизирует специальные символы в строке для использования
в операторе SQL с учетом текущего набора символов в кодировке соединения. Иными словами,
функция превращает любую строку в правильную и безопасную для MySQL-запроса. Используется для очистки всех данных, передающихся в MySQL-запрос для защиты от SQL-инъекций.
10. Есть две таблицы:
users - таблица с пользователями (users_id, name)
orders - таблица с заказами (orders_id, users_id, status)
1) Выбрать всех пользователей из таблицы users, у которых ВСЕ записи в таб-
лице orders имеют status = 0
2) Выбрать всех пользователей из таблицы users, у которых больше 5 запи-
сей в таблице orders имеют status = 1
1) Выбор пользователей с использованием вложенного запроса:
SELECT * FROM users WHERE users_id NOT IN (
SELECT users_id FROM orders WHERE status <> 0)
2) C использованием JOIN и HAVING:
SELECT u.* FROM orders o
JOIN users u ON u.users_id = o.users_id
WHERE o.status = 1 GROUP BY o.users_id
HAVING COUNT(o.status) > 5
11. Какая разница между LEFT, RIGHT и INNER JOIN?
Основное различие в том, как соединяются таблицы, если нет общих записей.
Простой JOIN - это то же самое, что INNER JOIN, он показывает только общие записи обоих таб-
лиц. Каким образом записи считаются общими, определяется полями в join-выражении. Напри-
мер, следующая запись:
FROM t1 JOIN t2 on t1.id = t2.id
означает что будут показаны записи с одинаковыми id, существующие в обоих таблицах.
LEFT JOIN (или LEFT OUTER JOIN) означает показывать все записи из левой таблицы (той, кото-
рая идет первой в join-выражении) независимо от наличия соответствующих записей в правой
таблице.
RIGHT JOIN (или RIGHT OUTER JOIN) действует в противоположность LEFT JOIN - показывает все
записи из правой (второй) таблицы и только совпавшие из левой (первой) таблицы.
LEFT JOIN:
- при выполнении условия сцепления таблиц, к ячейкам из первой таблицы присоединяются
ячейки второй;
- если условие не выполняется, присоединяются пустые ячейки.
INNER JOIN:
- при выполнении условия тоже, что и с LEFT JOIN;
- если условие не выполняется, строка вообще игнорируется (не будет ячеек даже из первой
таблицы).
Проще говоря, LEFT JOIN выберет из первой таблицы все записи, даже если во второй таблице
нет совпадений по какому-то условию. INNER JOIN выберет только те, что полностью соответс-
твуют условию.
12. Чем отличается WHERE от HAVING?
При помощи HAVING отражаются все предварительно сгруппированные посредством GROUP BY
блоки данных, удовлетворяющие заданным в HAVING условиям. Это дополнительная возмож-
ность “профильтровать” выходной набор.
Условия в HAVING отличаются от условий в WHERE:
- В условии поиска WHERE нельзя задавать агрегатные функции;
- HAVING исключает из результирующего набора данных группы с результатами агрегирован-
ных значений;
- WHERE исключает из расчета агрегатных значений по группировке записи, не удовлетворяю-
щие условию.
13. Что можешь сказать про команду GROUP BY?
GROUP BY используется для группировки результата одного или нескольких столбцов.
Синтаксис:
SELECT column_name, aggregate_function(column_name)
FROM table_name
WHERE column_name operator value
GROUP BY column_name
14. Об этом говорит сайт https://intellect.icu . Приведи пример использования GROUP BY.
Есть следующая таблица “Orders”:
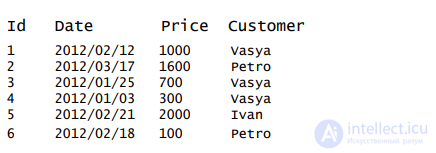
Теперь мы хотим найти общую сумму заказа для каждого клиента. Выполним запрос:
SELECT Customer,SUM(Price) FROM Orders GROUP BY Customer
Результат запроса:

Теперь давайте посмотрим, что произойдет, если мы не используем запрос GROUP BY:
SELECT Customer,SUM(OrderPrice) FROM Orders
Результат запроса:

15. Допустим, у тебя есть Интернет-магазин. Составь запрос, который покажет сколько денег принес каждый отдельно взятый покупатель в общей сложности за все время существования магазина.
SELECT customer_name, SUM(order_price) FROM orders
GROUP BY customer_name;
16. А теперь пусть этот же запрос показывает только тех, кто купил товаров в общей сложности минимум на 10 тысяч евро.
SELECT customer_name, SUM(order_price) FROM orders
GROUP BY customer_name HAVING SUM(order_price) >= 10000;
17. Что делает команда EXPLAIN?
EXPLAIN может в точности рассказать, что происходит, когда мы выполняем запрос. Эта инфор-
мация позволит нам обнаружить медленные запросы и сократить время, затрачиваемое на об-
работку запроса, что впоследствии может значительно ускорить работу вашего приложения.
Вот пример использования этой команды:
EXPLAIN SELECT * FROM users WHERE id=’42’
Если оператор SELECT предваряется ключевым словом EXPLAIN, MySQL сообщит о том, как бу-
дет производиться обработка SELECT, и предоставит информацию о порядке и методе связыва-
ния таблиц.
При помощи EXPLAIN можно выяснить, когда стоит снабдить таблицы индексами, чтобы полу-
чить более быструю выборку, использующую индексы для поиска записей. Кроме того, можно проверить, насколько удачный порядок связывания таблиц был выбран оптимизатором.
Заставить оптимизатор связывать таблицы в заданном порядке можно при помощи указания
STRAIGHT_JOIN.
Для непростых соединений EXPLAIN возвращает строку информации о каждой из использован-
ных в работе оператора SELECT таблиц. Таблицы перечисляются в том порядке, в котором они
будут считываться. MySQL выполняет все связывания за один проход (метод называется “single-
sweep multi-join”). Делается это так: MySQL читает строку из первой таблицы, находит совпа-
дающую строку во второй таблице, затем - в третьей, и так далее. Когда обработка всех таблиц
завершается, MySQL выдает выбранные столбцы и обходит в обратном порядке список таблиц
до тех пор, пока не будет найдена таблица с наибольшим совпадением строк. Следующая строка
считывается из этой таблицы и процесс продолжается в следующей таблице.
18. Как вывести все поля из таблицы super_table?
SELECT * FROM super_table
19. Как вывести только поля name_first, name_last, salary из таблицы super_table?
SELECT name_first, name_last, salary FROM super_table
20. Таблице super_table задать псевдоним t и вывести всех, у кого salary выше 3800
SELECT * FROM super_table AS t WHERE t.salary>3800
21. Выбрать страны, из которых поставляют продукцию производители, так, чтобы страны не повторялись по 2 и более раз.
SELECT DISTINCT country FROM manufacturers
22. Вывести всех украинских производителей.
SELECT * FROM manufacturers WHERE country=”Ukraine”
23. Вывести только те магазины, которые находятся во Киеве и/или Амстердаме.
и:
SELECT * FROM shops WHERE area=”Киев” && area=”Амстердам”
или:
SELECT * FROM shops WHERE area=”Амстердам” || area=”Киев”
24. Вывести все модели авто Tesla, стоимостью не менее 150000 долларов.
SELECT * FROM buses WHERE brand=”Tesla” && NOT seats<15
25. Вывести все автобусы в порядке возрастания количества мест.
SELECT * FROM buses ORDER BY seats
26. Вывести все автобусы в порядке уменьшения количества мест.
SELECT * FROM buses ORDER BY seats DESC
27. Какие знаешь команды для подсчета значений поля?
SELECT MAX(seats) FROM buses // Выведет автобус с максимальным количеством сидений
SELECT MIN(seats) FROM buses // Выведет автобус с минимальным количеством сидений
SELECT SUM(seats) FROM buses // Выведет общее количество сидений во всех автобусах
SELECT AVG(seats) FROM buses // Выведет среднее количество сидений
SELECT COUNT(*) FROM buses // Выведет общее количество автобусов в таблице
SELECT COUNT(*) FROM cars WHERE brand=”Tesla” // Выведет количество авто Tesla
28. Предположим, у нас есть таблица в которой есть поля name и id.
Нужно вывести имя с наибольшим id, не используя при этом команду MAX.
Как это можно сделать?
Отсортировать по id в сторону уменьшения, но вывести только первый id. Он и будет наибольшим.
SELECT name, id FROM customers ORDER BY id DESC LIMIT 1
29. С помощью конструкции IN вывести производителей из Украины, Германии и США.
SELECT * FROM manufacturer WHERE country IN
(“Украина”, “Германия”, “США”)
30. Вывести всех производителей за исключением тех, которые находятся в Китае, Таджикистане и России.
SELECT * FROM manufacturer WHERE country NOT IN
(“Китай”,”Таджикистан”, “Россия”)
31. Вывести пустые / не пустые значения.
пустые:
SELECT * FROM manufacturer WHERE location IS NULL
не пустые:
SELECT * FROM manufacturer WHERE location IS NOT NULL
32. Вывести только те автобусы, названия которых начинаются на букву M.
SELECT * FROM buses WHERE brand LIKE “М%”
33. Мы не помним как точно пишется “Mercedes“ или “Mersedes“, но нужно из таблицы выбрать автобусы именно этой марки. Как быть?
Воспользоваться знаком подчеркивания, который означает “любой символ”:
SELECT * FROM buses WHERE brand LIKE “Mer_edes”
34. Выбрать только те автобусы, цена которых лежит в пределах от 100000 до 180000 долларов включительно.
SELECT * FROM price BETWEEN 100000 AND 180000
35. Подсчитать количество автобусов в таблице, у которых 45 мест.
SELECT COUNT(brand) FROM buses WHERE seats=45
36. Приведи пример вложенного запроса.
SELECT * FROM buses WHERE price=(SELECT MAX(price) FROM buses)
37. Можно ли выбрать данные из нескольких таблиц?
Да, например вот так:
SELECT o.order_no, o.amount_paid, с.company
FROM orders AS o
LEFT JOIN customer AS с ON (с.custno=o.custno)
| DELETE | TRUNCATE |
|---|---|
| Используется для удаления строки в таблице | Используется для удаления всех строк из таблицы |
| Вы можете восстановить данные после удаления | Вы не можете восстановить данные (прим. перевод.: операции логируются по разному, но в SQL Server есть возможность сделать откат) транзакции) |
| DML-команда | DDL-команда |
| Медленнее, чем оператор TRUNCATE | Быстрее |
База данных — структурированная коллекция данных. Система управления базами данных (СУБД) — программное обеспечение, которое взаимодействует с пользователем, приложениями и самой базой данных для сбора и анализа данных. СУБД позволяет пользователю взаимодействовать с базой данных. Данные, хранящиеся в базе данных, могут быть изменены, извлечены и удалены. Они могут быть любых типов, таких как строки, числа, изображения и т. д.
Существует два типа СУБД:
Таблица — организованный набор данных в виде строк и столбцов. Поле — это столбцы в таблице. Например:
Таблица: Student_Information
Поле: Stu_Id, Stu_Name, Stu_Marks
Для соединения строк из двух или более таблиц на основе связанного между ними столбца используется оператор JOIN. Он используется для объединения двух таблиц или получения данных оттуда. В SQL есть 4 типа соединения, а именно:
И Char, и Varchar служат символьными типами данных, но varchar используется для строк символов переменной длины, тогда как Char используется для строк фиксированной длины. Например, char(10) может хранить только 10 символов и не сможет хранить строку любой другой длины, тогда как varchar(10) может хранить строку любой длины до 10, т.е. например 6, 8 или 2.
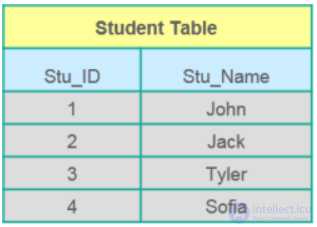
_Пример: в таблице Student StuID является первичным ключом.
Ограничения (constraints) используются для указания ограничения на тип данных таблицы. Они могут быть указаны при создании или изменении таблицы. Пример ограничений:
SQL — стандартный язык структурированных запросов (Structured Query Language) на основе английского языка, тогда как MySQL — система управления базами данных. SQL — язык реляционной базы данных, который используется для доступа и управления данными, MySQL — реляционная СУБД (система управления базами данных), также как и SQL Server, Informix и т. д.
Целостность данных определяет точность, а также согласованность данных, хранящихся в базе данных. Она также определяет ограничения целостности для обеспечения соблюдения бизнес-правил для данных, когда они вводятся в приложение или базу данных.
В SQL есть встроенная функция GetDate (), которая помогает возвращать текущий timestamp/дату.
Существуют различные типы соединений, которые используются для извлечения данных между таблицами. Принципиально они делятся на четыре типа, а именно:
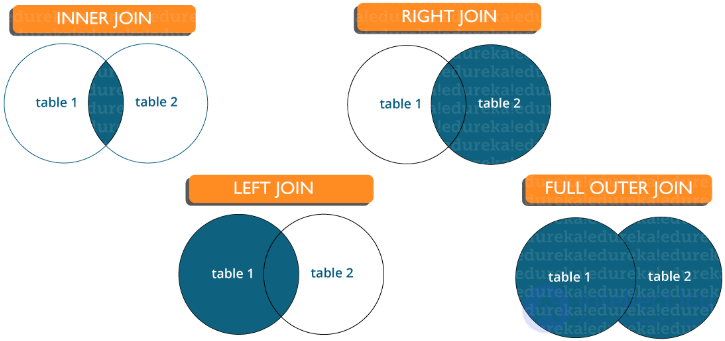
Inner join (Внутреннее соединение): в MySQL является наиболее распространенным типом. Оно используется для возврата всех строк из нескольких таблиц, для которых выполняется условие соединения.
Left Join (Левое соединение): в MySQL используется для возврата всех строк из левой (первой) таблицы и только совпадающих строк из правой (второй) таблицы, для которых выполняется условие соединения.
Right Join (Правое соединение): в MySQL используется для возврата всех строк из правой (второй) таблицы и только совпадающих строк из левой (первой) таблицы, для которых выполняется условие соединения.
Full Join (Полное соединение): возвращает все записи, для которых есть совпадение в любой из таблиц. Следовательно, он возвращает все строки из левой таблицы и все строки из правой таблицы.
Денормализация — техника, которая используется для преобразования из высших к низшим нормальным формам. Она помогает разработчикам баз данных повысить производительность всей инфраструктуры, поскольку вносит избыточность в таблицу. Она добавляет избыточные данные в таблицу, учитывая частые запросы к базе данных, которые объединяют данные из разных таблиц в одну таблицу.
Сущности: человек, место или объект в реальном мире, данные о которых могут храниться в базе данных. В таблицах хранятся данные, которые представляют один тип сущности. Например — база данных банка имеет таблицу клиентов для хранения информации о клиентах. Таблица клиентов хранит эту информацию в виде набора атрибутов (столбцы в таблице) для каждого клиента.
Отношения: отношения или связи между сущностями, которые имеют какое-то отношение друг к другу. Например — имя клиента связано с номером учетной записи клиента и контактной информацией, которая может быть в той же таблице. Также могут быть отношения между отдельными таблицами (например, клиент к счетам).
Индексы относятся к методу настройки производительности, позволяющему быстрее извлекать записи из таблицы. Индекс создает отдельную структуру для индексируемого поля и, следовательно, позволяет быстрее получать данные.
Есть три типа индексов, а именно:
Нормализация — процесс организации данных, цель которого избежать дублирования и избыточности. Некоторые из преимуществ:
Команда DROP удаляет саму таблицу, и нельзя сделать Rollback команды, тогда как команда TRUNCATE удаляет все строки из таблицы (прим. перевод.: в SQL Server Rollback нормально отработает и откатит DROP).
Существует много последовательных уровней нормализации. Это так называемые нормальные формы. Каждая последующая нормальная форма включает предыдущую. Первых трех нормальных форм обычно достаточно.
ACID означает атомарность (Atomicity), согласованность (Consistency), изолированность (Isolation), долговечность (Durability). Он используется для обеспечения надежной обработки транзакций данных в системе базы данных.
Атомарность. Гарантирует, что транзакция будет полностью выполнена или потерпит неудачу, где транзакция представляет одну логическую операцию данных. Это означает, что при сбое одной части любой транзакции происходит сбой всей транзакции и состояние базы данных остается неизменным.
Согласованность. Гарантирует, что данные должны соответствовать всем правилам валидации. Проще говоря, вы можете сказать, что ваша транзакция никогда не оставит вашу базу данных в недопустимом состоянии.
Изолированность. Основной целью изолированности является контроль механизма параллельного изменения данных.
Долговечность. Долговечность подразумевает, что если транзакция была подтверждена (COMMIT), произошедшие в рамках транзакции изменения сохранятся независимо от того, что может встать у них на пути (например, потеря питания, сбой или ошибки любого рода).
Триггер в SQL — особый тип хранимых процедур, которые предназначены для автоматического выполнения в момент или после изменения данных. Это позволяет вам выполнить пакет кода, когда вставка, обновление или любой другой запрос выполняется к определенной таблице.
В SQL доступно три типа оператора, а именно:
Значение NULL вовсе не равно нулю или пробелу. Значение NULL представляет значение, которое недоступно, неизвестно, присвоено или неприменимо, тогда как ноль — это число, а пробел — символ.
Перекрестное соединение создает перекрестное или декартово произведение двух таблиц, тогда как естественное соединение основано на всех столбцах, имеющих одинаковое имя и типы данных в обеих таблицах.
Подзапрос — это запрос внутри другого запроса, в котором определен запрос для извлечения данных или информации из базы данных. В подзапросе внешний запрос называется основным запросом, тогда как внутренний запрос называется подзапросом. Подзапросы всегда выполняются первыми, а результат подзапроса передается в основной запрос. Он может быть вложен в SELECT, UPDATE или любой другой запрос. Подзапрос также может использовать любые операторы сравнения, такие как >, < или =.
Существует два типа подзапросов, а именно: коррелированные и некоррелированные.
Для подсчета количества записей в таблице вы можете использовать следующие команды:
SELECT * FROM table1
SELECT COUNT(*) FROM table1
SELECT rows FROM sysindexes WHERE id = OBJECT_ID(table1) AND indid < 2
Надеюсь, эта статья про mysql вопросы и ответы на собеседование, была вам полезна, счастья и удачи в ваших начинаниях! Надеюсь, что теперь ты понял что такое mysql вопросы и ответы на собеседование и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории MySql (Maria DB)
Ответы на вопросы для самопроверки пишите в комментариях, мы проверим, или же задавайте свой вопрос по данной теме.
Комментарии
Оставить комментарий
Базы данных - MySql (Maria DB)
Термины: Базы данных - MySql (Maria DB)