Лекция
Сразу хочу сказать, что здесь никакой воды про синтез речи, и только нужная информация. Для того чтобы лучше понимать что такое синтез речи , настоятельно рекомендую прочитать все из категории Автоматический синтез речи.
синтез речи — в широком смысле — восстановление формы речевого сигнала по его параметрам ; в узком смысле — формирование речевого сигнала попечатному[уточнить] тексту. Часть искусственного интеллекта.
Синтезом речи — прежде всего называется все, что связано с искусственным производством человеческой речи.
Синтезатор речи — структура, способная переводить текст/образы в речь, в программном обеспечении или аппаратных средствах.
Голосовой движок — непосредственно система/ядро преобразования текста/команд в речь, это также может существовать независимо от компьютера.
Синтез речи может потребоваться во всех случаях, когда получателем информации является человек. Но вот о самом качестве синтезатора речи прежде всего судят по его сходству с человеческим голосом, а также способностью быть понятым. Что непосредственно позволяет пользоваться людям с ослабленным зрением или же просто чтением слушать письменные работы на домашнем компьютере. Самую наипростейшую синтезированную речь можно создавать путем объединения частей записанной речи, которые затем будут храниться в базе данных. И как ни странно, с таким способом синтезирования мы сталкиваемся уже повсеместно, даже не обращая порой на это внимания.
Все способы синтеза речи можно подразделить на группы:
Параметрический синтез речи является конечной операцией в вокодерных системах, где речевой сигнал представляется набором небольшого числа непрерывно изменяющихся параметров. Параметрический синтез целесообразно применять в тех случаях, когда набор сообщений ограничен и изменяется не слишком часто. Достоинством такого способа является возможность записать речь для любого языка и любого диктора. Качество параметрического синтеза может быть очень высоким (в зависимости от степени сжатия информации в параметрическом представлении). Однако параметрический синтез не может применяться для произвольных, заранее не заданных сообщений.
Компиляционный синтез сводится к составлению сообщения из предварительно записанного словаря исходных элементов синтеза. Размер элементов синтеза не меньше слова. Очевидно, что содержание синтезируемых сообщений фиксируется объемом словаря. Как правило, число единиц словаря не превышает нескольких сотен слов. Основная проблема в компилятивном синтезе — объемы памяти для хранения словаря. В этой связи используются разнообразные методы сжатия/кодирования речевого сигнала. Компилятивный синтез имеет широкое практическое применение. В западных странах разнообразные устройства (от военных самолетов до бытовых устройств) оснащаются системами речевого ответа. В России системы речевого ответа до недавнего времени использовались в основном в области военной техники, сейчас они находят все большее применение в повседневной жизни, например, в справочных службах операторов сотовой связи при получении информации о состоянии счета абонента.
Полный синтез речи по правилам (или синтез по печатному тексту) обеспечивает управление всеми параметрами речевого сигнала и, таким образом, может генерировать речь по заранее неизвестному тексту. В этом случае параметры, полученные при анализе речевого сигнала, сохраняются в памяти так же, как и правила соединения звуков в слова и фразы. Синтез реализуется путем моделирования речевого тракта, применения аналоговой или цифровой техники. Причем в процессе синтезирования значения параметров и правила соединения фонем вводят последовательно через определенный временной интервал, например 5—10 мс. Метод синтеза речи по печатному тексту (синтез по правилам) базируется на запрограммированном знании акустических и лингвистических ограничений и не использует непосредственно элементы человеческой речи. В системах, основанных на этом способе синтеза, выделяется два подхода. Первый подход направлен на построение модели речепроизводящей системы человека, он известен под названием артикуляторного синтеза. Второй подход — формантный синтез по правилам. Разборчивость и натуральность таких синтезаторов может быть доведена до величин, сравнимых с характеристиками естественной речи.
Синтез речи по правилам с использованием предварительно запомненных отрезков естественного языка — это разновидность синтеза речи по правилам, которая получила распространение в связи с появлением возможностей манипулирования речевым сигналом в оцифрованной форме. В зависимости от размера исходных элементов синтеза выделяются следующие виды синтеза:
Обычно в качестве таких элементов используются полуслоги — сегменты, содержащие половину согласного и половину примыкающего к нему гласного. При этом можно синтезировать речь по заранее не заданному тексту, но трудно управлять интонационными характеристиками. Качество такого синтеза не соответствует качеству естественной речи, поскольку на границах сшивки дифонов часто возникают искажения. Об этом говорит сайт https://intellect.icu . Компиляция речи из заранее записанных словоформ также не решает проблемы высококачественного синтеза произвольных сообщений, поскольку акустические и просодические (длительность и интонация) характеристики слов изменяются в зависимости от типа фразы и места слова во фразе. Это положение не меняется даже при использовании больших объемов памяти для хранения словоформ.
Предметно-ориентированный синтез компилирует слова записанные заранее, а также фразы для создания полных речевых сообщений. Он используется в приложениях, где многообразие текстов системы будет ограничено определенной темой/областью, например объявления об отправлении поездов и прогнозы погоды. Эта технология проста в использовании и достаточно долго применялась в коммерческих целях: ее так же применяли при изготовлении электронных приборов, таких как говорящие часы и калькуляторы. Естественность звучания этих систем потенциально может быть высокой благодаря тому, что многообразие видов предложений ограничено и близко с соответствием интонацией исходных записей. А так как эти системы ограничены выбором слов и фраз в базе данных, они в дальнейшем не могут иметь широкое распространение в сферах деятельности человека, лишь потому, что способны синтезировать комбинации слов и фраз, на которые они были запрограммированы.
В конце XVIII века датский ученый Христиан Кратценштейн, действительный член Российской Академии Наук, создал модель речевого тракта человека, способную произносить пять долгих гласных звуков (а, э, и, о, у). Модель представляла собой систему акустических резонаторов различной формы, издававших гласные звуки при помощи вибрирующих язычков, возбуждаемых воздушным потоком. В 1778 австрийский ученый Вольфганг фон Кампелен дополнил модель Кратценштейна моделями языка и губ и представил акустическо-механическую говорящую машину, способную воспроизводить определенные звуки и их комбинации. Шипящие и свистящие выдувались с помощью специального меха с ручным управлением. В 1837 ученый Чарльз Уитстоун (Charles Wheatstone) представил улучшенный вариант машины, способный воспроизводить гласные и большинство согласных звуков. А в 1846 году Джезеф Фабер (Joseph Faber) продемонстрировал свой говорящий орга́н Euphonia, в котором была реализована попытка синтезирования не только речи, но и пения.
В конце XIX века знаменитый ученый Александр Белл создал собственную «говорящую» механическую модель, очень схожую по конструкции с машиной Уитстоуна. С наступлением XX века началась эра электрических машин, и ученые получили возможность использовать генераторы звуковых волн и на их базе строить алгоритмические модели.
В 1930-х годах работник Bell Labs Хомер Дадли (Homer Dudley), работая над проблемой поиска путей для снижения пропускной способности необходимой в телефонии, чтобы увеличить ее передающую способность, разрабатывает VOCODER (сокращенно от англ. voice — голос, англ. coder — кодировщик) — управляемый с помощью клавиатуры электронный анализатор и синтезатор речи. Идея Дадли заключалась в том, чтобы проанализировать голосовой сигнал, разобрать его на части и пересинтезировать в менее требовательный к пропускной способности линии. Усовершенствованный вариант вокодера Дадли, VODER, был представлен на Нью-Йоркской Всемирной выставке 1939 года .
Первые синтезаторы речи звучали довольно неестественно, и часто едва можно было разобрать производимые ими фразы. Однако качество синтезированной речи постоянно улучшалось, и речь, генерируемую современными системами синтеза речи, порой не отличить от реальной человеческой речи. Но несмотря на успехи электронных синтезаторов речи, исследования в области создания механических синтезаторов речи по-прежнему ведутся, например, для использования в роботах-гуманоидах.
Первые системы синтеза речи на базе вычислительной техники стали появляться в конце 1950-х годов, а первый синтезатор «текст-в-речь» был создан в 1968 году.
Пока что рано говорить о каком-то перспективном будущем на ближайшие десятилетия для синтеза речи по правилам, так как звучание все еще напоминает больше всего речь роботов, а местами это еще и трудно понимаемая речь. Что мы точно можем безошибочно определять, так это то что говорит ли синтезатор речи мужским или женским голосом, а тонкости присущие человеческому голосу мы порой все еще не различаем. Поэтому технология разработки, частично отвернулась от фактического построения синтеза речевых сигналов, но все также продолжает использовать простейшую сегментацию записи голоса.
Речь моделей unit selection имеет высокое качество, низкую вариативность и требует большого объема данных для обучения. В то же время для тренировки параметрических моделей необходимо гораздо меньшее количество данных, они генерируют более разнообразные интонации, но до недавнего времени страдали от общего достаточно низкого качества звука по сравнению с подходом unit selection.
Однако с развитием технологий глубокого обучения модели параметрического синтеза достигли существенного прироста по всем метрикам качества и способны создавать речь, практически неотличимую от человеческой.
Прежде чем говорить о том, какие модели синтеза речи лучше, нужно определить метрики качества, по которым будет проводиться сравнение алгоритмов.
Поскольку один и тот же текст можно прочитать бесконечным количеством способов, априори правильного способа для произношения конкретной фразы не существует. Поэтому зачастую метрики качества синтеза речи субъективны и зависят от восприятия слушающего.
Стандартная метрика — это MOS (mean opinion score), усредненная оценка естественности речи, выданная асессорами для синтезированных аудио по шкале от 1 до 5. Единица означает совсем неправдоподобное звучание, а пятерка — речь, неотличимую от человеческой. Реальные записи людей обычно получают значения примерно 4,5, и значение больше 4 считается достаточно высоким.
Первый шаг к построению любой системы синтеза речи — сбор данных для обучения. Обычно это аудиозаписи высокого качества, на которых диктор читает специально подобранные фразы. Примерный размер датасета, необходимый для обучения моделей unit selection, составляет 10—20 часов чистой речи , в то время как для нейросетевых параметрических методов верхняя оценка равна примерно 25 часам [4, 5].
Обсудим обе технологии синтеза.
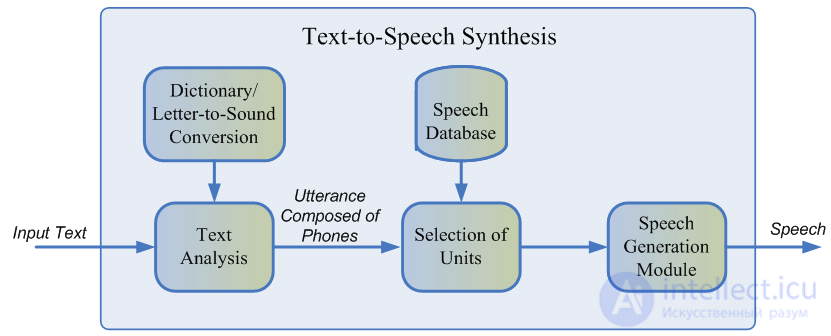
Обычно записанная речь диктора не может покрыть всех возможных случаев, в которых будет использоваться синтез. Поэтому суть метода состоит в разбиении всей аудиобазы на небольшие фрагменты, называющиеся юнитами, которые затем склеиваются друг с другом с использованием минимальной постобработки. В качестве юнитов обычно выступают минимальные акустические единицы языка, такие как полуфоны или дифоны .
Весь процесс генерации состоит из двух этапов: NLP frontend, отвечающий за извлечение лингвистического представления текста, и backend, который вычисляет функцию штрафа юнитов для заданных лингвистических признаков. В NLP frontend входят:
Обычно NLP frontend реализован с помощью вручную прописанных правил для конкретного языка, однако в последнее время происходит все больший уклон в сторону использования моделей машинного обучения .
Штраф, оцениваемый backend-подсистемой, — это сумма target cost, или соответствия акустического представления юнита для конкретной фонемы, и concatenation cost, то есть уместности соединения двух соседних юнитов. Для оценки штраф функций можно использовать правила или уже обученную акустическую модель параметрического синтеза . Выбор наиболее оптимальной последовательности юнитов с точки зрения выше определенных штрафов происходит с помощью алгоритма Витерби .
Примерные значения MOS моделей unit selection для английского языка: 3,7—4,1 [2, 4, 5].
Достоинства подхода unit selection:
Недостатки:
В основе параметрического подхода лежит идея о построении вероятностной модели, оценивающей распределение акустических признаков заданного текста.
Процесс генерации речи в параметрическом синтезе можно разделить на четыре этапа:
Для обучения duration и акустической моделей можно использовать скрытые марковские модели , глубокие нейронные сети или их рекуррентные разновидности . Традиционный вокодер — это алгоритм, основанный на source-filter модели , которая предполагает, что речь — это результат применения линейного фильтра шума к первоначальному сигналу.
Общее качество речи классических параметрических методов оказывается достаточно низким из-за большого количества независимых предположений об устройстве процесса генерации звука.
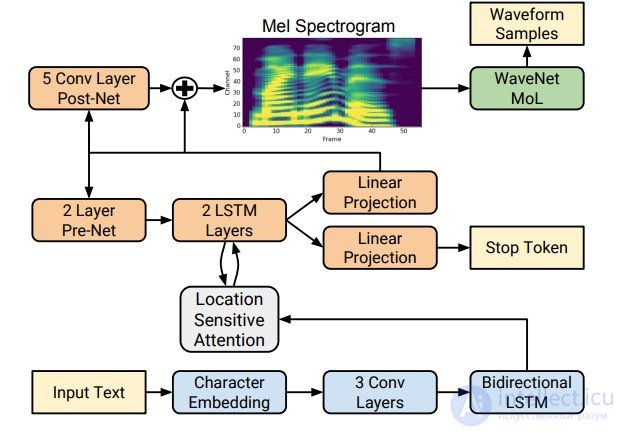
Однако с приходом технологий глубокого обучения стало возможным обучать end-to-end модели, которые напрямую предсказывают акустические признаки по буквам. Например, нейронные сети Tacotron и Tacotron 2 принимают на вход последовательность букв и возвращают мел-спектрограмму с помощью алгоритма seq2seq . Таким образом шаги 1—3 классического подхода заменяются одной нейросетью. На схеме ниже показана архитектура сети Tacotron 2, достигающей достаточно высокого качества звука.
Другим фактором существенного прироста в качестве синтезируемой речи стало применение нейросетевых вокодеров вместо алгоритмов цифровой обработки сигналов.
Первым таким вокодером была нейронная сеть WaveNet , которая последовательно, шаг за шагом, предсказывала значения амплитуды звуковой волны.
Благодаря использованию большого количества сверточных слоев с пропусками для захвата большего контекста и skip connection в архитектуре сети удалось достичь примерно 10%-го улучшения MOS по сравнению с моделями unit selection. На схеме ниже представлена архитектура сети WaveNet.
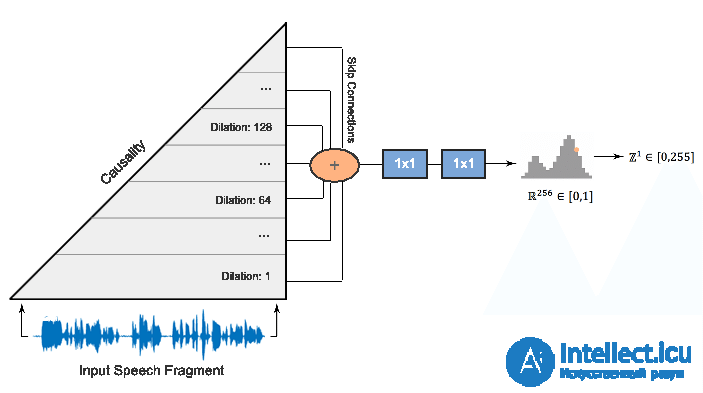
Главный недостаток WaveNet — низкая скорость работы, связанная с последовательной схемой сэмплирования сигнала. Эту проблему можно решить либо с помощью инженерной оптимизации для конкретной архитектуры железа, либо заменой схемы сэмплирования на более быструю.
Оба подхода были успешно реализованы в индустрии. Первый — в Tinkoff.ru, а в рамках второго подхода компания Google представила сеть Parallel WaveNet [10] в 2017 году, наработки которой используются в Google Assistant.
Примерные значения MOS для нейросетевых методов: 4,4—4,5 [5, 11], то есть синтезируемая речь практически не отличается от человеческой.
Достоинства параметрического синтеза:
Недостатки:
Как следует из обзора, методы параметрического синтеза речи, основанные на нейросетях, на текущий момент существенно превосходят по качеству подход unit selection и гораздо проще для разработки. Поэтому для построения собственного движка синтеза мы использовали именно их.
Для обучения моделей было использовано около 25 часов чистой речи профессионального диктора. Тексты для чтения были специально подобраны так, чтобы наиболее полно покрыть фонетику разговорной речи. Кроме того, чтобы добавить синтезу большее разнообразие в интонации, мы попросили диктора читать тексты с выражением, зависящим от контекста.
Архитектура нашего решения концептуально выглядит так:
Благодаря такой архитектуре наш движок генерирует выразительную речь высокого качества в режиме реального времени, не требует построения фонемного словаря и дает возможность управлять ударениями в отдельных словах. Примеры синтезированных аудио можно прослушать, перейдя по ссылке.
А как ты думаешь, при улучшении синтез речи, будет лучше нам? Надеюсь, что теперь ты понял что такое синтез речи и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Автоматический синтез речи
Комментарии
Оставить комментарий
Автоматический синтез речи
Термины: Автоматический синтез речи