Лекция
Сразу хочу сказать, что здесь никакой воды про функциональное программирование, и только нужная информация. Для того чтобы лучше понимать что такое функциональное программирование, замыкание, каррирование, мемоизация, функции высших порядков, чистые функции, рекурсия, побочные эффекты, side effects, примитивная одержимость, primitive obsession , настоятельно рекомендую прочитать все из категории Функциональное программирование.
функциональное программирование — раздел дискретной математики и парадигма декларативного программирования, в которой процесс вычисления трактуется как вычисление значений функций в математическом понимании последних (в отличие от функций как подпрограмм в процедурном программировании).
Противопоставляется парадигме императивного программирования, которая описывает процесс вычислений как последовательное изменение состояний (в значении, подобном таковому в теории автоматов). При необходимости, в функциональном программировании вся совокупность последовательных состояний вычислительного процесса представляется явным образом, например, как список.
Основные концепции функционального программирования - чистые функции , замыкание , каррирование , рекурсия , мемоизация .
Функциональное программирование предполагает обходиться вычислением результатов функций от исходных данных и результатов других функций, и не предполагает явного хранения состояния программы. Соответственно, не предполагает оно и изменяемость этого состояния (в отличие от императивного, где одной из базовых концепций является переменная, хранящая свое значение и позволяющая менять его по мере выполнения алгоритма).

На практике отличие математической функции от понятия «функции» в императивном программировании заключается в том, что императивные функции могут опираться не только на аргументы, но и на состояние внешних по отношению к функции переменных, а также иметь побочные эффекты и менять состояние внешних переменных. Таким образом, в императивном программировании при вызове одной и той же функции с одинаковыми параметрами, но на разных этапах выполнения алгоритма, можно получить разные данные на выходе из-за влияния на функцию состояния переменных. А в функциональном языке при вызове функции с одними и теми же аргументами мы всегда получим одинаковый результат: выходные данные зависят только от входных. Это позволяет средам выполнения программ на функциональных языках кешировать результаты функций и вызывать их в порядке, не определяемом алгоритмом и распараллеливать их без каких-либо дополнительных действий со стороны программиста (см.ниже Чистые функции)
λ-исчисления являются основой для функционального программирования, многие функциональные языки можно рассматривать как «надстройку» над ними .
Итак, функциональное программирование - это программирование с математическими функциями.
Математические функции не являются методами в программном смысле. Хотя мы иногда используем слова «метод» и «функция» как синонимы, с точки зрения функционального программирования это разные понятия. Математическую функцию лучше всего рассматривать как канал (pipe), преобразующий любое значение, которое мы передаем, в другое значение:
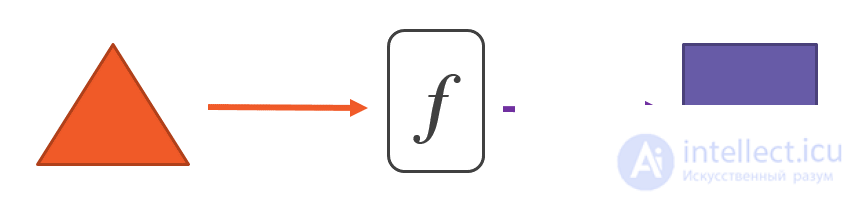
Вот и все. Математическая функция не оставляет во внешнем мире никаких следов своего существования. Она делает только одно: находит соответствующий объект для каждого объекта, который мы ему скармливаем.
Язык функционального программирования
Наиболее известными языками функционального программирования являются :
Еще не полностью функциональные изначальные версии и Lisp и APL внесли особый вклад в создание и развитие функционального программирования. Более поздние версии Lisp, такие как Scheme, а также различные варианты APL поддерживали все свойства и концепции функционального языка .
Как правило, интерес к функциональным языкам программирования, особенно чисто функциональным, был скорее научный, нежели коммерческий. Однако, такие примечательные языки как Erlang, OCaml, Haskell, Scheme (после 1986) а также специфические R (статистика), Mathematica (символьная математика), J и K (финансовый анализ), и XSLT (XML) находили применение в индустрии коммерческого программирования. Такие широко распространенные декларативные языки какSQL и Lex/Yacc содержат некоторые элементы функционального программирования, например, они остерегаются использовать переменные. Языки работы с электронными таблицами также можно рассматривать как функциональные, потому что в ячейках электронных таблиц задается массив функций, как правило зависящих лишь от других ячеек, а при желании смоделировать переменные приходится прибегать к возможностям императивного языка макросов.
Лямбда-исчисление стало теоретической базой для описания и вычисления функций. Являясь математической абстракцией, а не языком программирования, оно составило базис почти всех языков функционального программирования на сегодняшний день. Сходное теоретическое понятие, комбинаторная логика, является более абстрактным, нежели λ-исчисления и было создано раньше. Эта логика используется в некоторых эзотерических языках, например в Unlambda. И λ-исчисление, и комбинаторная логика были разработаны для более ясного и точного описания принципов и основ математики .
Первым функциональным языком был Lisp, созданный Джоном Маккарти в период его работы в Массачусетском технологическом институте в конце пятидесятых и реализованный, первоначально, для IBM 700/7000 (англ.)русск. . Lisp ввел множество понятий функционального языка, хотя при этом исповедовал не только парадигму функционального программирования . Дальнейшим развитием лиспа стали такие языки как Scheme и Dylan.
Язык обработки информации (Information Processing Language (англ.)русск., IPL) иногда определяется как самый первый машинный функциональный язык . Это языкассемблерного типа для работы со списком символов. В нем было понятие «генератора», который использовал функцию в качестве аргумента, а также, поскольку это язык ассемблерного уровня, он может позиционироваться как язык, имеющий функции высшего порядка. Однако, в целом IPL акцентирован на использование императивных понятий .
Кеннет Е. Айверсон разработал язык APL в начале шестидесятых, документировав его в своей книге A Programming Language (ISBN 9780471430148)[11]. APL оказал значительное влияние на язык FP (англ.)русск., созданный Джоном Бэкусом. В начале девяностых Айверсон и Роджер Хуэй (англ.)русск. создали преемника APL — язык программирования J. В середине девяностых Артур Витни (англ.)русск., ранее работавший с Айверсоном, создал язык K, который впоследствии использовался в финансовой индустрии на коммерческой основе.
В семидесятых в университете Эдинбурга Робин Милнер создал язык ML, а Дэвид Тернер начинал разработку языка SASL в университете Сент-Эндрюса и, впоследствии, язык Miranda в университете города Кент. В конечном итоге на основе ML были созданы несколько языков, среди которых наиболее известные Objective Caml и Standard ML. Также в семидесятых осуществлялась разработка языка программирования, построенного по принципу Scheme (реализация не только функциональной парадигмы), получившего описание в известной работе «Lambda Papers», а также в книге восемьдесят пятого года «Structure and Interpretation of Computer Programs», в которой принципы функционального программирования были донесены до более широкой аудитории.
В восьмидесятых Пер Мартин-Леф создал интуиционистскую теорию типов (также называемую конструктивной). В этой теории функциональное программирование получило конструктивное доказательство того, что ранее было известно как зависимый тип. Это дало мощный толчок к развитию диалогового доказательства теорем и к последующему созданию множества функциональных языков.
Haskell был создан в конце восьмидесятых в попытке соединить множество идей, полученных в ходе исследования функционального программирования.
Некоторые концепции и парадигмы специфичны для функционального программирования и в основном чужды императивному программированию (включая объектно-ориентированное программирование). Тем не менее, языки программирования обычно представляют собой гибрид нескольких парадигм программирования, поэтому «большей частью императивные» языки программирования могут использовать какие-либо из этих концепций.
Функции высших порядков — это такие функции, которые могут принимать в качестве аргументов и возвращать другие функции.
Математики такую функцию чаще называют оператором, например, оператор взятия производной или оператор интегрирования.
Функции высших порядков позволяют использовать карринг(каррирование) — преобразование функции от пары аргументов в функцию, берущую свои аргументы по одному. Это преобразование получило свое название в честь Х. Карри.

подробнее про каррирование будет рассмотрено в следующих главах.
Чистыми называют функции, которые не имеют побочных эффектов ввода-вывода и памяти (они зависят только от своих параметров и возвращают только свой результат). Чистые функции обладают несколькими полезными свойствами, многие из которых можно использовать для оптимизации кода:
Хотя большинство компиляторов императивных языков программирования распознают чистые функции и удаляют общие подвыражения для вызовов чистых функций, они не могут делать это всегда для предварительно скомпилированных библиотек, которые, как правило, не предоставляют эту информацию. Некоторые компиляторы, такие как gcc, в целях оптимизации предоставляют программисту ключевые слова для обозначения чистых функций . Fortran 95 позволяет обозначать функции как «pure» (чистые) .
В функциональных языках цикл обычно реализуется в виде рекурсии. Строго говоря, в функциональной парадигме программирования нет такого понятия, как цикл. Рекурсивные функции вызывают сами себя, позволяя операции выполняться снова и снова. Для использования рекурсии может потребоваться большой стек, но этого можно избежать в случае хвостовой рекурсии. Хвостовая рекурсия может быть распознана и оптимизирована компилятором в код, получаемый после компиляции аналогичной итерации в императивном языке программирования. Стандарты языка Scheme требуют распознавать и оптимизировать хвостовую рекурсию. Оптимизировать хвостовую рекурсию можно путем преобразования программы в стиле использования продолжений при ее компиляции, как один из способов
Рекурсивные функции можно обобщить с помощью функций высших порядков, используя, например, катаморфизм и анаморфизм (или «свертка» и «развертка»). Функции такого рода играют роль такого понятия как цикл в императивных языках программирования.
Функциональные языки можно классифицировать по тому, как обрабатываются аргументы функции в процессе ее вычисления. Технически различие заключается в денотационной семантике выражения. К примеру, при строгом подходе к вычислению выражения
print(len([2+1, 3*2, 1/0, 5-4]))
на выходе будет ошибка, так как в третьем элементе списка присутствует деление на ноль. При нестрогом подходе значением выражения будет 4, поскольку для вычисления длины списка значения его элементов, строго говоря, не важны и могут вообще не вычисляться. При строгом (аппликативном) порядке вычисления заранее подсчитываются значения всех аргументов перед вычислением самой функции. При нестрогом подходе (нормальный порядок вычисления) значения аргументов не вычисляются до тех пор, пока их значение не понадобится при вычислении функции[17].
Как правило, нестрогий подход реализуется в виде редукции графа. Нестрогое вычисление используется по умолчанию в нескольких чисто функциональных языках, в том числе Miranda, Clean и Haskell.
Мемоизация (запоминание, от англ. memoization) — в программировании сохранение результатов выполнения функций для предотвращения повторных вычислений. Это один из способов оптимизации, применяемый для увеличения скорости выполнения компьютерных программ. Перед вызовом функции проверяется, вызывалась ли функция ранее:
подробее будет рассотредо в следущих главах.
Замыкание (англ. closure) в программировании — функция первого класса, в теле которой присутствуют ссылки на переменные, объявленные вне тела этой функции в окружающем коде и не являющиеся ее параметрами. Говоря другим языком, замыкание — функция, которая ссылается на свободные переменные в своей области видимости.
Замыкание, так же как и экземпляр объекта, есть способ представления функциональности и данных, связанных и упакованных вместе.
Замыкание — это особый вид функции. Она определена в теле другой функции и создается каждый раз во время ее выполнения. Синтаксически это выглядит как функция, находящаяся целиком в теле другой функции. При этом вложенная внутренняя функция содержит ссылки на локальные переменные внешней функции. Каждый раз при выполнении внешней функции происходит создание нового экземпляра внутренней функции, с новыми ссылками на переменные внешней функции.
В случае замыкания ссылки на переменные внешней функции действительны внутри вложенной функции до тех пор, пока работает вложенная функция, даже если внешняя функция закончила работу, и переменные вышли из области видимости.
Замыкание связывает код функции с ее лексическим окружением (местом, в котором она определена в коде). Лексические переменные замыкания отличаются от глобальных переменных тем, что они не занимают глобальное пространство имен. От переменных в объектах они отличаются тем, что привязаны к функциям, а не объектам.
Примеры замыкания на Javascript , Java, Scheme



Чем функциональное программирование отличается от обычного процедурного подхода?
Разбиение императивного кода на процедуры и функции в процедурной парадигме служит как инструмент абстракции в руках умелых или только для избавления от копипасты в руках обычных. Функции рассчитывают результат, а процедуры что-то куда-то записывают. Ведь нет смысла вызывать процедуру, которая ничего не возвращает и ничего при этом не делает.
В нашем парсере ничего записывать не надо и императивная пошаговость не нужна. Мы просто в потоке преобразуем одни данные в другие, не перезаписывая старые значения. Поэтому в функциональной парадигме можно выкинуть процедуры и переменные за ненадобностью и оставить лишь константы и функции.
Принципиально нет препятствий для написания программ в функциональном стиле на языках, которые традиционно не считаются функциональными, точно так же, как программы в объектно-ориентированном стиле можно писать на структурных языках. Некоторые императивные языки поддерживают типичные для функциональных языков конструкции, такие как функции высшего порядка и списковые включения (list comprehensions), что облегчает использование функционального стиля в этих языках. Примером может быть функциональное программирование на языке Python. Другим примером является язык Ruby, который имеет возможность создания как lambda-объектов, так и возможность организации анонимных функций высшего порядка через блок с помощью конструкции yield.
В языке C указатели на функцию в качестве типов аргументов могут быть использованы для создания функций высшего порядка. Функции высшего порядка и отложенная списковая структура реализованы в библиотеках С++. В языке C# версии 3.0 и выше можно использовать λ-функции для написания программы в функциональном стиле. В сложных языках, типа Алгол-68, имеющиеся средства метапрограммирования (фактически, дополнения языка новыми конструкциями) позволяют создать специфичные для функционального стиля объекты данных и программные конструкции, после чего можно писать функциональные программы с их использованием.
Императивные программы имеют склонность акцентировать последовательности шагов для выполнения какого-то действия, а функциональные программы к расположению и композиции функций, часто не обозначая точной последовательности шагов. Простой пример двух решений одной задачи (используется один и тот же язык Python) иллюстрирует это.
# императивный стиль
target = [] # создать пустой список
for item in source_list: # для каждого элемента исходного списка
trans1 = G(item) # применить функцию G()
trans2 = F(trans1) # применить функцию F()
target.append(trans2) # добавить преобразованный элемент в список
Функциональная версия выглядит по-другому:
# функциональный стиль # языки ФП часто имеют встроенную функцию compose() compose2 = lambda A, B: lambda x: A(B(x)) target = map(compose2(F, G), source_list)
В отличие от императивного стиля, описывающего шаги, ведущие к достижению цели, функциональный стиль описывает математические отношения между данными и целью.
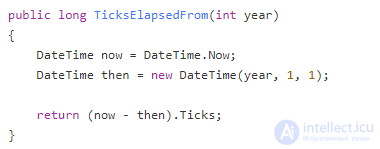
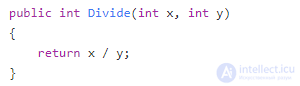
Для того чтобы метод стал математической функцией, он должен соответствовать двум требованиям. Прежде всего, он должен быть ссылочно прозрачным (referentially transparent). Ссылочно прозрачная функция всегда дает один и тот же результат, если вы предоставляете ей одни и те же аргументы. Это означает, что такая функция должна работать только со значениями, которые мы передаем, она не должна ссылаться на глобальное состояние.
Вот еще пример функонального программрования:
Этот метод не является ссылочно прозрачным, потому что он возвращает разные результаты, даже если мы передаем в него один и тот же год. Причина здесь в том, что он ссылается на глобальное свойство DatetTime.Now.
Ссылочно прозрачной альтернативой этому методу может быть (Эта версия работает только с переданными параметрами):
Во-вторых, сигнатура математической функции должна передавать всю информацию о возможных входных значениях, которые она принимает, и о возможных результатах, которые она может дать. Можно называть эту черту честность сигнатуры метода (method signature honesty).
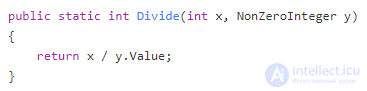
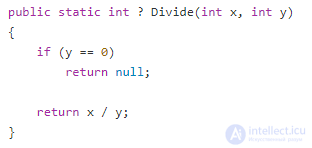
Посмотрите на этот пример кода:
Метод Divide, несмотря на то, что он ссылочно прозрачный, не является математической функцией. В его сигнатуре указано, что он принимает любые два целых числа и возвращает другое целое число. Но что произойдет, если мы передадим ему 1 и 0 в качестве входных параметров?

Вместо того, чтобы вернуть целое число, как мы ожидали, он вызовет исключение «Divide By Zero». Это означает, что сигнатура метода не передает достаточно информации о результате операции. Он обманывает вызывающего, делая вид, что может обрабатывать любые два параметра целочисленного типа, тогда как на практике он имеет особый случай, который не может быть обработан.
Чтобы преобразовать метод в математическую функцию, нам нужно изменить тип параметра "y", например:
Здесь NonZeroInteger - это пользовательский тип, который может содержать любое целое число, кроме нуля. Таким образом, мы сделали метод честным, поскольку теперь он не ведет себя неожиданно для любых значений из входного диапазона. Другой вариант - изменить его возвращаемый тип:
Эта версия также честна, поскольку теперь не гарантирует, что она вернет целое число для любой возможной комбинации входных значений.
Несмотря на простоту определения функционального программирования, оно включает в себя множество приемов, которые многим программистам могут показаться новыми. Посмотрим, что они из себя представляют.
Первая такая практика - максимально избегать побочных эффектов за счет использования иммутабельности по всей базе кода. Этот метод важен, потому что акт изменения состояния противоречит функциональным принципам.
Сигнатура метода с побочным эффектом не передает достаточно информации о фактическом результате операции. Чтобы проверить свои предположения относительно кода, который вы пишете, вам нужно не только взглянуть на саму сигнатуру метода, но также необходимо перейти к деталям его реализации и посмотреть, оставляет ли этот метод какие-либо побочные эффекты, которых вы не ожидали:
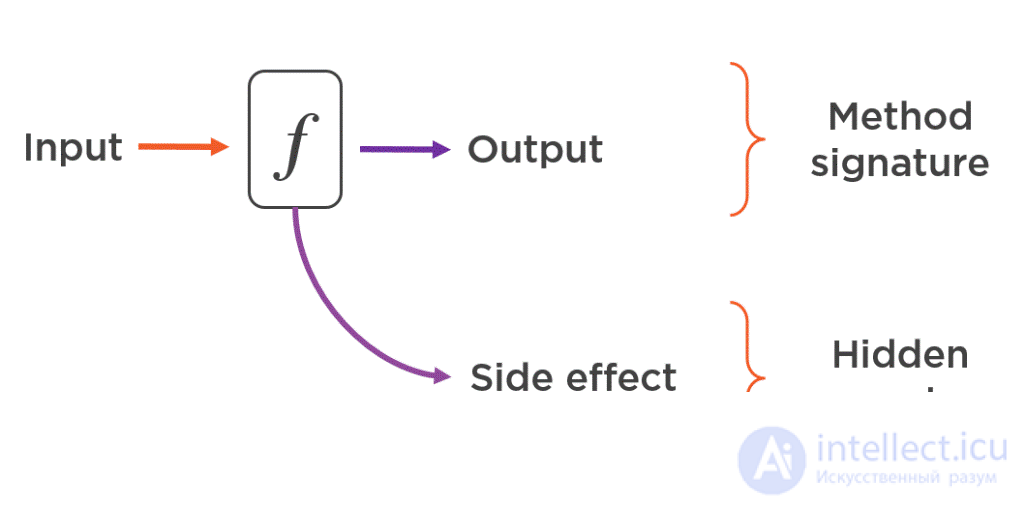
В целом, код со структурами данных, которые меняются со временем, сложнее отлаживать и более подвержен ошибкам. Это создает еще больше проблем в многопоточных приложениях, где у вас могут возникнуть всевозможные неприятные условия гонки.
Когда вы работаете только с иммутабельными данными, вы заставляете себя обнаруживать скрытые побочные эффекты, указывая их в сигнатуре метода и тем самым делая его честным. Это делает код более читабельным, потому что вам не нужно останавливаться на деталях реализации методов, чтобы понять ход выполнения программы. С иммутабельными классами вы можете просто взглянуть на сигнатуру метода и сразу же получить хорошее представление о том, что происходит, без особых усилий.
Исключения - еще один источник нечестности для вашей кодовой базы. Методы, которые используют исключения для управления потоком программы, не являются математическими функциями, потому что, как и побочные эффекты, исключения скрывают фактический результат операции.
Более того, исключения имеют семантику goto, что означает, что они позволяют легко переходить из любой точки вашей программы в блок catch. На самом деле, исключения работают еще хуже, потому что оператор goto не позволяет выходить за пределы определенного метода, тогда как с исключениями вы можете легко пересекать несколько уровней в своей базе кода.
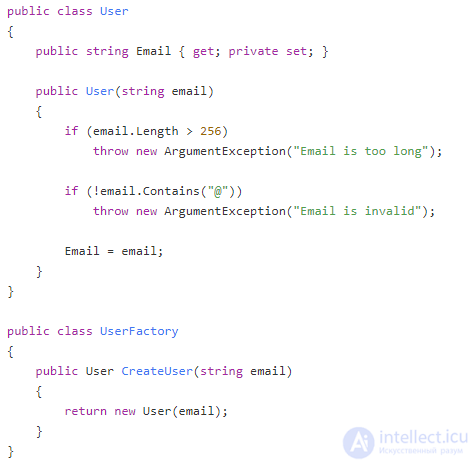
В то время как побочные эффекты и исключения делают ваши методы нечестными в отношении их результатов, примитивная одержимость вводит читателя в заблуждение относительно входных значений методов. Вот пример:
Что нам говорит сигнатура метода CreateUser? Она говорит, что для любой входной строки он возвращает экземпляр User. Однако на практике он принимает только строки, отформатированные определенным образом, и выдает исключения, если это не так. Следовательно, этот метод нечестен, поскольку не передает достаточно информации о типах строк, с которыми работает.
По сути, это та же проблема, которую вы видели с методом Divide:
Тип параметра для электронной почты, а также тип параметра для "y" являются более грубыми, чем фактическая концепция, которую они представляют. Количество состояний, в которых может находиться экземпляр строкового типа, превышает количество допустимых состояний для правильно отформатированного электронного письма. Это несоответствие приводит к обману разработчика, который использует такой метод. Это заставляет программиста думать, что метод работает с примитивными строками, тогда как на самом деле эта строка представляет концепцию предметной области со своими инвариантами.
Как и в случае с методом Divide, нечестность можно исправить, введя отдельный класс Email и используя его вместо строки.
Еще одна практика в этом списке - избегать nulls. Оказывается, использование значений NULL делает ваш код нечестным, поскольку сигнатура методов, использующих их, не сообщает всю информацию о возможном результате соответствующей операции.
Но тут, конечно, зависит от языка. Автор оригинала работает с C#, в котором до 8 версии нельзя было указывать является ли значение nullable (https://docs.microsoft.com/en-us/dotnet/csharp/language-reference/builtin-types/nullable-value-types). Так как оригинал статьи 2016 года, на тот момент еще не было такой возможности в C#.
Фактически, в C # все ссылочные типы действуют как контейнер для двух типов значений. Один из них является экземпляром объявленного типа, а другой - null. И нет никакого способа провести различие между ними, поскольку эта функциональность встроена в сам язык. Вы всегда должны помнить, что, объявляя переменную ссылочного типа, вы фактически объявляете переменную пользовательского двойного типа, которая может содержать либо нулевую ссылку, либо фактический экземпляр:

В некоторых случаях это именно то, что вам нужно, но иногда вы хотите просто вернуть MyClass без возможности его преобразования в null. Проблема в том, что в C # это невозможно сделать. Невозможно различить ссылочные типы, допускающие значение NULL, и ссылочные типы, не допускающие значения NULL. Это означает, что методы со ссылочными типами в своей сигнатуре по своей сути нечестны.
Эту проблему можно решить, введя тип Maybe и соглашение внутри команды о том, что всякий раз, когда вы определяете переменную, допускающую значение NULL, вы используете для этого тип Maybe.
Важный вопрос, который приходит на ум, когда вы читаете о функциональном программировании: зачем вообще беспокоиться об этом?
Одной из самых больших проблем, возникающих при разработке корпоративного программного обеспечения, является сложность. Сложность кодовой базы, над которой мы работаем, является единственным наиболее важным фактором, влияющим на такие вещи, как скорость разработки, количество ошибок и способность быстро приспосабливаться к постоянно меняющимся потребностям рынка.
Существует некий предел сложности, с которой мы можем справиться за раз. Если кодовая база проекта превышает этот предел, становится действительно трудно, а в какой-то момент даже невозможно что-либо изменить в программном обеспечении без каких-либо неожиданных побочных эффектов.
Применение принципов функционального программирования помогает снизить сложность кода. Оказывается, программирование с использованием математических функций значительно упрощает нашу работу. Благодаря двум характеристикам, которыми они обладают - честности сигнатуры метода и ссылочной прозрачности - мы можем гораздо проще понимать и рассуждать о таком коде.
Каждый метод в нашей кодовой базе - если он написан как математическая функция - можно рассматривать отдельно от других. Когда мы уверены, что наши методы не влияют на глобальное состояние или не работают с исключением, мы можем рассматривать их как строительные блоки и компоновать их так, как мы хотим. Это, в свою очередь, открывает большие возможности для создания сложной функциональности, которую создать ненамного сложнее, чем части, из которых она состоит.
Имея честную сигнатуру метода, нам не нужно останавливаться на деталях реализации метода или обращаться к документации, чтобы узнать, есть ли что-то еще, что нам нужно учесть перед его использованием. Сама сигнатура сообщает нам, что может случиться после того, как мы вызовем такой метод. Модульное тестирование также становится намного проще. Все сводится к паре строк, в которых вы просто указываете входное значение и проверяете результат. Нет необходимости создавать сложные тестовые двойники, такие как mocks, и поддерживать их в дальнейшем.
Основной особенностью функционального программирования, определяющей как преимущества, так и недостатки данной парадигмы, является то, что в ней реализуется модель вычислений без состояний. Если императивная программа на любом этапе исполнения имеет состояние, то есть совокупность значений всех переменных, и производит побочные эффекты, то чисто функциональная программа ни целиком, ни частями состояния не имеет и побочных эффектов не производит. То, что в императивных языках делается путем присваивания значений переменным, в функциональных достигается путем передачи выражений в параметры функций. Непосредственным следствием становится то, что чисто функциональная программа не может изменять уже имеющиеся у нее данные, а может лишь порождать новые путем копирования и/или расширения старых. Следствием того же является отказ от циклов в пользу рекурсии.
Повышение надежности кода
Привлекательная сторона вычислений без состояний — повышение надежности кода за счет четкой структуризации и отсутствия необходимости отслеживания побочных эффектов. Любая функция работает только с локальными данными и работает с ними всегда одинаково, независимо от того, где, как и при каких обстоятельствах она вызывается. Невозможность мутации данных при пользовании ими в разных местах программы исключает появление труднообнаруживаемых ошибок (таких, например, как случайное присваивание неверного значения глобальной переменной в императивной программе).
Удобство организации модульного тестирования
Поскольку функция в функциональном программировании не может порождать побочные эффекты, менять объекты нельзя как внутри области видимости, так и снаружи (в отличие от императивных программ, где одна функция может установить какую-нибудь внешнюю переменную, считываемую второй функцией). Единственным эффектом от вычисления функции является возвращаемый ей результат, и единственный фактор, оказывающий влияние на результат — это значения аргументов.
Таким образом, имеется возможность протестировать каждую функцию в программе, просто вычислив ее от различных наборов значений аргументов. При этом можно не беспокоиться ни о вызове функций в правильном порядке, ни о правильном формировании внешнего состояния. Если любая функция в программе проходит модульные тесты, то можно быть уверенным в качестве всей программы. В императивных программах проверка возвращаемого значения функции недостаточна: функция может модифицировать внешнее состояние, которое тоже нужно проверять, чего не нужно делать в функциональных программах[18].
Возможности оптимизации при компиляции
Традиционно упоминаемой положительной особенностью функционального программирования является то, что оно позволяет описывать программу в так называемом «декларативном» виде, когда жесткая последовательность выполнения многих операций, необходимых для вычисления результата, в явном виде не задается, а формируется автоматически в процессе вычисления функций. Это обстоятельство, а также отсутствие состояний дает возможность применять к функциональным программам достаточно сложные методы автоматической оптимизации.
Возможности параллелизма
Еще одним преимуществом функциональных программ является то, что они предоставляют широчайшие возможности для автоматического распараллеливаниявычислений. Поскольку отсутствие побочных эффектов гарантировано, в любом вызове функции всегда допустимо параллельное вычисление двух различных параметров — порядок их вычисления не может оказать влияния на результат вызова.
Недостатки функционального программирования вытекают из тех же самых его особенностей. Отсутствие присваиваний и замена их на порождение новых данных приводят к необходимости постоянного выделения и автоматического освобождения памяти, поэтому в системе исполнения функциональной программы обязательным компонентом становится высокоэффективный сборщик мусора. Нестрогая модель вычислений приводит к непредсказуемому порядку вызова функций, что создает проблемы при вводе-выводе, где порядок выполнения операций важен. Кроме того, очевидно, функции ввода в своем естественном виде (например, getchar из стандартной библиотеки языка C) не являются чистыми, поскольку способны возвращать различные значения для одних и тех же аргументов, и для устранения этого требуются определенные ухищрения.
Для преодоления недостатков функциональных программ уже первые языки функционального программирования включали не только чисто функциональные средства, но и механизмы императивного программирования (присваивание, цикл, «неявный PROGN» были уже в LISPе). Использование таких средств позволяет решить некоторые практические проблемы, но означает отход от идей (и преимуществ) функционального программирования и написание императивных программ на функциональных языках. В чистых функциональных языках эти проблемы решаются другими средствами, например, в языке Haskell ввод-вывод реализован при помощи монад — нетривиальной концепции, позаимствованной из теории категорий.
не обязательно делать весь проект на функциональном программировании, в проекте с логикой могут быть некие комбинированные расчеты, где ООП неудобен.
Если рассматриваем проект как совокупность «ящиков», то удобно использовать ООП. Если как потоки преобразований данных, то удобнее ФП. Если это не подходит, то делаем гибрид или придумываем что-нибудь другое. Весьма забавно выглядят порой попытки спрограммировать «ящики» на функциональном подходе или реализовать гибкие преобразователи данных на ООП. И какой из этого главный вывод?
Чем больше парадигм и фреймворков знаешь (и умеешь), тем адекватнее можешь их сравнивать и выбирать.
Функциональное программирование - это программирование с использованием математических функций. Для преобразования методов в математические функции нам нужно сделать их сигнатуры честными в том смысле, что они должны полностью отражать все возможные входные данные и результаты, и нам также необходимо убедиться, что метод работает только с теми значениями, которые мы передаем, и ничего больше.
Практики, которые помогают преобразовать методы в математические функции:
Иммутабельность.
Избегать исключения для управления потоком программы.
Избавляться от примитивной одержимости.
Делать nulls явными.
А как ты думаешь, при улучшении функциональное программирование, будет лучше нам? Надеюсь, что теперь ты понял что такое функциональное программирование, замыкание, каррирование, мемоизация, функции высших порядков, чистые функции, рекурсия, побочные эффекты, side effects, примитивная одержимость, primitive obsession и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Функциональное программирование


Комментарии
Оставить комментарий
Функциональное программирование
Термины: Функциональное программирование