Лекция
Привет, сегодня поговорим про коллаборативная фильтрация, обещаю рассказать все что знаю. Для того чтобы лучше понимать что такое коллаборативная фильтрация , настоятельно рекомендую прочитать все из категории Модели и методы исследований.
коллаборативная фильтрация , совместная фильтрация (англ. collaborative filtering) — это один из методов построения прогнозов (рекомендаций) врекомендательных системах[⇨], использующий известные предпочтения (оценки) группы пользователей для прогнозирования неизвестных предпочтений другого пользователя.[1]Его основное допущение состоит в следующем: те, кто одинаково оценивали какие-либо предметы в прошлом, склонны давать похожие оценки другим предметам и в будущем.[1]Например, с помощью коллаборативной фильтрации музыкальное приложение способно прогнозировать, какая музыка понравится пользователю [⇨], имея неполный список его предпочтений (симпатий и антипатий).[2] Прогнозы составляются индивидуально для каждого пользователя, хотя используемая информация собрана от многих участников. Тем самым коллаборативная фильтрация отличается от более простого подхода, дающего усредненную оценку для каждого объекта интереса, к примеру, базирующуюся на количестве поданных за него голосов. Исследования в данной области активно ведутся и в наше время, что также обуславливается и наличием нерешенных проблем в коллаборативной фильтрации. [⇨]

Чтобы устранить некоторые ограничения контентной фильтрации, совместная фильтрация использует сходства между пользователями и элементами одновременно для предоставления рекомендаций. Это позволяет по счастливой случайности рекомендации; то есть модели совместной фильтрации могут рекомендовать элемент пользователю A на основе интересов аналогичного пользователя B. Кроме того, вложения могут быть изучены автоматически, не полагаясь на ручное проектирование функций.
В век информационного взрыва такие методы создания персонализированных рекомендаций, как коллаборативная фильтрация, очень полезны, поскольку количество объектов даже в одной категории (такой, как фильмы, музыка, книги, новости, веб-сайты) стало настолько большим, что отдельный человек не способен просмотреть их все, чтобы выбрать подходящие.
Системы коллаборативной фильтрации обычно применяют двухступенчатую схему[1]:
Алгоритм, описанный выше, построен относительно пользователей системы.
Существует и альтернативный алгоритм, изобретенный Amazon[3], построенный относительно предметов (продуктов) в системе. Этот алгоритм включает в себя следующие шаги:
Для примера, можно посмотреть семейство алгоритмов Slope One
Также существует другая форма коллаборативной фильтрации, которая основывается на скрытом наблюдении обычного поведения пользователя (в противоположность явному, который собирает оценки пользователей). В этих системах вы наблюдаете, как поступил данный пользователь, и как — другие (какую музыку они слушали, какие видео посмотрели, какие композиции приобрели), и используете полученные данные, чтобы предсказать поведение пользователя в будущем, или предсказать, как пользователь желал бы поступить при наличии определенной возможности. Эти предсказания должны быть составлены согласно бизнес-логике, так как например, бесполезно предлагать кому-либо купить музыкальный файл, который у него уже имеется.

Типы коллаборативной фильтрации
Существует 2 основных метода, используемых при создании рекомендательных систем — коллаборативная фильтрация и контентно-основанные рекомендации. Также на практике используется гибридный метод построения рекомендаций, который включает с себя смесь вышеперечисленных методов. Коллаборативная фильтрация, в свою очередь, также разделяется на 3 основных подхода (типа) [4]:
Этот подход является исторически первым в коллаборативной фильтрации и используется во многих рекомендательных системах. В данном подходе для активного пользователя подбирается подгруппа пользователей схожих с ним. Комбинация весов и оценок подгруппы используется для прогноза оценок активного пользователя[5]. У данного подхода можно выделить следующие основные шаги:
Данный подход предоставляет рекомендации, измеряя параметры статистических моделей для оценок пользователей, построенных с помощью таких методов как,метод байесовских сетей, кластеризации, латентной семантической модели, такие как сингулярное разложение, вероятностный латентный семантический анализ,скрытое распределение Дирихле и марковской процесс принятия решений на основе моделей. [5] Модели разрабатываются с использованием интеллектуального анализа данных, алгоритмов машинного обучения, чтобы найти закономерности на основе обучающих данных. Число параметров в модели может быть уменьшено в зависимости от типа с помощью метода главных компонент.
Этот подход является более комплексным и дает более точные прогнозы, так как помогает раскрыть латентные факторы, объясняющие наблюдаемые оценки. [7]
Данный подход имеет ряд преимуществ. Он обрабатывает разреженные матрицы лучше, чем подход основанный на соседстве, что в свою очередь помогает с масштабируемостью больших наборов данных.
Недостатки этого подхода заключаются в «дорогом» создании модели[8]. Необходим компромисс между точностью и размером модели, так как можно потерять полезную информацию в связи с сокращением моделей.
Данный подход объединяет в себе подход основанный на соседстве и основанный на модели. Гибридный подход является самым распространенным при разработке рекомендательных систем для коммерческих сайтов, так как он помогает преодолеть ограничения изначального оригинального подхода (основанного на соседстве) и улучшить качество предсказаний. Этот подход также позволяет преодолеть проблему разреженности данных [⇨] и потери информации. Однако данный подход сложен и дорог в реализации и применении.[9]
Как правило, большинство коммерческих рекомендательных систем основано на большом количестве данных (товаров), в то время как большинство пользователей не ставит оценки товарам. В результаты этого матрица «предмет-пользователь» получается очень большой и разреженной, что представляет проблемы при вычислении рекомендаций. Эта проблема особенно остра для новых, только что появившихся систем.[4] Также разреженность данных усиливает проблему холодного старта.
С увеличением количества пользователей в системе, появляется проблема масштабируемости. Например, имея 10 миллионов покупателей  и миллион предметов
и миллион предметов  , алгоритм коллаборативной фильтрации со сложностью равной
, алгоритм коллаборативной фильтрации со сложностью равной  уже слишком сложен для расчетов. Также, многие системы должны моментально реагировать на онлайн запросы от всех пользователей, независимо от истории их покупок и оценок, что требует еще большей масштабируемости.
уже слишком сложен для расчетов. Также, многие системы должны моментально реагировать на онлайн запросы от всех пользователей, независимо от истории их покупок и оценок, что требует еще большей масштабируемости.
Новые предметы или пользователи представляют большую проблему для рекомендательных систем. Об этом говорит сайт https://intellect.icu . Частично проблему помогает решить подход, основанный на анализе содержимого, так как он полагается не на оценки, а на атрибуты, что помогает включать новые предметы в рекомендации для пользователей. Однако проблему с предоставлением рекомендации для нового пользователя решить сложнее.[4]
Синонимией называется тенденция похожих и одинаковых предметов иметь разные имена. Большинство рекомендательных систем не способны обнаружить эти скрытые связи и поэтому относятся к этим предметам как к разным. Например, «фильмы для детей» и «детский фильм» относятся к одному жанру, но система воспринимает их как разные.[5]
В рекомендательных системах, где каждый может ставить оценки, люди могут давать позитивные оценки своим предметам и плохие своим конкурентам. Также, рекомендательные системы стали сильно влиять на продажи и прибыль, с тех пор как получили широкое применении в коммерческих сайтах. Это приводит к тому, что недобросовестные поставщики пытаются мошенническим образом поднимать рейтинг своих продуктов и понижать рейтинг свои конкурентов.[4]
Коллаборативная фильтрация изначально признана увеличить разнообразие, чтобы позволять открывать пользователям новые продукты из бесчисленного множества. Однако некоторые алгоритмы, в частности основные на продажах и рейтингах, создают очень сложные условия для продвижения новых и малоизвестных продуктов, так как их замещают популярные продукты, которые давно находятся на рынке. Это в свою очередь только увеличивает эффект «богатые становятся еще богаче» и приводит в меньшему разнообразию.[10]
К «белым воронам» относятся пользователи, чье мнение постоянно не совпадает с большинством остальных. Из-за их уникального вкуса, им невозможно что-либо рекомендовать. Однако, такие люди имеют проблемы с получением рекомендаций и в реальной жизни, поэтому поиски решения данной проблемы в настоящее время не ведутся.[5]
Коллаборативная фильтрация широко используется в коммерческих сервисах и социальных сетях. Первый сценарий использования это создание рекомендации относительно интересной и популярной информации на основе учета «голосов» сообщества. Такие сервисы, как Reddit, Digg или DiCASTA — это типичные примеры систем, использующих алгоритмы коллаборативной фильтрации.
Другая сфера использования заключается в создании персонализированных рекомендаций для пользователя, на основе его предыдущей активности и данных о предпочтениях других, схожих с ним пользователей. Данный способ реализации можно найти на таких сайтах, как YouTube, Last.fm и Amazon[3], а также в такихгеосоциальных сервисах, как Gvidi и Foursquare.

В современном мире часто приходится сталкиваться с проблемой рекомендации товаров или услуг пользователям какой-либо информационной системы. В старые времена для формирования рекомендаций обходились сводкой наиболее популярных продуктов: это можно наблюдать и сейчас, открыв тот же Google Play. Но со временем такие рекомендации стали вытесняться таргетированными (целевыми) предложениями: пользователям рекомендуются не просто популярные продукты, а те продукты, которые наверняка понравятся именно им. Не так давно компания Netflix проводила конкурс с призовым фондом в 1 миллион долларов, задачей которого стояло улучшение алгоритма рекомендации фильмов (подробнее). Как же работают подобные алгоритмы?
В данной статье рассматривается алгоритм коллаборативной фильтрации по схожести пользователей, определяемой с использованием косинусной меры, а также его реализация на python.
Входные данные
Допустим, у нас имеется матрица оценок, выставленных пользователями продуктам, для простоты изложения продуктам присвоены номера 1-9:

Задать ее можно при помощи csv-файла, в котором первым столбцом будет имя пользователя, вторым — идентификатор продукта, третьим — выставленная пользователем оценка. Таким образом, нам нужен csv-файл со следующим содержимым:
alex,1,5.0 alex,2,3.0 alex,5,4.0 ivan,1,4.0 ivan,6,1.0 ivan,8,2.0 ivan,9,3.0 bob,2,5.0 bob,3,5.0 david,3,4.0 david,4,3.0 david,6,2.0 david,7,1.0
Для начала разработаем функцию, которая прочитает приведенный выше csv-файл. Для хранения рекомендаций будем использовать стандартную для python структуру данных dict: каждому пользователю ставится в соответствие справочник его оценок вида «продукт»:«оценка». Получится следующий код:
import csv
def ReadFile (filename = ""):
f = open (filename)
r = csv.reader (f)
mentions = dict()
for line in r:
user = line[0]
product = line[1]
rate = float(line[2])
if not user in mentions:
mentions[user] = dict()
mentions[user][product] = rate
f.close()
return mentions
Мера схожести
Интуитивно понятно, что для рекомендации пользователю №1 какого-либо продукта, выбирать нужно из продуктов, которые нравятся каким-то пользователям 2-3-4-etc., которые наиболее похожи по своим оценкам на пользователя №1. Как же получить численное выражение этой «похожести» пользователей? Допустим, у нас есть M продуктов. Оценки, выставленные отдельно взятым пользователем, представляют собой вектор в M-мерном пространстве продуктов, а сравнивать вектора мы умеем. Среди возможных мер можно выделить следующие:
Более подробно различные меры и аспекты их применения я собираюсь рассмотреть в отдельной статье. Пока же достаточно сказать, что в рекомендательных системах наиболее часто используются косинусная мера и коэффициент корреляции Танимото. Рассмотрим более подробно косинусную меру, которую мы и собираемся реализовать. Косинусная мера для двух векторов — это косинус угла между ними. Из школьного курса математики мы помним, что косинус угла между двумя векторами — это их скалярное произведение, деленное на длину каждого из двух векторов:
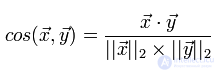
Реализуем вычисление этой меры, не забывая о том, что у нас множество оценок пользователя представлено в виде dict «продукт»:«оценка»
def distCosine (vecA, vecB):
def dotProduct (vecA, vecB):
d = 0.0
for dim in vecA:
if dim in vecB:
d += vecA[dim]*vecB[dim]
return d
return dotProduct (vecA,vecB) / math.sqrt(dotProduct(vecA,vecA)) / math.sqrt(dotProduct(vecB,vecB))
При реализации был использован факт, что скалярное произведение вектора самого на себя дает квадрат длины вектора — это не лучшее решение с точки зрения производительности, но в нашем примере скорость работы не принципиальна.
Алгоритм коллаборативной фильтрации
Итак, у нас есть матрица предпочтений пользователей и мы умеем определять, насколько два пользователя похожи друг на друга. Теперь осталось реализовать алгоритм коллаборативной фильтрации, который состоит в следующем:


В виде формулы этот алгоритм может быть представлен как
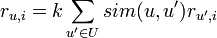
где функция sim — выбранная нами мера схожести двух пользователей, U — множество пользователей, r — выставленная оценка, k — нормировочный коэффициент:

Теперь осталось только написать соответствующий код
import math
def makeRecommendation (userID, userRates, nBestUsers, nBestProducts):
matches = [(u, distCosine(userRates[userID], userRates[u])) for u in userRates if u <> userID]
bestMatches = sorted(matches, key=lambda(x,y):(y,x), reverse=True)[:nBestUsers]
print "Most correlated with '%s' users:" % userID
for line in bestMatches:
print " UserID: %6s Coeff: %6.4f" % (line[0], line[1])
sim = dict()
sim_all = sum([x[1] for x in bestMatches])
bestMatches = dict([x for x in bestMatches if x[1] > 0.0])
for relatedUser in bestMatches:
for product in userRates[relatedUser]:
if not product in userRates[userID]:
if not product in sim:
sim[product] = 0.0
sim[product] += userRates[relatedUser][product] * bestMatches[relatedUser]
for product in sim:
sim[product] /= sim_all
bestProducts = sorted(sim.iteritems(), key=lambda(x,y):(y,x), reverse=True)[:nBestProducts]
print "Most correlated products:"
for prodInfo in bestProducts:
print " ProductID: %6s CorrelationCoeff: %6.4f" % (prodInfo[0], prodInfo[1])
return [(x[0], x[1]) for x in bestProducts]
Для проверки его работоспособности можно выполнить следующую команду:
rec = makeRecommendation ('ivan', ReadFile(), 5, 5)
Что приведет к следующему результату:

Заключение
Мы рассмотрели на примере и реализовали один из простейших вариантов коллаборативной фильтрации с использованием косинусной меры сходства. Важно понимать, что существуют другие подходы к коллаборативной фильтрации, другие формулы для вычисления оценок продуктов, другие меры схожести (статья, раздел «See also»). Дальнейшее развитие этой идеи можно вести в следующих направлениях:
Рассмотрим систему рекомендаций по фильмам, в которой обучающие данные состоят из матрицы обратной связи, в которой:
Отзывы о фильмах делятся на две категории:
Для упрощения будем считать, что матрица обратной связи является двоичной; то есть значение 1 указывает на интерес к фильму.
Когда пользователь посещает домашнюю страницу, система должна рекомендовать фильмы на основе обоих:
Для иллюстрации давайте вручную спроектируем некоторые функции для фильмов, описанных в следующей таблице:
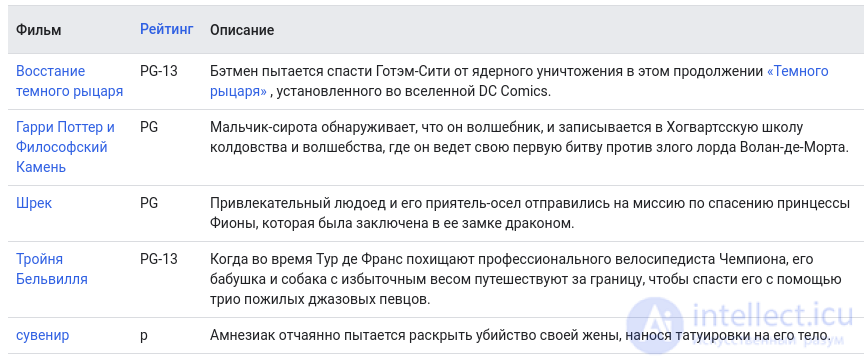
Предположим, мы присваиваем каждому фильму скаляр в [−1,1]который описывает, предназначен ли фильм для детей (отрицательные значения) или для взрослых (положительные значения). Предположим, мы также назначаем скаляр каждому пользователю в[−1,1]который описывает интерес пользователя к детским фильмам (ближе к -1) или фильмам для взрослых (ближе к +1). Продукт встраивания фильма и вложения пользователя должен быть выше (ближе к 1) для фильмов, которые, как мы ожидаем, понравятся пользователю.

На диаграмме ниже каждый флажок обозначает фильм, который смотрел конкретный пользователь. У третьего и четвертого пользователей есть предпочтения, которые хорошо объясняются этой функцией - третий пользователь предпочитает фильмы для детей, а четвертый пользователь предпочитает фильмы для взрослых. Однако предпочтения первого и второго пользователей не очень хорошо объясняются этой единственной функцией.

Одной функции было недостаточно, чтобы объяснить предпочтения всех пользователей. Чтобы преодолеть эту проблему, давайте добавим еще одну особенность: степень, в которой каждый фильм является блокбастером или артхаусом. Со второй функцией мы можем теперь представить каждый фильм со следующим двухмерным встраиванием:

Мы снова помещаем наших пользователей в то же пространство встраивания, чтобы лучше объяснить матрицу обратной связи: для каждой пары (пользователь, элемент) нам бы хотелось, чтобы скалярное произведение встраивания пользователя и вложения элемента было близко к 1, когда пользователь просматривал фильм, и 0 в противном случае.

Примечание. Мы представили элементы и пользователей в одном и том же пространстве. Это может показаться удивительным. В конце концов, пользователи и элементы - это две разные сущности. Однако вы можете представить пространство внедрения как абстрактное представление, общее как для элементов, так и для пользователей, в котором мы можем измерить сходство или релевантность, используя метрику сходства.
В этом примере мы вручную создали вложения. На практике, встраивания могут быть изучены автоматически , что является силой моделей совместной фильтрации. В следующих двух разделах мы обсудим различные модели для изучения этих вложений и способы их обучения.
Совместная природа этого подхода становится очевидной, когда модель изучает вложения. Предположим, что векторы вложения для фильмов фиксированы. Затем модель может изучить вектор встраивания для пользователей, чтобы наилучшим образом объяснить их предпочтения. Следовательно, вложения пользователей со схожими предпочтениями будут близки друг к другу. Точно так же, если вложения для пользователей фиксированы, то мы можем изучить вложения фильмов, чтобы лучше объяснить матрицу обратной связи. В результате встраивание фильмов, которые нравятся подобным пользователям, будет близко в пространстве для встраивания.
Отличие Коллаборативной фильтрации и контентной фильтрации

Надеюсь, эта статья про коллаборативная фильтрация, была вам полезна, счастья и удачи в ваших начинаниях! Надеюсь, что теперь ты понял что такое коллаборативная фильтрация и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Модели и методы исследований
Комментарии
Оставить комментарий
Модели и методы исследований
Термины: Модели и методы исследований