Лекция
Привет, Вы узнаете о том , что такое регулярные выражения, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое регулярные выражения, регэкспы, regular expressions, оптимизация регулярных выражений , настоятельно рекомендую прочитать все из категории Операционные системы и системное программировние.
регулярные выражения (" регэкспы ", от англ. Regular Expressions) - мощное средство составления шаблонов, с помощью которых в заданном тексте может проводиться поиск и сопоставление символов любой сложности.
Как составляется такой шаблон? Для этого используются специальные символы, метасимволы и классы (наборы) символов. Регулярное выражение - это простая строка и любые символы в этой строке, которые не являются специальными (зарезервированными), считаются обычными символами.
Регулярные выражения (regex или regexp) очень эффективны для извлечения информации из текста. Для этого нужно произвести поиск одного или нескольких совпадений по определенному шаблону (т. е. определенной последовательности символов ASCII или unicode).
Области применения regex разнообразны, от валидации до парсинга/замены строк(фактически одномерного распознавания), передачи данных в другие форматы и Web Scraping’а.
Одна из любопытных особенностей регулярных выражений в их универсальности, стоит вам выучить синтаксис, и вы сможете применять их в любом (почти) языке программирования (JavaScript, Java, VB, C #, C / C++, Python, Perl, Ruby, Delphi, R, Tcl, и многих других). Небольшие отличия касаются только наиболее продвинутых функций и версий синтаксиса, поддерживаемых движком.
Служебные символы делятся на три класса:
Любое выражение можно сгруппировать (заключить в скобки) и применить оператор ко всей группе.
Синтаксис регулярных выражений, использующийся в nnCron, совпадает с синтаксисом регулярных выражений языка Perl. Небольшие отличия есть только в некоторых расширенных специфических операторах.
Синтаксис
Все регэкспы должны заключаться в прямые слэши (/.../). После конечного слэша могут идти параметры:
| /.../i | - не различать регистр. |
| /.../x | - игнорировать пробелы и переводы строк (для удобства). |
| /.../s | - считать регэксп одной единственной строкой (трактовать спецсимвол . (точка) как "любой символ, в том числе и символ перевода строки"). |
Примеры:
\ совпадет только со словом 'Valery' /Valery/ \ совпадет со словами 'VALERY', 'valery', 'Valery' и т. д. /Valery/i \ совпадет с 'foobar', 'foobar barfoo' /foobar/ \ совпадет с 'foobar', 'FOOBAR', 'foobar and two other foos' / FOO bar /ix \ совпадет с 'Valery%crlf%Kondakoff' /Valery.*Kondakoff/s
Каждый символ регулярного выражения последовательно сравнивается с проверяемой строкой. Все, что не является указанными ниже спецсимволами или операторами, воспринимается, как обычный символ, рассматриваемый на простое совпадение.
Спецсимволы (метасимволы)
| | | Прямой слэш соответствует “или”. | Выражению “day|night” будут удовлетворять и “night”, или и “day”. |
| ^ | Начало строки = символ Каре означает: “Должно начинаться именно так”. | Выражению “^intellect\.icu” будет удовлетворять “intellect.icu/”, но не будет удовлетворять “www.intellect.icu”. |
| $ | Конец строки = символ доллара означает: “Должно заканчиваться именно так” | Выражению “intellect\.icu$” будет удовлетворять и “www.intellect.icu”, но не будет удовлетворять “intellect.icu/”. |
| . | Любой символ кроме переводов строки (без параметра /.../s) | Выражению “.23” будут удовлетворять и “123”, и “223”, и “!23”. |
| ? | Вопросительный знак означает: “Последний элемент является необязательным.” | Вопросительный знак означает: “Последний элемент RegEx является необязательным.” |
| \ | Превращает метасимвол в простой символ. | Выражению “\.” будет удовлетворять именно точка “.”, а не любой символ. “\.23” будет удовлетворять только “.23”, но не “123”. |
| [ ... ] |
Любой из перечисленного набора символов. Внутри квадратных скобок не работают другие операторы, но можно пользоваться метасимволами. Например, [a-f] означает любую букву из числа a, b, c, d, e, f. Перечисленные символы разделять запятыми не нужно. |
Выражению [a-z] будет соответствовать любая буква английского алфавита в нижнем регистре. |
| () | Круглые скобки группируют выражение внутри скобок в единое целое. Круглые скобки часто используются вместе с прямым слэшем, а также для задания переменных $1, $2 и т.д. |
Выражению “(gra)?fat” будут удовлетворять и “gra”, и “fat”. Выражению “grand(fat|ther)” будут удовлетворять и “gra”, и “grather”. |
| [^ ... ] |
Квадратные скобки в сочетании с каре означает: “Любой символ, кроме перечисленных.” Ни один из перечисленного набора символов. Внутри квадратных скобок не работают другие операторы, но можно пользоваться метасимволами.
|
[^0-9] означает любой символы, кроме 0, 1, 2, 3, 4, 5, 6, 7, 8, 9. |
| {} | Фигурные скобки повторяют последнюю часть RegEx заданное число раз. Если указано одно число {x}, то это означает: “Повторить последнюю часть RegEx ровно x раз”. Если указано два числа {x, y}, то это означает: “Повторить последнюю часть RegEx минимум x и максимум y раз”. | Выражению “1\.5\.6\.[0-9]{1,2}” будут соответствовать и IP-адрес “1\.5\.6\.6”, и IP-адрес “1\.5\.6\.75”, и IP-адрес “1\.5\.6\.2”. |
| \# |
Следующий за слэшем символ # (кроме a-z и 0-9). |
|
| \b | Начало слова | |
| \B | Конец слова | |
| \xNN | NN - шестнадцатеричный код ASCII-символа (\x20 - пробел, \x4A - J, \x6A - j и т. д.) | |
| \n | 0x10 (lf) | |
| \r | 0x13 (cr) | |
| \t | 0x09 (tab) | |
| \s | Пробел (tab/space/cr/lf) | |
| \S | Не пробел | |
| \w | Символ слова (буквы, цифры, _) | |
| \W | Символ не-слова | |
| \d | Число | |
| \D | Не число | |
| \u | Символ в верхнем регистре | |
| \l | В нижнем |
Примеры:
\ совпадает со словом 'help' с точкой /help\./ \ совпадает со словами 'cats', 'cars' и т. д. /ca.s/ \ совпадает со словами 'testing', 'tester', но не 'the test' /^test/ \ совпадает с выражением 'see me', но не с 'meter' или 'me and you' /me$/ \ совпадает с одной (латинской) гласной буквой /[aeiou]/ \ совпадает с одной буквой или цифрой /[a-z0-9]/ \ совпадает с 'footer', 'footing', 'a foot', но не с 'afoot' /\bfoot/ \ совпадает с 'afoot', 'foot.' (точка не считается частью слова) \ не совпадает с 'footing' /foot\B/ \ совпадает со словом 'foot' целиком /\bfoot\B/ \ совпадает со словами 'q2w', 'r5t' и т. д. /\D\d\D/
Расширенные спецсимволы
В отличии от обычных символов эти классы не совместимы с перловыми:
| \N | Ссылка внутри регэкспа на его же разобранную скобку, число N - номер нужной группы (скобки). Этот оператор работает с некоторыми ограничениями на тип ссылаемого блока - он работает, только если в ссылаемой скобке нет операторов повторения. |
Пример:
\ совпадает с фразами 'man to man', ' \ hand to hand', '100 to 100' и т. д. (\b\w+\B) to \1
Операторы
Операторы не могут применяться сами по себе, без указания символа, на который они действуют. Оператор действует на определенный перед ним символ (мета или обычный). Если какое-то выражение заключено в скобки, после которых стоит оператор, то он действует на всю скобку.
| ( ... ) | Сгруппировать символы в один паттерн и запомнить | |
| | | Предыдущий или следующий паттерн (логическое "ИЛИ") | |
| * | Ноль или больше раз | Выражению “yuy*” будут удовлетворять и “yum”, и “yuyyyy”. |
| + | Один или больше раз | Выражению “yuy+” будут удовлетворять и “yuy”, и “yuyyyy”. |
| ? | 0 или 1 раз предыдущая маска | |
| {n} | Повторять n раз | |
| {n,} | Повторять n или больше раз | |
| {n,m} | Повторять от n до m раз |
Примеры:
\ совпадает со словами 'cat' или 'mouse'
/(cat)|(mouse)/
\ совпадает со словами 'dogs', 'doggie'
/dog(s|gie)/
\ совпадает с 'ma', 'maaa', 'maaaaaaa'
/ma+/
\ совпадает с 'm', 'maaa'
/ma*/
\ совпадает с 'yada yada yada'
/(yada ){2,}/
\ совпадает с 'fooandbar', 'foobar'
/foo(and)?bar/
Если после оператора добавить ?, то он превращается из жадного в нежадный. К примеру жадный * будет нежадным после замены его на *?. Жадные операторы производят максимальный захват в строке, а нежадные захватывают по минимуму.
Расширенные операторы
| ?#N | Это оператор "просмотра назад". N - число символов для просмотра. |
| ?~N | Отрицание просмотра назад. |
| ?= | Просмотр вперед. |
| ?! | Отрицание просмотра вперед. |
Заметьте, что хотя последние два оператора существуют и в перле, в нем они записываются в виде (?=foobar). В nnCron оператор выглядит как (foobar)?=.
Примеры:
\ совпадет с любым словом, после которого знак табуляции \ при этом сам знак табуляции не войдет в число совпавших символов /\w+(\t)?=/ \ совпадет с любым появлением 'foo', которое не продолжается 'bar' /foo(bar)?!/ \ совпадет с любым появлением 'bar', которому предшествует 'foo' /(foo)?#3bar/
Еще немного примеров:
\ совпадет с "foobar", "bar" /(foo)?bar/ \ совпадет _только_ с "foobar" /^foobar$/ \ совпадет с "foobar", "for", "far" /f[obar]+r/ \ задает любое число с десятичной запятой /([\d\.])+/ \ совпадет с "foofoofoobarfoobar", "bar" /((foo)|(bar))+/
^Привет соответствует строке, начинающейся с Привет пока$ соответствует строке, заканчивающейся на пока^Привет пока$ точное совпадение (начинается и заканчивается как Привет пока)воробушки соответствует любой строке, в которой есть текст воробушки
abc* соответствует строке, в которой после ab следует 0 или более символов c abc+ соответствует строке, в которой после ab следует один или более символов cabc? соответствует строке, в которой после ab следует 0 или один символ cabc{2} соответствует строке, в которой после ab следует 2 символа cabc{2,} соответствует строке, в которой после ab следует 2 или более символов cabc{2,5} соответствует строке, в которой после ab следует от 2 до 5 символов ca(bc)* соответствует строке, в которой после ab следует 0 или более последовательностей символов bca(bc){2,5} соответствует строке, в которой после ab следует от 2 до 5 последовательностей символов bc
a(b|c) соответствует строке, в которой после a следует b или c a[bc] как и в предыдущем примере
\d соответствует одному символу, который является цифрой \w соответствует слову (может состоять из букв, цифр и подчеркивания) \s соответствует символу пробела (включая табуляцию и прерывание строки). соответствует любому символу
Используйте оператор . с осторожностью, так как зачастую класс или отрицаемый класс символов (который мы рассмотрим далее) быстрее и точнее.
У операторов \d, \w и \s также есть отрицания ― \D, \W и \S соответственно.
Например, оператор \D будет искать соответствия противоположенные \d.
\D соответствует одному символу, который не является цифрой
Некоторые символы, например ^.[$()|*+?{\ , необходимо выделять обратным слешем \ .
\$\d соответствует строке, в которой после символа $ следует одна цифра
Непечатаемые символы также можно искать, например табуляцию \t, новую строку \n, возврат каретки \r.
Мы научились строить регулярные выражения, но забыли о фундаментальной концепции ― флагах.
Регулярное выражение, как правило, записывается в такой форме /abc/, где шаблон для сопоставления выделен двумя слешами /. В конце выражения, мы определяем значение флага (эти значения можно комбинировать):
a(bc) создаем группу со значением bc a(?:bc)* оперетор ?: отключает группу a(?bc) так, мы можем присвоить имя группе
Этот оператор очень полезен, когда нужно извлечь информацию из строк или данных, используя ваш любимый язык программирования. Любые множественные совпадения, по нескольким группам, будут представлены в виде классического массива: доступ к их значениям можно получить с помощью индекса из результатов сопоставления.
Если присвоить группам имена (используя (?...)), то можно получить их значения, используя результат сопоставления, как словарь, где ключами будут имена каждой группы.
[abc] соответствует строке, которая содержит либо символ a или a b или a c -> такой же эффект от a|b|c [a-c] то же, что и выше[a-fA-F0–9] строка, представляющая одну шестнадцатеричную цифру без учета регистра [0–9]% строка, содержащая символ от 0 до 9 перед знаком %[^a-zA-Z] строка, которая не имеет буквы от a до z или от A до Z. В этом случае ^ используется как отрицание в выражении -
Помните, что внутри скобочных выражений все специальные символы (включая обратную косую черту \) теряют свое служебное значение, поэтому нам ненужно их экранировать.
Квантификаторы ( * + {}) ― это «жадные» операторы, потому что они продолжают поиск соответствий, как можно глубже ― через весь текст.
Например, выражение <.+> соответствует
в This is a
test. Об этом говорит сайт https://intellect.icu . Чтобы найти только тэг div ― можно использовать оператор ?, сделав выражение «ленивым»:
<.+?> соответствует любому символу, один или несколько раз найденному между < и >, расширяется по мере необходимости
Обратите внимание, что хорошей практикой считается не использовать оператор . , в пользу более строгого выражения:
<[^<>]+> соответствует любому символу, кроме < или >, один или более раз встречающемуся между < и >
\babc\b выполняет поиск слова целиком
\b ― соответствует границе слова, наподобие якоря (он похож на $ и ^), где предыдущий символ ― словесный (например, \w), а следующий ― нет, либо наоборот, (например, это может быть начало строки или пробел).
\B ― соответствует несловообразующей границе. Соответствие не должно обнаруживаться на границе \b .
\Babc\B соответствует, только если шаблон полностью окружен словами
([abc])\1 \1 соответствует тексту из первой захватываемой группы -> ([abc])([de])\2\1 можно использовать \2 (\3, \4, и т.д.) для определения порядкового номера захватываемой группы (?[abc])\k мы присвоили имя foo группе, и теперь ссылаемся на нее используя ― (\k). Результат, как и в первом выражении
d(?=r) соответствует d, только если после этого следует r, но r не будет входить в соответствие выражения -> (?<=r)d соответствует d, только если перед этим есть r, но r не будет входить в соответствие выражения
Вы можете использовать оператор отрицания !
d(?!r) соответствует d, только если после этого нет r, но r не будет входить в соответствие выражения -> (?r)d соответствует d, только если перед этим нет r, но r не будет входить в соответствие выражения
Приведенные ниже примеры показывают, как использовать и составлять простые регулярные выражения. Каждый пример содержит искомый текст, одно или несколько соответствующих ему регулярных выражений, а также примечания, поясняющие использование специальных символов и форматов.
Чтобы получить дополнительную информацию, ознакомьтесь с советами по созданию фильтров содержания с использованием регулярных выражений и посетите страницу на сайте GitHub, посвященную синтаксису RE2. Также прочитайте статью о том, как настроить правила соответствия содержания.
Важно! Поддерживается только синтаксис RE2, который немного отличается от PCRE. Обратите внимание, что регулярные выражения по умолчанию вводятся с учетом регистра.
Примечание. На основе примеров, приведенных ниже, можно составлять более сложные регулярные выражения. Однако для поиска отдельных слов мы рекомендуем использовать параметры Соответствие содержания и Нежелательное содержание.
| Поиск точной фразы | |
|---|---|
| Пример использования | Поиск фразы сборник законов. |
| Примеры регулярных выражений | Пример 1: (\W|^)сборник\законов(\W|$) Пример 2: (\W|^)сборник\s{0,3}законов{0,1}(\W|$) Пример 3: (\W|^)сборник(и)\s{0,3}законов{0,1}(\W|$) |
| Примечания |
|
| Поиск слова или фразы из списка | |
|---|---|
| Пример использования | Поиск любого слова или фразы из приведенного ниже списка:
|
| Пример регулярного выражения | (?i)(\W|^)(проклятие|убирайся|бред|черт\sвозьми|зараза)(\W|$) |
| Примечания |
|
| Поиск слова в разных вариантах написания или со специальными символами | |
|---|---|
| Пример использования | Поиск в нежелательных сообщениях слова "виагра" и нескольких вариантов его написания, например:
|
| Пример регулярного выражения | в[ие№][а@]гр[а@] |
| Примечания |
|
| Поиск любого адреса электронной почты в определенном домене | |
|---|---|
| Пример использования | Поиск любого адреса электронной почты в доменах yahoo.com, hotmail.com и gmail.com. |
| Пример регулярного выражения | (\W|^)[\w.\-]{0,25}@(yahoo|hotmail|gmail)\.com(\W|$) |
| Примечания |
|
| Поиск любого IP-адреса в определенном диапазоне | |
|---|---|
| Пример использования | Поиск любого IP-адреса в пределах диапазона 192.168.1.0–192.168.1.255. |
| Примеры регулярных выражений | Пример 1: 192\.168\.1\. Пример 2: 192\.168\.1\.\d{1,3} |
| Примечания |
|
| Поиск буквенно-цифровой строки | |
|---|---|
| Пример использования | Поиск номеров заказов на покупку, сделанных вашей компанией. Такие номера могут быть представлены в разном формате, например:
|
| Пример регулярного выражения | (\W|^)po[#\-]{0,1}\s{0,1}\d{2}[\s-]{0,1}\d{4}(\W|$) |
| Примечания |
|
Проверка надежности пароля
|
^(?=.*[A-Z].*[A-Z])(?=.*[!@#$&*])(?=.*[0-9].*[0-9])(?=.*[a-z].*[a-z].*[a-z]).{8}$ |
Надежность пароля - довольно субъективное понятие, поэтому не существует универсального решения для проверки. Однако, приведенный выше пример регулярного выражения может стать хорошей отправной точкой, если вы не желаете придумывать выражение для проверки пароля с нуля.
Код цвета в шестнадцатеричном формате
|
\#([a-fA-F]|[0-9]){3, 6} |
Шестнадцатеричные коды цветов используются при веб-разработке очень часто. Это регулярное выражение может быть поможет сравнить: совпадает ли какая-либо строка с шаблоном шестнадцатеричного кода.
Проверка адреса электронной почты
|
/[A-Z0-9._%+-]+@[A-Z0-9-]+.+.[A-Z]{2,4}/igm |
Одной из самых распространенных задач при разработке является проверка соответствия введенной пользователем строки формату адреса электронной почты. Существует множество различных вариантов выражений для решения этой задачи, автор этой статьи предлагает свой оригинальный вариант.
IP-адрес (v4)
|
/\b(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\b/ |
Как e-mail может использоваться для идентификации посетителя, так IP-адрес является идентификатором конкретного компьютера в сети. Приведенное регулярное выражение проверяет соответствие строки формату IP-адреса v4.
IP-адрес (v6)
|
(([0-9a-fA-F]{1,4}:){7,7}[0-9a-fA-F]{1,4}|([0-9a-fA-F]{1,4}:){1,7}:|([0-9a-fA-F]{1,4}:){1,6}:[0-9a-fA-F]{1,4}|([0-9a-fA-F]{1,4}:){1,5}(:[0-9a-fA-F]{1,4}){1,2}|([0-9a-fA-F]{1,4}:){1,4}(:[0-9a-fA-F]{1,4}){1,3}|([0-9a-fA-F]{1,4}:){1,3}(:[0-9a-fA-F]{1,4}){1,4}|([0-9a-fA-F]{1,4}:){1,2}(:[0-9a-fA-F]{1,4}){1,5}|[0-9a-fA-F]{1,4}:((:[0-9a-fA-F]{1,4}){1,6})|:((:[0-9a-fA-F]{1,4}){1,7}|:)|fe80:(:[0-9a-fA-F]{0,4}){0,4}%[0-9a-zA-Z]{1,}|::(ffff(:0{1,4}){0,1}:){0,1}((25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9])\.){3,3}(25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9])|([0-9a-fA-F]{1,4}:){1,4}:((25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9])\.){3,3}(25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9])) |
Вы также можете проверить строку на соответствие формату IP-адреса новой, шестой версии более продвинутым регулярным выражением.
Разделитель в больших числах
|
/\d{1,3}(?=(\d{3})+(?!\d))/g |
Традиционными разделителями в больших числах являются запятые, точки или другие знаки, повторяющиеся в числе через каждые 3 символа. Приведенный код регулярного выражения работает с любым числом и любым определенными вами символами для разделения трехзначных частей в больших числах: тысячах, миллионах и т.п.
Добавление протокола перед гиперссылкой
|
if (!s.match(/^[a-zA-Z]+:\/\//)) { s = 'http://' + s; } |
Независимо от того, с каким языком вы работаете: JavaScript, Ruby или PHP, это регулярное выражение может оказаться очень полезным. С его помощью проверяется любой URL-адрес на наличие в строке протокола, и если протокол отсутствует, указанный код добавляет его в начало строки.
Получение хоста или домена из URL-адреса.
|
/https?:\/\/(?:[-\w]+\.)?([-\w]+)\.\w+(?:\.\w+)?\/?.*/i |
Как известно, любой URL-адрес состоит из нескольких частей: вначале указывается протокол (HTTP или HTTPS), иногда за ним идет субдомен, а в завершении добавляется путь к странице. Вы можете использовать это выражение, чтобы вернуть только доменное имя, исключив все остальные части адреса.
Сортировка ключевых фраз по количеству слов
|
^[^\s]*$ //соответствует одному ключевому слову ^[^\s]*\s[^\s]*$ //соответствует фразе из 2 ключевых слов ^[^\s]*\s[^\s]* //соответствует фразе, содержащей по крайней мере 2 кючевых слова ^([^\s]*\s){2}[^\s]*$ //соответствует фразе из 3 ключевых слов ^([^\s]*\s){4}[^\s]*$ //соответствует фразе из 5 и более ключевых слов |
Это действительно полезные выражения для пользователей Google Analytics и инструмента для веб-мастеров. Ведь с помощью них можно отсортировать ключевые фразы, используемые посетителями при поиске по количеству слов, входящих в них.
Выражения могут проверять фразы, содержащие определенное количество слов (например, 5), а также фразы количество слов в которых более двух, трех и т.д. Одно из самых мощных выражений, используемое для сортировки данных аналитики.
Поиск валидной строки Base64 в PHP
|
\?php[ \t]eval\(base64_decode\(\'(([A-Za-z0-9+/]{4})*([A-Za-z0-9+/]{3}=|[A-Za-z0-9+/]{2}==)?){1}\'\)\)\; |
Если вы являетесь PHP-разработчиком, то иногда вам может понадобиться найти объект, закодированный в формате Base64. Указанное выше выражение может использоваться для поиска закодированных строк в любом PHP-коде.
Проверка телефонного номера
|
^\+?\d{1,3}?[- .]?\(?(?:\d{2,3})\)?[- .]?\d\d\d[- .]?\d\d\d\d$ |
Это регулярное выражение применяется для проверки любого номера телефона, прежде всего, американского формата телефонных номеров.
Для проверки российских телефонных номеров используйте следующее выражение:
|
^((\+?7|8)[ \-] ?)?((\(\d{3}\))|(\d{3}))?([ \-])?(\d{3}[\- ]?\d{2}[\- ]?\d{2})$ |
Однако в реальности телефонный номер это просто набор 15 цифр с знаком плюс в начале БЕЗ символов дефизов и скобок. пример в этом формате номера не могут начинаться с 0, если они начинатся с нуля или 8 то это возможно друго локальный или устаревший формат
Начальные и конечные пробелы
|
^[ \s]+|[ \s]+$ |
Используйте это регулярное выражение для того, чтобы избавиться от начальных и конечных пробелом в строке. Это не особо распространенная задача, но иногда это выражение может быть полезным. Например, при получении данных из БД или передачи строки скрипту в другой кодировке.
Получение HTML-код изображения
|
\< *[img][^\>]*[src] *= *[\"\']{0,1}([^\"\'\ >]*) |
Если по какой-либо причине вам необходимо «вытянуть» HTML-код изображения прямо из кода страницы, это регулярное выражение станет для вас идеальным решением. Хотя оно может без проблем работать на стороне сервера, для фронтенд-разработчиков приоритетней будет использовать метод attr() библиотеки jQuery вместо указанного регулярного выражения.
Проверяем дату на соответствие формату DD/MM/YYYY
|
^(?:(?:31(\/|-|\.)(?:0?[13578]|1[02]))\1|(?:(?:29|30)(\/|-|\.)(?:0?[1,3-9]|1[0-2])\2))(?:(?:1[6-9]|[2-9]\d)?\d{2})$|^(?:29(\/|-|\.)0?2\3(?:(?:(?:1[6-9]|[2-9]\d)?(?:0[48]|[2468][048]|[13579][26])|(?:(?:16|[2468][048]|[3579][26])00))))$|^(?:0?[1-9]|1\d|2[0-8])(\/|-|\.)(?:(?:0?[1-9])|(?:1[0-2]))\4(?:(?:1[6-9]|[2-9]\d)?\d{2})$ |
Проверять даты сложно, потому что они могут быть представлены в различных форматах, в том числе содержащих и числа, и текст.
В PHP имеется отличная функция date(), но она не всегда подходит, ведь в нее может быть передана необработанная строка. Поэтому для проверки указанного формата даты нужно использовать приведенное выше регулярное выражение.
Совпадение строки с адресом видеоролика на YouTube
|
/http:\/\/(?:youtu\.be\/|(?:[a-z]{2,3}\.)?youtube\.com\/watch(?:\?|#\!)v=)([\w-]{11}).*/gi |
На протяжении нескольких лет на Youtube не меняется структура URL-адресов. Youtube является самым популярным видео хостингом в Интернет, благодаря этому, видео с Youtube набирают наибольший трафик.
Если вам необходимо получить ID какого-либо видеоролика с Youtube, воспользуйтесь приведенным выше регулярным выражением. Это наилучшее выражение, подходящее для всех вариантов URL-адресов на этом видео-хостинге.
Проверка ISBN
|
/\b(?:ISBN(?:: ?| ))?((?:97[89])?\d{9}[\dx])\b/i |
Информация обо всех печатные изданиях, хранится в системе, известной как ISBN, которая состоит из 2 систем: ISBN-10 и ISBN-13. Неспециалисту очень сложно увидеть различия между этими системами. Однако, представленное выше регулярное выражение позволяет проверять соответствие кода ISBN сразу обоим системам: будь то ISBN-10 или ISBN-13. Код написан на PHP, поэтому это решение подходит исключительно для веб-разработчиков.
Проверка почтового индекса (Zip Code)
|
^\d{5}(?:[-\s]\d{4})?$ |
Обращаем ваше внимание, что это выражение подходит только для проверки американских почтовых индексов. Для индексов других стран необходима настройка.
Для проверки российских почтовых индексов используйте следующее выражение:
|
^\d{6}$ |
Проверка правильности имени пользователя Twitter
|
/@([A-Za-z0-9_]{1,15})/ |
Это небольшое регулярное выражение помогает найти имя пользователя Twitter внутри текста. Оно проверяет наличие имени в твитах по шаблону: @username.
Проверка номера кредитной карты
|
^(?:4[0-9]{12}(?:[0-9]{3})?|5[1-5][0-9]{14}|6(?:011|5[0-9][0-9])[0-9]{12}|3[47][0-9]{13}|3(?:0[0-5]|[68][0-9])[0-9]{11}|(?:2131|1800|35\d{3})\d{11})$ |
Проверка номера кредитной карты очень часто проводится при осуществлении платежей в различных платежных онлайн -системах. Однако, регулярное выражение обеспечивает минимальную проверку стандартной кредитной карты.В некоторых закрытых транах имеются нестандартные номера карт , например в Китае или России.
Вы можете ознакомиться с более полным списком кодов для детальной проверки карт. Список включает в себя такие системы как Visa, MasterCard, Discover и многие другие.
Поиск CSS-атрибутов
|
^\s*[a-zA-Z\-]+\s*[:]{1}\s[a-zA-Z0-9\s.#]+[;]{1} |
Ситуация, когда придется воспользоваться указанным регулярным выражением, может сложиться очень редко, но не факт что не сложится никогда
Этот код можно использовать когда будет необходимо «вытянуть» какое-либо CSS-правило из списка правил для какого-нибудь селектора.
Удаление комментариев в HTML
|
|
Если вам необходимо удалить все комментарии из блока HTML-кода, воспользуйтесь этим регулярным выражением. Чтобы получить желаемый результат, вы можете воспользоваться PHP-функцией preg_replace().
Проверка на соответствие ссылке на Facebook-аккаунт
|
/(?:http:\/\/)?(?:www\.)?intellect\.com\/(?:(?:\w)*#!\/)?(?:pages\/)?(?:[\w\-]*\/)*([\w\-]*)/ |
Если вам необходимо узнать у посетителя вашего сайта адрес его странички в Facebook, попробуйте это регулярное выражение. Оно поможет вам проверить правильность указанного пользователем URL. Этот код отлично подходит для проверки ссылок в этой соцсети.
Проверка версии Internet Explorer
|
^.*MSIE [5-8](?:\.[0-9]+)?(?!.*Trident\/[5-9]\.0).*$ |
Несмотря на то, что Microsoft выпустил новый браузер Edge, многие пользователи до сих пор пользуются Internet Explorer. Веб-разработчикам часто приходится проверять версию этого браузера, чтобы учитывать особенности разных версий при работе над своими проектами.
Вы можете использовать это регулярное выражения в JavaScript-коде чтобы узнать какая версия IE (5-11) используется.
Парсинг цены из строки
|
/(\$[0-9,]+(\.[0-9]{2})?)/ |
Цена какого-либо товара может быть указана в различных форматах: в ней могут встречаться запятые, знаки после запятой и символы валюты.
Указанное выше регулярное выражение учитывает различные форматы отображения цены, с его помощью вы сможете «вытянуть» цену из любой символьной строки.
Разбираем заголовки в e-mail
|
/\b[A-Z0-9._%+-]+@(?:[A-Z0-9-]+\.)+[A-Z]{2,6}\b/i |
С помощью этого небольшого выражения вы сможете разобрать заголовок e-mail сообщения, чтобы извлечь оттуда список адресатов. Выражение может быть использовано и в случае, если адресатов несколько.
Вместо регулярных выражений, для разбора заголовков e-mail вы можете воспользуйтесь библиотекой на PHP.
Соответствие имени файла определенному типу
|
/^(.*\.(?!(htm|html|class|js)$))?[^.]*$/i |
Если в вашем приложении существует возможность загрузки файлов на сервер, это регулярное выражение может помочь вам проверить файлы перед тем как посетитель их загрузит.
С помощью этого кода можно получить расширение загружаемого файла и проверить присутствует ли оно в списке разрешенных к загрузке.
Соответствие строки формату URL
|
/[-a-zA-Z0-9@:%_\+.~#?&//=]{2,256}\.[a-z]{2,4}\b(\/[-a-zA-Z0-9@:%_\+.~#?&//=]*)?/gi |
Регулярное выражение может проверять URL-адреса с указанием протоколов HTTP и HTTPS на предмет соответствия синтаксису доменов TLD.
Существует простой способ проверки с использованием JavaScript RegExp.
Добавление атрибута rel=”nofollow” в теге ссылки
|
(]*)(href="/https?://)((?!(?:(?:www\.)?'.implode('|(?:www\.)?', $follow_list).'))[^"]+)"((?!.*\brel=)[^>]*)(?:[^>]*)> |
Если вы много работаете с HTML-кодом, то вам захочется автоматизировать часто повторяющиеся действия. Регулярные выражения отлично подходят для решения этой задачи и сэкономят много вашего времени.
Используя приведенный код, например, совместно с PHP, вы сможете «вытянуть» код ссылок из блоков HTML-кода и добавить в каждую из них атрибут rel=”nofollow”.
Работа с media query
|
/@media([^{]+)\{([\s\S]+?})\s*}/g |
Вы можете разбивать строки содержащие медиа-запросы на части, состоящие из параметров и свойств. Указанное выражение может быть полезно для анализа стороннего CSS-кода. Используя его вы сможете, например, более подробно понять как устроен чужой код.
Синтаксис поисковых выражений Google
|
/([+-]?(?:'.+?'|".+?"|[^+\- ]{1}[^ ]*))/g |
Вы можете составить свои собственные регулярные выражения для манипулирования результатами поиска по вашим запросам в поисковой системе Google. Например, знак плюс (+) добавляет дополнительные ключевые слова, а минус (-) означает, что слова должны быть проигнорированы и удалены из результатов.
Это довольно сложное выражение, но если разобраться как использовать его должным образом, приведенный код может стать основой для построения собственного алгоритма поиска.
Регулярные выражения со следующими символами не поддерживаются, так как могут привести к задержкам при обработке вашего письма:
Вы можете оптимизировать регулярное выражение, используя атомную(Atomic Grouping) группировку или используя притяжательные(Possessive Quantifiers) кванторы где возможно.
Кроме того, если у вас есть такие вещи, как .* или .+ в вашем регулярном выражении, которые могут быть реальными проблемами с памятью/временем выполнения, замените их на (притяжательный) символьные(Character Classes/ Sets) классы (опять же, если это возможно).
Здесь мы говорим и о «микрооптимизациях». и о мощной оптимизации. На этой странице я взял один трюк со страницы синтаксических уловок и несколько оптимизаций, которые нашел в книге Джеффри Фридла Mastering Regex Expressions, и протестировал, как одна конкретная версия одного конкретного движка (PCRE 8.12) используется в одной конкретной версии одного конкретного языка ( PHP ) отвечает на каждый из них.На каком-то этапе я хотел бы запустить те же тесты в .NET, Python, Java, JavaScript и Ruby.
В уловке имитации чередования, количественно определяемого звездой , мы видим, что  можно развернуть на
можно развернуть на 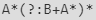 . Есть ли временная выгода от отказа от чередования?
. Есть ли временная выгода от отказа от чередования?
Используя pcretest , я сравнил два шаблона с этой строкой: 44e223eae7e7e7e9876e14ou
Шаблоны: 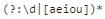 и
и 
Исходный шаблон (с чередованием) компилируется быстрее: 1,6 миллионной секунды против 2,2 для развернутой версии. Однако он работает намного медленнее: 1,7 миллионной секунды против 0,8.
Это кажется потенциально полезной оптимизацией для реализации на уровне движка (в собственном коде ее немного сложно поддерживать).
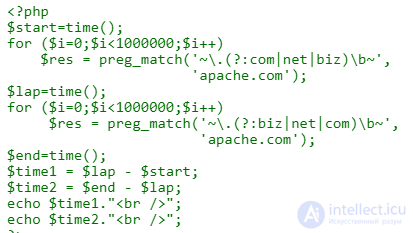
Двигатель читает слева направо. В мире веб-адресов точка-ком встречается чаще, чем точка-сеть и точка-бизнес, поэтому, если вы проверяете эти три домена в пуле случайных имен, теоретически вы должны написать
\. (?: com | net | biz) \ bскорее, чем
\. (?: biz | net | com) \ b
На практике в PCRE, похоже, нет разницы - я прогнал два шаблона два миллиона раз и сравнил результаты. Если вы хотите провести собственное тестирование, вот (очень простой) код, который я использовал для этого теста.
Механизмы регулярных выражений соответствуют быстрее всего, когда якоря и буквальные символы находятся прямо в основном шаблоне, а не скрыты в подвыражениях. Отсюда совет - «раскрывать» буквальные символы всякий раз, когда вы можете убрать их из альтернативного или количественного выражения. Давайте посмотрим на два примера.
Пример 1:  должно быть быстрее, чем
должно быть быстрее, чем  . Они означают одно и то же: хотя бы один A , возможно, за которым следуют еще символы A.
. Они означают одно и то же: хотя бы один A , возможно, за которым следуют еще символы A.
Я запустил эти два шаблона два миллиона раз в строке BBBCCC . Оба заняли одинаковое количество времени. Это говорит мне о том, что механизм PHP PCRE должен быть «вежливым» в том, что касается этой оптимизации, то есть он делает это за вас. Просто используйтеА +.
Пример 2:  должно быть быстрее, чем
должно быть быстрее, чем  .
.
Я запустил эти два шаблона два миллиона раз на строке that . Второй («менее оптимальный») шаблон был на самом деле быстрее на восемь процентов, зарабатывая мне полмиллионную долю секунды за пробежку, ничего особенного. Опять же, оптимизация должна быть встроена в механизм регулярных выражений PCRE PHP. Возможно, теоретически «более оптимальный» паттерн где-то проиграет в компиляции.
Стоит ли его использовать?
Что касается скорости, ответ зависит от двигателя, который вы используете. Для меня, независимо от того, какой движок я использую, решение - это удобочитаемость, а значит, ремонтопригодность.
Например, если я сопоставляю все числа от 10 до 19 , я всегда выделяю 1 и использую1 [0-9]. Для меня это легче читать и поддерживать, чем записывать каждое число по буквам, тем более, что при работе с более сложным диапазоном чисел.
С другой стороны, если бы я создавал регулярное выражение для всех двухбуквенных сокращений штатов в США, я бы произнес их по буквам:\ b (?: AL | AK | AZ |…) \ b. Я бы сделал это, даже если у меня под рукой есть инструменты, которые автоматически сжимают длинные чередования в их оптимизированные аналоги ( regex-opt в C, Regexp :: Assemble и Regexp :: Assemble :: Compressed в Perl).
Это потому, что в любой день недели я бы предпочел отладить это:

чем это:

Якоря в начале и в конце строки ^ и $может сэкономить вашему регулярному выражению много отката в случаях, когда совпадение обязательно не удастся.
Теоретически,^. * abc терпит неудачу быстрее, чем . * abc. Я запускал это два миллиона раз на «строке сбоя» (сорок z символов подряд). Как и в последнем примере, «менее оптимальный» шаблон был быстрее на восемь процентов, принося мне полмиллионную долю секунды за каждое выполнение. Опять же, PCRE звучит вежливо. Потерянное время может быть связано с обработкой лишнего якоря.
Также рекомендуется обнажать анкеры, что означает, когда возможно, вынимать анкеры из скобок чередования. Например,
^ (?: abc | def) предпочтительнее ^ abc | ^ def.
Я запускал каждую из этих двух функций preg_match два миллиона раз.

Первый сохранил мне одну секунду (из четырнадцати). С одной стороны, это улучшение на семь процентов.
С другой стороны, за один прогон это всего лишь улучшение на полмиллионную долю секунды.
Стоит ли его использовать?
Я использую якоря везде, где могу, из соображений хорошего стиля - и избегая ненужных откатов. Что касается того, выставлять ли их вне чередования, я обычно тоже так делаю, не потому, что это быстрее, а потому, что это имеет тенденцию быть более читаемым.
Последний метод, который я попробовал, - это то, что Джеффри называет «распределением в чередование»:

Этот метод действительно ускорил сценарий на семь процентов, сэкономив миллионную долю секунды за запуск.
Я буду им пользоваться? Возможно нет. Мне нравится обнажать границы.
PCRE имеет модификатор «Study», который можно пометить в конце паттерна. Для шаблонов, которые не начинаются с фиксированного символа и не привязаны, этот модификатор заставляет механизм регулярных выражений еще немного изучить строку перед применением шаблона, на всякий случай, если можно будет обнаружить некоторые оптимизации.
Чтобы использовать этот режим, добавьте заглавную S после закрывающего разделителя, например:

По-видимому, этот режим изучения может быть полезен при анализе длинных документов, таких как веб-страницы. Может и не поможет, но стоит меньше ста тысячных секунды.
Вам может показаться что «микрооптимизации» в Mastering Regex Expressions не ускоряют код. Значит ли это, что они плохие? Напротив. Однако, я предлагаю вам забыть о «микрооптимизациях», подобных тем, которые представлены в этом разделе. Хороший стиль важнее.
Просто напишите работающее регулярное выражение, сосредотачиваясь на общей картине, чтобы избежать шаблонов, которые замедляют вас на порядки. В основном это означает разумное использование якорей, квантификаторов (ленивый или жадный), групп (атомарно или с возвратом) и всего, что может сделать ваше регулярное выражение более конкретным, чем слишком распространенный суп из точек и звездочек. - такие как буквальные символы и отрицательные классы.
Регулярные выражения очень удобны, но, к сожалению, они реализуются, по крайней мере, немного иначе, везде, где вы их используете . Если бы я вдавался в подробности, у меня была бы книга, а не страница заметок.

Как вы могли убедиться, области применения регулярных выражений разнообразны. Я уверен, что вы сталкивались с похожими задачами в своей работе (хотя бы с одной из них), например такими:
Путь к пониманию регулярных выражений довольно труден, однако, если вы будете его придерживаться, результат вас не разочарует. Попробуйте использовать приведенные в статье регулярные выражения при создании своего веб-приложения. Таким образом вы сможете понять как работают выражения из примеров, приведенных в статье, в реальности.
Если у вас есть свои примеры полезных регулярных выражений, вы можете добавить их в качестве комментария к этой статье.
Исследование, описанное в статье про регулярные выражения, подчеркивает ее значимость в современном мире. Надеюсь, что теперь ты понял что такое регулярные выражения, регэкспы, regular expressions, оптимизация регулярных выражений и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Операционные системы и системное программировние
Комментарии
Оставить комментарий
Операционные системы и системное программировние
Термины: Операционные системы и системное программировние