Лекция
Привет, Вы узнаете о том , что такое технологические решения хранилищ данных, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое технологические решения хранилищ данных, архитектура хранилищ данных, управление складами данных, фрактальные методы в архивации , настоятельно рекомендую прочитать все из категории Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL.
Для интеграции в реальном времени существующий пакетный метод нужно заменить на процессы, которые непрерывно отслеживают состояние исходных систем, фиксируют и преобразуют изменения в данных по мере их возникновения, а затем загружают эти изменения в Хранилище; и чем режим их работы ближе к реальному времени, тем лучше.
В последнее время новые технологии, такие как передача сообщений (messaging) и интеграция корпоративных приложений (EAI), обеспечили лучшие возможности построения активных Хранилищ данных и более качественную интегрированную аналитику.
Одной из главных целей разработки ХД является информационное обеспечение компьютерной поддержки принятия решений по всем или основным видам деятельности организации. Каждый вид деятельности организации является отдельной задачей, решение которой может быть, а может и не быть увязано с решением других задач в рамках организации. Вид деятельности организации или направление бизнеса совместно со спектром соответствующих ему бизнес-задач определяют предметную область ХД. Например, компания производит и продает оборудование для добычи газа, а с другой стороны, та же компания имеет подразделения, которые занимаются производством услуг в области автоматизации предприятий, в том числе и газодобывающих. Источники прибыли в этих случаях различны. Это два направления бизнеса компании (две предметных области). Общими задачами анализа данных для этих направлений бизнеса являются прибыль и бюджет.
ХД – это сложная компьютерная система. Под архитектурой ХД понимают совокупность программно-аппаратных компонент, совокупность технологических и организационных решений, предпринимаемых для создания, разработки и функционирования ХД, т.е. выбор аппаратного и программного обеспечения, выбор способов взаимодействия программно-аппаратных компонент, выбор способа решения проектной задачи по разработке и созданию ХД. Как правило, архитектуру ХД составляют следующие компоненты:
Кроме этого, необходимы специальные программные средства проектирования хранилища, средства работы с репозиторием метаданных и собственно средства оперативной аналитики, или OLAP-средства.
Все это – сложное специальное программное обеспечение, стоимость которого также может исчисляться десятками и сотнями тысяч долларов.
Характер и масштаб решаемых задач анализа данных организации оказывает решающее значение на выбор архитектуры ХД и методы его проектирования. Проектировщик должен помнить, что, с одной стороны, ХД создается для решения конкретных, строго определенных задач анализа и воспроизводства новых данных, с другой — ХД должно обеспечивать корпоративную отчетность в рамках всей организации. Таким образом, определяющим моментом в построении ХД являются задачи обработки и анализа данных, производства и доставки отчетов.
Характер и масштаб решаемых задач анализа данных определяет и подходы к выбору архитектуры и проектированию ХД.
Желательно, чтобы выбор архитектуры ХД был сделан до начала его реализации, однако на практике не всегда следуют этому правилу. Задержка с выбором архитектуры ХД обычно приводит к пересмотру проделанной работы в свете новых принятых решений и, как правило, к увеличению объема работы.
Выбор архитектуры ХД относится к сфере компетенции руководителя ИТ-проекта по созданию системы складирования данных. На такой выбор влияют несколько различных факторов: инфраструктура организации, производственная и информационная среда организации, управление и контроль, масштабы проекта, возможности аппаратно-технологического обеспечения, готовность персонала и имеющиеся ресурсы.
Выбор подхода к конкретной реализации ХД также лежит в области влияния руководителя ИТ-проекта. Правильный выбор архитектуры ХД обычно определяет успех конкретного проекта по созданию системы складирования данных.
Существует несколько факторов, влияющих на принятие решений о выборе способа реализации: время, отведенное на проект, возврат инвестиций, скорость ввода ХД в эксплуатацию, потребности пользователей, потенциальные угрозы по переделке, требования к ресурсам, необходимым в определенный момент времени, выбранная архитектура ХД, совокупная стоимость владения ХД.
Проектировщик ХД должен знать, какие возможные решения могут быть приняты по архитектуре ХД и какой объем работ по проектированию ХД они повлекут. Выбор архитектуры будет определять, где ХД и/или киоски данных будут расположены и как ими будут организационно-технологически управлять. Например, данные могут быть расположены в центральном офисе организации, т.е. будут поддерживаться централизованно. Данные могут быть распределены по офисам организации или располагаться в филиалах организации, и могут поддерживаться как централизованно, так и независимо друг от друга.
Далее приводится краткий обзор типовых архитектур систем складирования данных и программных продуктов, наиболее часто используемых для реализации систем складирования данных.
XML и обмен сообщениями
В конце 90-х компании рассматривали XML как универсальное средство для передачи своевременных транзакционных данных в Хранилище. Идея состояла в том, чтобы по мере возникновения транзакций обеспечивать постоянные синхронные обновления систем поддержки принятия решений. Но, хотя эта концепция и казалась простой, у нее есть ряд скрытых особенностей. Во-первых, для каждой операции транзакционная система должна генерировать документ в фиксированном формате, а это может оказаться затратным по времени. Во-вторых, документы часто становятся большими по объему за счет тэгов и метаданных. Например, транзакции на основе протокола XMPP (extensible messaging and presence protocol — расширяемого протокола сообщений и присутствия) содержат для каждой точки данных открывающие и закрывающие тэги.
То есть сама запись содержит только 8 символов, а передаваемый документ — 55 символов. Еще больший объем возникает в результате описания типов, заголовков и т.п. В результате XML-протоколы не могут широко использоваться в очень крупных Хранилищах, куда поступают миллионы транзакций в день. Однако XML очень удобен при передаче коротких сообщений, а также и в web-приложениях для передачи транзакций в СУБД.
Отдельные поставщики выбрали иной подход к обмену сообщениями и создали стандарты интерфейсов, такие как электронный обмен данными (electronic data interchange — EDI), или IDocs, которые упрощают форматирование и передачу транзакционных записей. Сокращение накладных расходов, связанное с использованием этих форматов, позволило компаниям автоматически передавать записи в свои вновь созданные Хранилища в реальном времени.
Мгновенная передача сообщений для операционной отчетности в Хранилище данных
В 2003 году, основными претендентами в стандартизации мгновенной передачи сообщений были XMPP и SIMPLE.
Как уже говорилось, XMPP удобен для обработки коротких записей, например SMS-трафика. Но вызывает серьезные накладные расходы при передачи больших объемов транзакций. С другой стороны, недостаток его конкурента (SIMPLE) состоит в том, что он обеспечивает поддержку для простых текстовых сообщений, но не работает для других форматов.Поэтому каждому поставщику приходится разрабатывать свои собственные расширения, которые в итоге оказываются несовместимыми. Еще одна проблема с протоколом SIMPLE — это поддержка протоколов старых пользовательских данных (user data protocol — UDP), а также протокола TCP на уровне передачи. Поскольку UDP не предусматривает серьезного контроля качества, то пакеты данных могут быть потеряны, а возможности возобновления и контроля процесса ограничены. Это очень плохо для крупных систем отчетности, качество работы которых напрямую зависит о своевременных, точных и полных данных.
Таким образом, первые версии SIMPLE не получили широкого применения для Хранилищ данных в реальном времени и систем отчетности.
Microsoft становится поставщиком средств интеграции приложений
Хотя с протоколом SIMPLE возникает ряд проблем, тем не менее, он стал хорошей платформой для многих поставщиков. В 2003 году компания Microsoft разработала проект под названием Real-Time Communication Server, расширяющий протокол SIMPLE. А в 2004 году была запущена новая версия продукта для передачи сообщений, известного под названием BizTalk Server 2004. Он был призван решать две важные цели. В первую очередь, предполагалось обеспечение интеграции B2B . Во-вторых, этот продукт должен был стать платформой для интеграции корпоративных приложений, в том числе транзакционных систем и средств отчетности внутри организации.
Компания Microsoft обеспечила более удобную альтернативу очень сложному процессу стандартизации, который охватывал несколько десятков пересекающихся стандартов и подходов к EAI. Ключевая архитектура BizTalk Server — это упрощенная серверная система. Для поддержки принятия решений в EAI инфраструктуре Biztalk обеспечивает услуги бизнес-операций (Business Activity Services — BAS), устанавливаемые на исходной системе для обеспечения сообщений. Кроме того, администратор Хранилища может отслеживать процесс загрузки из нескольких исходных систем, используя инструмент мониторинга бизнес-операций (BAM), входящий в состав Biztalk.
Biztalk 2004 был хорошим шагом вперед в области EAI. В процессе развития продукт был дополнен средствами балансировки загрузки сети (network load balancing — NLB) и расширенной консолью управления (enhanced management console — MMC), предназначенной для удаленного управления и конфигурирования множество исходных систем с установленной услугой BAS. В 2006 году вышла новая версия BizTalk Server 2006, вобравшая в себя ряд конструктивных изменений.
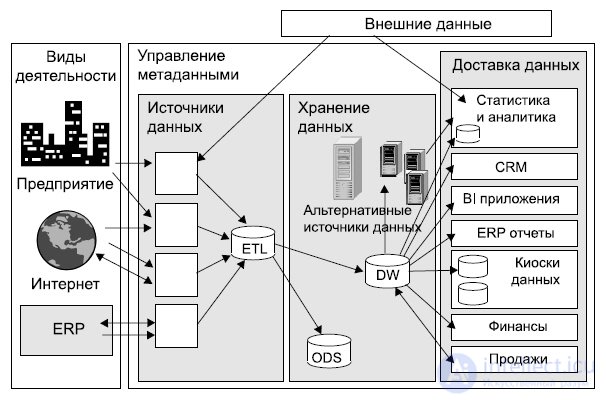
На рис. 2.1 приведена типовая обобщенная концептуальная схема для архитектуры ХД. В конкретных решениях по архитектуре ХД некоторые компоненты схемы могут отсутствовать.
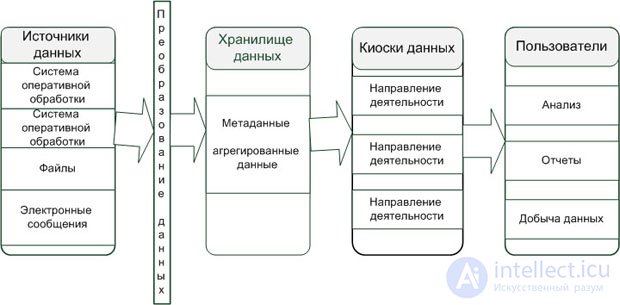
Компоненты типовой архитектуры хранилища данных
Типовыми архитектурами для систем складирования данных принято считать следующие:
Глобальное хранилище данных (Global data warehouse), или хранилище данных масштаба организации, — это такое ХД, в котором будут поддерживаться все данные организации или большая их часть. Это наиболее полное интегрированное ХД с высокой степенью интенсивности доступа к консолидированным данным и использованием его всеми подразделениями организации или руководством организации в рамках основных направлений деятельности организации. Таким образом, глобальное ХД проектируется и конструируется на основе потребностей аналитической информационной поддержки организации в целом. Его можно рассматривать как общий репозиторий для данных, обеспечивающих принятие решений.
Глобальное ХД необязательно должно быть реализовано физически как централизованное. Термин "глобальное" используется для отражения масштаба использования и доступа к данным в рамках всей организации. Глобальное ХД может быть физически как централизованным, так и распределенным.
Централизованное глобальное ХД характерно для организаций, расположенных территориально в одном здании. Оно поддерживается отделом информационных систем организации. Распределенное глобальное ХД также может быть использовано в рамках организации в целом. Оно физически распределяется по подразделениям организации и также поддерживается отделом информационных систем.
Поддержка ХД отделом информационных систем вовсе не означает, что именно эта служба управляет ХД. Например, отдельные части распределенного ХД могут управляться в рамках подразделений или направлений бизнеса.
Управление ХД определяет, кто решает:
Таким образом, для глобального ХД существуют два основных архитектурных решения, как показано на рис. 2.2.
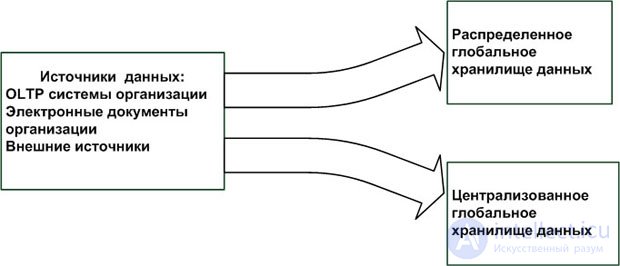
Данные для ХД обычно извлекаются из OLTP-систем организации, электронных документов организации и внешних источников данных. После фильтрации, очистки и преобразования они помещаются в ХД. Затем пользователи получают доступ к этим данным в соответствии с правилами управления доступом к данным, принятыми в организации.
Преимуществом глобального ХД является предоставление конечным пользователям доступа к информации в масштабах предприятия, недостатком — высокие затраты на реализацию, в том числе затраты времени на создание ХД.
Независимые киоски данных включают в себя автономные или независимые киоски данных (Stand-alone Data Marts), которые управляются рабочими группами, отделами или направлениями бизнеса и разрабатываются исключительно для реализации аналитических потребностей последних. Вполне возможно, что при этом не существует никакой связи между ними. Например, данные для таких киосков данных могут генерироваться непосредственно в самих подразделениях организации. Данные могут извлекаться из OLTP-систем, в частности, при помощи информационных служб организации. Информационные службы могут поддерживать вычислительную среду для киосков данных, но не управляют информацией в них. Данные в киоски могут поступать и из глобального ХД.
Для организации независимых киосков данных требуются некоторые профессиональные и технические навыки. Как правило, для их создания выделяются ресурсы и персонал в рамках того подразделения, для которого они создаются. Такой тип реализации ХД оказывает минимальное влияние на информационные ресурсы организации и может быть выполнен очень быстро. В то же время максимальная независимость и минимальная интеграция, а также отсутствие глобального представления о данных организации могут стать ограничением такой архитектуры.
Киоски данных могут быть взаимозависимы или взаимосвязаны (так называемые связанные киоски данных ). Такая архитектура ХД включает в себя совокупность киосков данных, которые управляются рабочими группами, отделами или направлениями бизнеса, но разрабатываются в рамках единой для организации схемы удовлетворения информационных и аналитических потребностей. Для взаимосвязанных киосков данных типична распределенная архитектура реализации. Несмотря на то, что отдельные киоски данных реализуются в рамках рабочих групп, подразделений и направлений бизнеса, они могут быть интегрированы, т.е. взаимосвязаны, для того чтобы обеспечить представления данных в рамках организации в целом. Фактически, на наиболее высоком уровне интеграции, они могут стать глобальным ХД. В такой архитектуре пользователи одних подразделений могут получать доступ к данным других подразделений в рамках своих полномочий.
Требования интеграции данных в рамках архитектуры взаимосвязанных киосков данных делают реализацию ХД более сложной по сравнению с независимыми киосками данных. Например, необходимо решить вопрос, кто будет управлять данными в киосках данных и кто будет поддерживать вычислительную среду. Важным становится вопрос о том, что делать с данными, которые являются общими для нескольких киосков данных, а также как разработать схему разграничения доступа пользователей к киоскам данных в рамках всей организации.
Главным достоинством создания ХД такой архитектуры является более глобальное представление данных. Взаимосвязанные киоски данных могут управляться в рамках того подразделения, в котором они создаются.
Реализация такой архитектуры не выдвигает высоких требований к программно-аппаратному обеспечению, и стоимость ее может быть невысокой. Однако время реализации будет больше по сравнению с независимыми киосками данных. Возрастают также сложность и стоимость процедур проектирования.
В заключение следует отметить, что развитие программно-вычислительных средств позволяет создавать так называемые виртуальные ХД, которые работают над OLTP-системами, ХД с многоуровневой архитектурой и так называемые встроенные ХД, которые встраиваются в существующую систему обработки данных организации.
Так же, как и для реализации любых типов информационных систем с базами данных, к ХД применимы следующие основные методологические подходы:
На выбор подхода к реализации ХД оказывают влияние следующие факторы:
Выбор методологического подхода к реализации ХД влияет на объем и тщательность проектирования.
Подход "сверху вниз". Подход "сверху вниз" требует детального планирования и проектирования ХД в рамках ИТ-проекта до начала выполнения проекта. Это связано с тем, что необходимо привлекать всех потенциальных пользователей ХД для выяснения их информационных потребностей в аналитической обработке данных, принимать решения об источниках данных, безопасности, структурах данных, качестве данных, стандартах данных. Все эти работы должны быть документированы и согласованы. При этом подходе модель ХД должна быть разработана до начала реализации.
Обычно такой подход практикуют при создании глобального ХД. Если киоски данных включаются в конфигурацию, то они могут быть построены позже.
Достоинством такого подхода является получение более согласованных определений данных и бизнес-правил организации в самом начале работы над созданием ХД. Стоимость начального планирования и проектирования может оказаться достаточно высокой. Для этого подхода характерны большие затраты времени, что откладывает начало реализации и задерживает возврат инвестиций. Подход "сверху вниз" хорошо применять в организациях с четко организованной информационно-вычислительной структурой, когда программно-аппаратная платформа определена и существуют слаженно работающие источники данных.
Подход "снизу вверх". При использовании подхода "снизу вверх" начинают с планирования и проектирования киосков данных подразделений без предварительной разработки глобальной информационно-вычислительной инфраструктуры организации. Это не означает, что такая глобальная инфраструктура не будет разработана позже. Такой подход является более приемлемым во многих случаях, поскольку он быстрее приводит к конечным результатам. У него есть и недостатки: данные могут дублироваться и быть несогласованными в разных киосках данных. Чтобы избежать этого, необходимо тщательное планирование и проектирование.
Подход "проектирование из середины". Подходы "снизу вверх" и "сверху вниз" могут комбинироваться в зависимости от поставленных перед руководителем проекта по созданию ХД целей. Подход "проектирование из середины" представляет собой комбинацию вышеперечисленных подходов, которые применяются как бы по спирали. Сначала создается ядро системы (подход "сверху вниз"), а затем оно поэтапно наращивается за счет добавления новой или дополнительной функциональности (подход "снизу вверх"). Таким образом, на каждом витке спирали может быть использован каждый из двух указанных выше подходов.
Существуют и другие комбинации. Выбор подхода к реализации ХД наряду с выбором архитектуры ХД определяет тактические решения в проектировании и управлении проектом создания системы складирования данных. К таким решениям относятся планирование реализацией и управление проектом.
В настоящем разделе дается краткий обзор решений основных производителей программного обеспечения для разработки ХД. При изложении материала используется, по возможности, следующая схема:
IBM. Решение компании IBM называется Data Warehouse Plus. Целью компании в области разработки и поддержки систем складирования данных является обеспечение пользователя интегрированным набором программных продуктов и сервисов в рамках единой архитектуры.
IBM предлагает встроенную поддержку трех типов архитектурных решений для ХД:
Несущая СУБД для ХД — семейство объектно-реляционных СУБД DB2. Язык манипулирования данными — SQL.
Преимущество решений IBM проявляется, когда и системы оперативной обработки данных, и ХД находятся на программном обеспечении IBM, т.е. предлагается так называемое замкнутое типовое решение.
С приобретением компании Informix Software IBM взяла под свое крыло ряд удачных решений этой компании в области систем складирования данных.
Oracle. Решения, предлагаемые компанией, преследуют две основные цели: предоставление пользователям широкого ассортимента программных продуктов самой компании и деятельность партнеров в рамках программы Warehouse Technology Initiative.
Компания Oracle не предлагает поддержку каких-либо встроенных архитектурных решений для ХД.
Несущая СУБД для ХД — семейство объектно-реляционных СУБД Oracle 11g/10g. Язык манипулирования данными — SQL. Начиная с версии 8i, диалект SQL существенно дополнен набором функций для аналитической обработки данных, вплоть до построения линейной регрессии.
Компания выпускает специальный CASE-инструментарий для проектирования ХД.
Конкурентные возможности Oracle определяются следующими факторами:
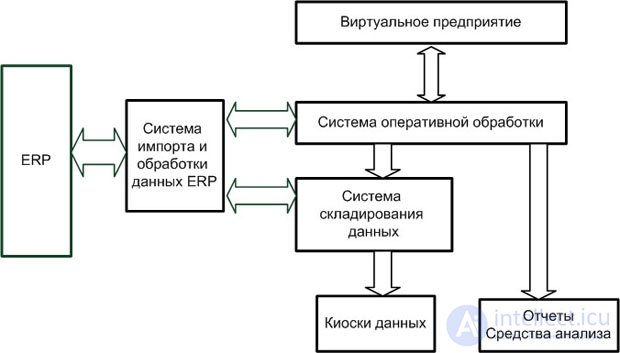
NCR. Об этом говорит сайт https://intellect.icu . Решение этой компании в области складирования данных ориентировано на организации, у которых имеются потребности в системах DSS (система поддержки и принятия решений) и системах OLAP. Предлагаемая архитектура называется Enterprise Information Factory (виртуальное предприятие).
Несущая СУБД для ХД — реляционная СУБД Teradata.
Конкурентным преимуществом решений компании является большой опыт применения СУБД Teradata и связанных с ней методов параллельной обработки данных.
SAS Institute. Компания считает себя поставщиком полного решения для организации ХД. Компания предлагает методологию Rapid Data Warehousing для быстрого создания и наполнения ХД. В основу этой методологии положено:
Конкурентным преимуществом компании является наличие у нее длинной линейки программных продуктов для статистического и сравнительного анализа данных, который интегрирован в ее методологию построения и использования ХД.
Sybase. Стратегия компании в области ХД основывается на разработанной архитектуре Warehouse WORKS.
Несущая СУБД для ХД — реляционная СУБД Sybase System 11, средство подключения к базам данных OmniCONNECT. Язык манипулирования данными — SQL и средства быстрой разработки приложений.
Компания выпускает специальный CASE-инструментарий для проектирования ХД.
Конкурентным преимуществом компании является наличие набора программных продуктов для обеспечения полного жизненного цикла разработки ХД.
Microsoft. Компания сравнительно недавно стала активно предлагать комплексные решения в области ХД. Целью корпорации Microsoft является создание инструментальной и технологической среды, которая позволила бы минимизировать затраты на создание ХД и сделала бы этот процесс доступным для массового пользователя. Акцент предлагаемых компанией решений в области складирования данных концентрируется на развитии инструментальных средств OLAP.
Корпорация предлагает спецификации среды Microsoft Data Warehousing Framework для создания и использования ХД. Открытость среды Microsoft Data Warehousing Framework обеспечила ее поддержку многими производителями программного обеспечения.
Цель Microsoft Data Warehousing Framework состоит в том, чтобы упростить разработку, внедрение и администрирование решений на основе ХД. Эта спецификация призвана обеспечить:
Несущая СУБД для ХД — реляционная СУБД MS SQL Server 2005/2008. Язык манипулирования данными — SQL со встроенными средствами обработки многомерных кубов.
Конкурентным преимуществом компании является наличие у нее набора программных продуктов для обеспечения разработки и поддержки ХД, в том числе для очистки данных, при невысокой цене на эти продукты. Ориентация продукции компании на средний и малый бизнес позволяет ей увеличить свои конкурентные преимущества.
Software AG. Деятельность компании в области ХД происходит в рамках программы Open Data Warehouse Initiative.
Несущая СУБД для ХД — сетевая СУБД ADABAS. Язык манипулирования данными — Natural 4GL.
У компании имеются собственные средства извлечения и анализа данных, а также программный продукт управления ХД SourcePoint.
Компания имеет сложившийся круг пользователей и долгое время не проявляла инициативы по переходу на распределенные архитектуры, основанные на компьютерах средней мощности. Компания обладает высоким потенциалом в области систем складирования данных и в последнее время компания наращивает свое участие в этом сегменте рынка.
Из предыдущих разделов настоящей лекции следует, что существуют несколько вариантов реализации ХД в рамках типовой архитектуры. Рассмотрим некоторые из них.
Существенные различия в программном обеспечении у различных производителей определяются следующими факторами: 1) используемая модель данных; 2) степень охвата жизненного цикла; 3) встроенная поддержка различных архитектур; 4) возможности языка обработки данных. Можно обратить внимание на следующие две основные тенденции.
С точки зрения применения программно-аппаратных платформ решения в области создания систем складирования данных можно условно разбить на три класса.
Пример простого масштабируемого решения можно предложить, основываясь на использовании Crystal Enterprise и Crystal Reports (фирма Business Objects) как инструментов конечного пользователя. Подробнее о возможностях Crystal Enterprise и Crystal Reports можно прочитать в литературе к курсу настоящих лекций.
ХД реализуется на СУБД Oracle, DB2, MS SQL Server или других, имеющих ODBC-интерфейс или интерфейс прямого доступа с Crystal Enterprise. Обычно применяется классическая архитектура ХД без киосков данных. Для этого решения большое значение имеет тщательное проектирование структуры ХД и запросов. Необходимо разработать и создать приложения для очистки данных (или воспользоваться имеющими у поставщиков средствами).
Преимущества
Недостатки
Замкнутое типовое решение можно предложить на основе использования замкнутой цепочки продуктов одной фирмы-поставщика, например Microsoft ( рис. 2.4), Oracle ( рис. 2.5), SAS или Sybase.

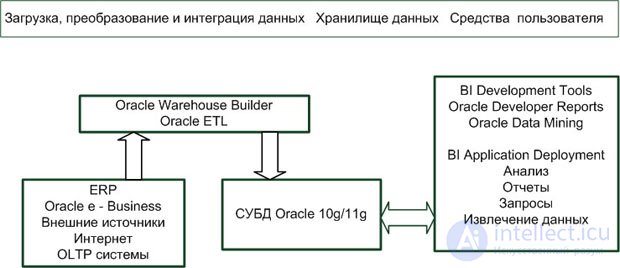
Преимущества
Недостатки
Концепция хранилищ данных находит применение во многих сферах бизнеса, науки и управления. Рассмотрим типовые решения для бизнеса. Такие типовые решения использования технологии складирования данных в бизнесе можно разделить на следующие основные группы.
Основные сферы применения технологии складирования данных приведены в табл. 2.1. Имеется тенденция расширения проникновения концепции в те сферы бизнеса, где необходимо выполнять, с одной стороны, сравнительный анализ, искать зависимости в данных, выявлять тренды в рядах динамики, а с другой – использовать системы складирования данных в связке с системами операционной обработки.
| № | Сфера деятельности | Комментарий |
|---|---|---|
| 1 | Сегментация рынка | CRM |
| 2 | Планирование продаж, прогнозирование и управление | CRM, SCM |
| 3 | Опека клиентов | CRM |
| 4 | Схемы лояльности | |
| 5 | Проектирование и разработка продуктов | MRP/ERP |
| 6 | Интеграция цепочки поставок | SCM, ERP/MRP, SCP, SCE, DRP, JIT |
| 7 | Инновации и новые возможности | |
| 8 | Новые возможности приложений с использованием Интернет/Интранет | eBusiness, TMP |
| 9 | Приложения, основанные на агентах программного обеспечения | |
| 10 | Приложения для извлечения знаний и кибер-организация | EIF, виртуальное предприятие |
| 11 | Распространение DW из области стратегического планирования в область бизнес операций | VDW |
| 12 | Приложения для вертикальных секторов индустрии | CRM, TMP |
| 13 | Готовые DW (off-the-shalf) | |
| 14 | Автоматизация принятия решений | DSS, EIS |
| 15 | Новые категории оперативных приложений, ориентированные на клиента | OLAP |
| 16 | Сбор и анализ экспериментальных данных в химии, физике, биологии | EDW |
| 17 | Хранение мультимедийной информации в DW | DL |
Сокращения, использованные в колонке "Комментарий" табл. 2.1 и не поясненные ранее в тексте, имеют следующие значения:
Рассмотрим несколько примеров применения технологии складирования данных в области создания аналитических подсистем информационного сопровождения бизнеса.
Оперативные системы CRM содержат следующие компоненты: центры обработки мобильных сообщений, данные по обслуживанию клиентов, данные из отдела продаж, данные о продажах через интернет-магазины, данные ERP систем, данные из ИСР (EIS) и других внешних источников. Эти системы выступают источниками данных для аналитических CRM. Типовая структура аналитического ХД CRM-системы приведена на рис. 2.6.
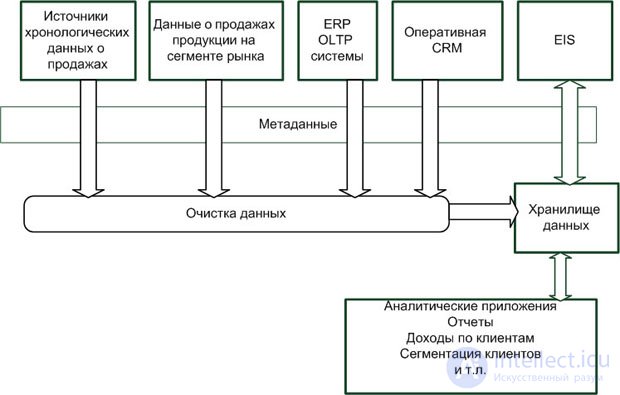
Внедрение такого решения позволяет оптимизировать цепочки работы с клиентами, провести персонализацию обслуживания клиентов, повысить доходы от продаж, а также позволяют разрабатывать стратегии расширения рынка за счет привлечения клиентов на основе индивидуального подхода.
Наиболее известное работающее решение в области аналитических CRM в телекоммуникациях имеет компания SAS Institute (US WEST Communications).
Аналитические SRM (Supply Relationship Management) системы занимаются управлением взаимоотношениями с поставщиками. Пример типовой архитектуры для ХД аналитических SRM систем приведен на рис. 2.7.
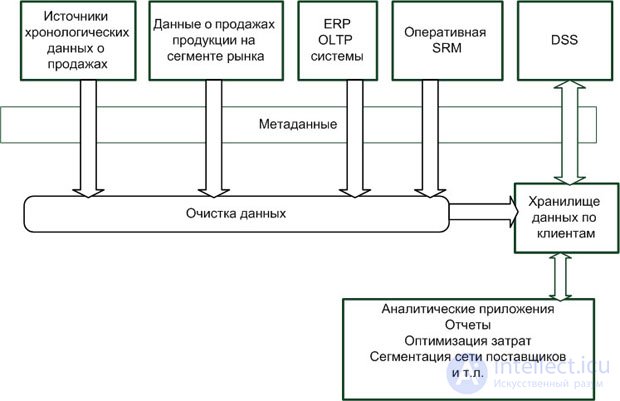
Конкурентные преимущества
Сопутствующие проблемы
Наиболее известное решение в области создания аналитических SRM-систем разработано компанией SAS Institute.
Аналитические SCM-системы, не встроенные в ERP-системы, представляют собой информационные системы для решения задач анализа и оптимизации в управлении жизненным циклом продукции. Пример типовой архитектуры для ХД аналитической SCM-системы приведен на рис. 2.8.
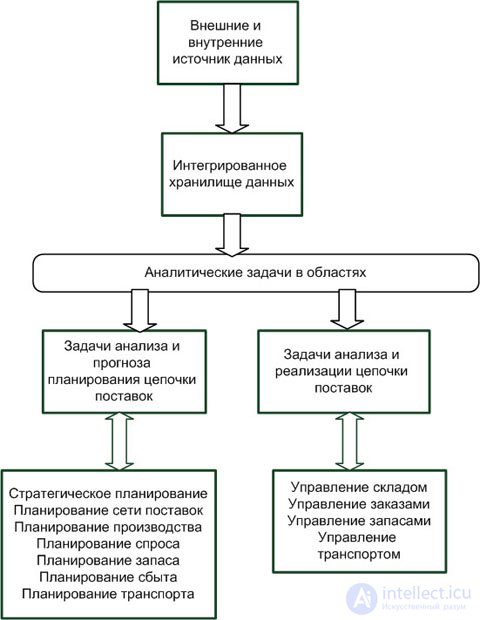
Достоинства использования SCM-решений
Сопутствующие проблемы
Конкурентные преимущества
По уровню использования SCM-решений телекоммуникации занимают второе место в мире (после нефти и газа). Перечень наиболее удачных решений в области оперативных SCM-систем приведен в табл. 2.2.
| Компания | Программные продукты |
|---|---|
| IBM | WebSphere (for e-Business), интеграция с ERP |
| SAP | Business Information WareHouse, SAP Advanced Planer & Optimizer Logistics Execution System |
| BAAN | IBAAN c совокупностью модулей в архитектуре ПО BAAN, в том числе и использованием хранилища данных |
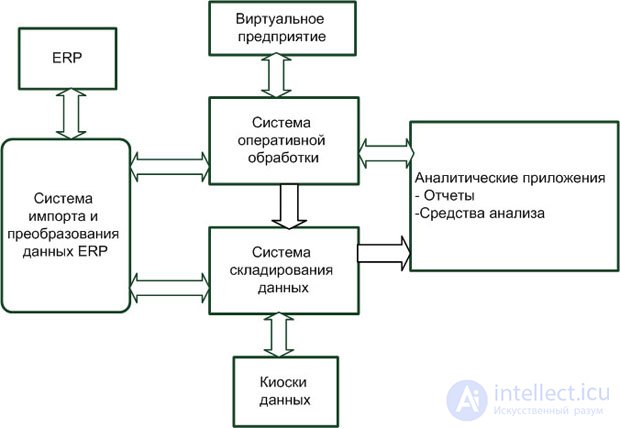
Одной из перспективных областей применения систем складирования данных является разработка ХД как составной части виртуального предприятия. В этом случае ХД рассматривается как часть интегрированной информационной структуры организации, которая имеет типовую архитектуру, показанную на рис. 2.9.
Очень перспективным в последнее время становится разработка ХД для цифровых (электронных) библиотек и мультимедиа. Современные СУБД имеют ряд встроенных возможностей для хранения и выборки мультимедийных данных (например СУБД Pilot). Однако большинство решений по созданию мультимедийных баз данных реализуется на реляционных СУБД, обладающих возможностью работы с BLOB-данными и имеющими поддержку очень больших БД. Типичными представителями таких СУБД являются СУБД Oracle (имеет специальные средства выборки визуальной информации — VIR и интернет-систему обработки файлов iFS), DB2 и Informix (теперь IBM).
Примерами мультимедийных ХД являются разрабатываемые во всем мире электронные хранилища музейных данных (образы картин и других экспонатов).
Обсудим особенности типового решения создания мультимедийных ХД на основе реляционных СУБД. Следует отметить следующие свойства медиаданных:
С точки зрения разработки хранилищ мультимедийных данных следует отметить одно важное обстоятельство: измерения, в большинстве практических случаев, выражаются через простые типы данных, что значительно облегчает разработку хранилищ таких данных.
В этом отношении хранилище мультимедийных данных имеет типовую архитектуру, в которой медиаданные быстро извлекаются и визуализируются. Задачи сравнительного анализа медиаданных зависят от предметной ориентации ХД и требуют обычно специально разработанных процедур.
Преимущество
Сопутствующие проблемы
В настоящее время в кругу бизнес-пользователей информационных технологий обсуждается предложенная Биллом Инмоном концепция так называемой корпоративной информационной фабрики (Corporate Information Factory, CIF) как одной из основополагающих вычислительных архитектур для производства информационных продуктов предприятия. Для любого предприятия реализацию такой концепции можно рассматривать как важную перспективную задачу, решение которой не только позволит повысить качество управления взаимоотношениями с внешними организациями (налоговыми и финансовыми государственными структурами) и партнерами, но и значительно увеличить производительность его подразделений, поставляющих информацию, необходимую для принятия стратегических решений.
Рассмотрим более подробно концепцию CIF.
Производству данных — свою технологию
Корпоративная информационная фабрика — это логическая архитектура программно-аппаратного решения по производству, складированию, управлению и доставке данных для поддержки принятия стратегических и тактических решений в масштабе организации. Концепция CIF, предложенная классиком в области теории хранилищ данных Биллом Инмоном в серии его работ, подразумевала системно организованное взаимодействие репозиториев оперативных данных (Operational Data Store), центрального ХД, витрин данных и системы интеллектуального анализа данных (Data Mining) за счет создания технологических цепочек переработки и доставки данных.
В абстрактной форме процесс производства информации в CIF был представлен в аналогии с производством некоторого продукта. В соответствии с этим были выделены основные стадии производства информации (новых данных): получение исходных данных (сырья), их преобразование (производство отдельных деталей), складирование данных, создание информационных продуктов (из деталей готовой продукции) и доставка данных их потребителям (распределение конечной продукции).
Основная идея, положенная в основу концепции CIF, состоит в выделении элементов информационной архитектуры на основе их функционального назначения и регламентирования технологических процедур обработки данных.
Краеугольным камнем правильно спроектированной CIF являются, безусловно, метаданные. Задача этого слоя — описать в рамках единой терминологической базы (метаданные бизнес-пользователя) всю совокупность объектов управления средой CIF (метаданные администрирования). Только подход "от метаданных" позволяет из гетерогенного потока входной информации получить однородное описание среды и предметной области, что дает возможность одинаково легко обращаться к измерениям, кубам, отчетам и бизнес-объектам на основе произвольных выборок. Таким образом, обеспечивается высокое качество циркулирующей в CIF информации.
В основе CIF лежит модель функционального разделения процессов производства новых данных (информационных продуктов) и доставки информационных продуктов их потребителям, а также управления этими процессами.
Производители информационного продукта собирают данные из доступных источников (чаще всего из оперативных систем ввода и обработки данных), преобразуют и интегрируют их, размещая в системе складирования данных в унифицированном регламентированном формате. Потребители информационных продуктов извлекают необходимые тематические выборки из системы складирования данных (через специализированные предварительно настроенные интерфейсы — витрины данных) и затем используют их в процессе принятия решений.
Логическая структура CIF включает в себя несколько типовых архитектурных элементов (табл. 2.3).
| Элемент | Характеристика |
|---|---|
| Системы, доставшиеся "по наследству" (Legacy Systems) | Поддерживают бизнес-функции, которые были созданы в организации ранее. В таких системах обычно компоненты, обеспечивающие формирование отчетов и ввод и передачу данных, реализуются в рамках единого программного блока, что затрудняет решение задач по интеграции и преобразованию данных в соответствии с новыми требованиями бизнеса |
| Приложения оперативного управления организацией (OLTP) | Обеспечивают быструю обработку данных в рамках бизнес-направлений деятельности организации. Как правило, такие системы приобретаются у компании-разработчика, которая осуществляет их техническую поддержку |
| Оперативные склады данных (Operational Data Store - ODS) | Этот элемент наделяется свойствами как оперативных, так и аналитических систем. Основное его назначение - обеспечить осуществление анализа информации практически сразу после ее обновления в оперативных системах |
| Компоненты преобразования данных (ETL-tools, Staging Area, Near-line Storage) | Служат для перегрузки данных из одних программных компонентов в другие (с промежуточной очисткой и согласованием данных, получаемых из различных источников) |
| Корпоративное хранилище данных (Enterprise Data Warehouse) | Здесь накапливается детальная информация, необходимая для выполнения анализа. Данные перегружаются в корпоративное хранилище из оперативных элементов - унаследованных систем, автоматизированных банковских систем или оперативных складов данных. Как правило, обновление информации в EDW происходит с большой задержкой. Для разрешения этой проблемы используются ODS-элементы |
| Витрины данных (Data Marts) | Предназначены для хранения аналитической информации уровня подразделения или направления бизнеса |
| Приложения поддержки принятия решений (DSS) и приложения анализа данных (DM) | DSS, примером функционала которых могут быть системы анализа клиентской базы банка, обеспечивают поддержку принятия решений. Разнообразный статистический анализ выполняется в DM |
| Инфраструктура сетевых коммуникаций | Обеспечивает публикацию данных в сети Интранет (Интернет), а также обработку результатов ввода информации пользователями |
На предприятии производственные и финансовые потоки тесно взаимосвязаны с потоками информационными, которые отражают их динамические показатели и текущее состояние. Кроме того, такие информационные потоки являются источником данных для анализа при определении трендов изменений и их количественных характеристик.
Описанная выше в общих чертах схема превращения данных в информационные продукты и составляет суть концепции CIF на любом предприятии ( рис. 2.10)
Складирование данных — это технология, с помощью которой можно оперативно собрать данные и на их основе решать разнообразные задачи по финансовому планированию, бюджетированию, риск-менеджменту, анализу взаимоотношений с партнерами, маркетинговому анализу и т.д. Однако самое главное преимущество отлаженной архитектуры CIF в другом: она позволяет адаптировать вычислительную среду как под четко определенные информационные потоки небольшого предприятия, так и под сложные схемы консолидации, которые характерны для предприятий с развитой филиальной структурой и входящих в состав холдингов и отраслевых объединений предприятий.
Рассмотрим подробнее, как "фабрика управленческих данных" функционирует на предприятии.
Первоначальное наполнение корпоративного ХД и постоянное поддержание его в актуальном состоянии — это отнюдь не тривиальные задачи. Особые требования здесь предъявляются к качеству информации, кроме того, высока степень риска — ошибочные решения на основе неверных исходных посылок могут обернуться серьезными потерями.
На предприятиях основными источниками данных являются ERP-системы. Они представляют собой семейство оперативных приложений, обеспечивающих обработку производственных и финансовых данных, включая выполнение бухгалтерских проводок, логистических операций, генерацию текущей оперативной отчетности. Модули ERP ориентированы на те информационные продукты, которые они сопровождают или поддерживают. Разумеется, ERP не предназначены для обработки информации в историческом аспекте и не имеют развитого инструментария для агрегации и систематизации данных предприятия. Из-за строгой предметной направленности у подсистем ERP, как правило, слабо развиты взаимосвязи на уровне данных: обычно у них информационный обмен осуществляется небольшими объемами.
Таким образом, на первом шаге построения CIF-системы источники данных накапливают информацию в масштабе предприятия в "сыром" виде: она не подготовлена для анализа и компиляции аналитической отчетности.
Организация процесса интеграции является еще одним фактором успеха в создании CIF: информация извлекается из разнородной вычислительной среды ERP, преобразуется с целью повышения ее качества и складируется. Все это делается для того, чтобы системы поддержки и принятия решений могли в дальнейшем ее активно использовать.
Для наполнения корпоративного ХД в нем обычно предусматриваются инструментальные средства:
ХД — это предметно-ориентированная, интегрированная, неизменяемая и поддерживающая хронологию коллекция данных, используемая для поддержки принятия решений. С позиций CIF хранилище является отправной точкой при преобразовании данных в информационные продукты (аналитические отчеты и пр.). Оно всегда предоставляет своим потребителям проверенные и согласованные данные по всей организации в целом, независимо от источника их происхождения.
Процесс управления данными предусматривает комплекс процедур, отвечающих за прохождение информации в CIF. Он включает в себя архивацию и восстановление данных, секционирование, управление перемещением данных в системе, агрегацию и т.д.
В конечном итоге, как мы помним, информация должна попасть к потребителю в заданном виде, чтобы послужить базисом для принятия взвешенных управленческих решений. Логично на выходе CIF применять:
В качестве отличительных характеристик подхода Билла Инмона к архитектуре ХД можно назвать следующие.
В данной архитектуре ХД с архитектурой шины данных, предложенной Ральфом Кимболлом, первичные данные преобразуются в необходимые структуры на стадии подготовки данных. При этом обязательно принимаются во внимание требования к скорости обработки информации и качеству данных. Подготовка данных начинается со скоординированного извлечения их из источников. Ряд операций совершается централизованно, например, поддержание и хранение общих справочных данных, другие действия могут быть распределенными.
ХД с архитектурой шины данных изначально ориентированы на использование многомерной модели данных (см. следующие лекции). Поэтому, как правило, данные в его структуре денормализованы, чтобы оптимизировать выполнение запросов. Запросы в процессе выполнения обращаются к все более низкому уровню детализации без дополнительного перепрограммирования со стороны пользователей или разработчиков приложения.
В отличие от корпоративной информационной фабрики, в ХД с архитектурой шины данных чаще используются связанные киоски данных, которые разрабатываются для обслуживания бизнес-процессов (бизнес-показателей или бизнес-событий), а не направлений бизнеса. Например, данные о заказах, которые должны быть доступны для общекорпоративного использования, вносятся в ХД только один раз, в отличие от CIF, в котором их пришлось бы трижды копировать в витрины данных отделов маркетинга, продаж и финансов. После того, как в ХД появляется информация об основных бизнес-процессах, консолидированные киоски данных могут выдавать их перекрестные характеристики. Матрица шины данных корпоративного ХД с архитектурой шины выявляет и усиливает связи между показателями бизнес-процессов (фактами) и описательными атрибутами (измерениями).
ХД с архитектурой шины данных состоит из набора взаимосвязанных киосков данных, которые созданы для обслуживания бизнес-процессов организации (См. рис. 2.11).

Суммируя все вышесказанное, можно отметить типичные характеристики ХД с архитектурой шины данных.
Отметим, что и корпоративная информационная фабрика, и ХД с архитектурой шины данных имеют своей целью создание корпоративного ХД. Соответственно, единство конечного объекта означает общность требований, которым должен удовлетворять любой подход для достижения искомого конечного результата, а это, в свою очередь, указывает на то, что и в самой архитектуре должны быть общие черты.
Обе эти архитектуры отличаются в основном способами представления данных. В CIF, они, как правило, нормализованы, а в ХД с архитектурой шины данных — нет.
Для любой организации, особенно многофилиальной, наличие согласованной управленческой информации, необходимой для четкого понимания того, как функционирует бизнес, является одной из актуальных задач.
Обычный подход к улучшению информированности о бизнес-операциях — проведение стандартизации "сверху вниз" как структуры отчетности, так и модели данных. Однако с практической точки зрения стандартизация бизнес-структур оказывается для большинства организаций малоэффективной — требуется слишком много средств и времени.
В качестве одного из подходов для решения указанной проблемы может бытъ использована архитектура федеративного ХД ( рис. 2.12). В этой архитектуре на основе иерархии связанных ХД можно обмениваться данными, бизнес-моделями и структурами отчетности, благодаря чему возможно, с одной стороны, осуществлять общий контроль и предусмотреть определенную степень стандартизации, а с другой — позволить региональным отделениям сохранить автономность и учесть местную специфику.
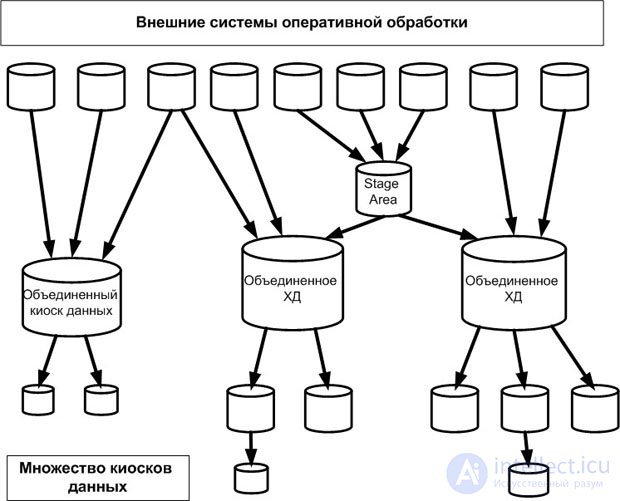
Система объединенных ХД характеризуется совместным использованием общих информационных точек, что устраняет, таким образом, избыточность и гарантирует достоверность информации по всей организации ( рис. 2.12). Федеративное ХД состоит из ряда экземпляров ХД, которые функционируют на полуавтономной основе и, как правило, организационно или географически разнесены, однако могут рассматриваться и управляться как одно большое ХД. Применение такой архитектуры снижает риск неудачи при глобальном развертывании системы, поскольку каждое локальное ХД меньше по масштабу, отвечает местным требованиям бизнеса и может управляться сотрудниками регионального подразделения.
Каждый из экземпляров федеративного ХД хранит копию базовой бизнес-модели и общие основные данные (common master dat), причем каждое ХД более высокого уровня содержит итоговые транзакционные данные более низкого уровня. Общие основные данные — например, схема организационной структуры компании — отправляются "вниз", т.е. из корпоративного (глобального) ХД, а суммарные данные о транзакциях отправляются "верх", т.е. из локального ХД. Таким образом, "федерация" ХД может предоставить местным отделениям необходимую гибкость, а также обеспечить общий контроль и согласованность; при этом каждое ХД функционирует независимо от всех других остальных.
Для федеративных ХД характерны общая семантика и бизнес-правила, стандартизованный набор процессов извлечения из (о существовании бизнес-правил как таковых было сказано строкой выше) бизнес-правил, децентрализованные ресурсы и управление, параллельная разработка.
При этом следует учитывать, что важна необходимость в координировании работ, требуется согласованность среди различных отделов по вопросам архитектуры, бизнес-правил и семантики, сложная технологическая информационно-вычислительная среда.
Хранилища данных — это сравнительно новое технологическое решение, которое стало широко использоваться только в начале 90-х гг. ХХ в., после того, как Билл Инмон (Bill Inmon), ныне получивший всеобщее признание как «отец концепции хранилища данных», опубликовал свою первую книгу по этой теме (W.H. Inmon, Building the Data Warehouse, QED/Wiley, 1991). Хотя отдельные элементы этой концепции и их техническое воплощение существовали и ранее (по сути дела, с 70-х гг. прошлого века), только к концу 80-х гг. была в полной мере осознана необходимость интеграции корпоративной информации и надлежащего управления ею, а также появились технические возможности для создания соответствующих систем, первоначально названных хранилищами информации, а затем, с выходом книги Инмона, получивших свое нынешнее наименование «хранилища данных».
Существуют два основных архитектурных направления — нормализованные хранилища данных и хранилища с измерениями.
В нормализованных хранилищах, данные находятся в предметно ориентированных таблицах третьей нормальной формы. Нормализованные хранилища характеризуются как простые в создании и управлении, недостатки нормализованных хранилищ — большое количество таблиц как следствие нормализации, из-за чего для получения какой-либо информации нужно делать выборку из многих таблиц одновременно, что приводит к ухудшению производительности системы. Для решения этой проблемы используются денормализованные таблицы — витрины данных, на основе которых уже выводятся отчетные формы. При громадных объемах данных могут использовать несколько уровней «витрин»/«хранилищ».
Хранилища с измерениями используют схему «звезда» или схему «снежинка». При этом в центре «звезды» находятся данные (таблица фактов), а измерения образуют лучи звезды. Различные таблицы фактов совместно используют таблицы измерений, что значительно облегчает операции объединения данных из нескольких предметных таблиц фактов (пример — факты продаж и поставок товара). Таблицы данных и соответствующие измерения образуют архитектуру «шина». Измерения часто создаются в третьей нормальной форме, в том числе, для протоколирования изменения в измерениях. Основным достоинством хранилищ с измерениями является простота и понятность для разработчиков и пользователей, также, благодаря более эффективному хранению данных и формализованным измерениям, облегчается и ускоряется доступ к данным, особенно при сложных анализах. Основным недостатком является более сложные процедуры подготовки и загрузки данных, а также управление и изменение измерений данных.При достаточно большом объеме данных схемы «звезда» и «снежинка» также дают снижение производительности при соединениях с измерениями.
На сегодняшний день существует два основных подхода к архитектуре хранилищ данных.
Это так называемая корпоративная информационная фабрика (Corporate Information Factory, сокр. CIF) Билла Инмона (рис. 1.7) и хранилище данных с архитектурой шины (Data Warehouse Bus, сокр. BUS) Ральфа Кимболла (Ralph Kimball) (рис. 11.8).
Рассмотрим каждый из них подробнее.
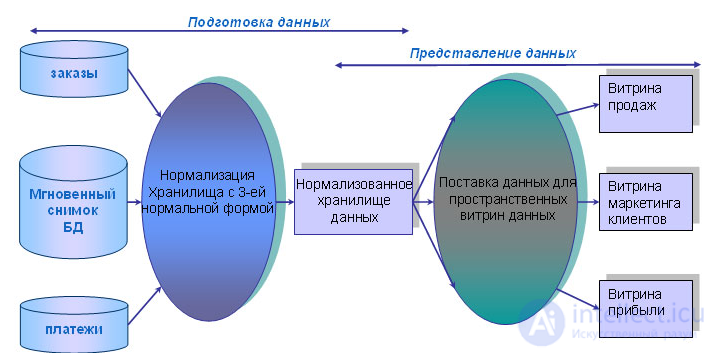
Рис. 11.7. Архитектура корпоративной информационной фабрики
Работа хранилища, показанного на рис. 11.7, начинается со скоординированного извлечения данных из источников. После этого загружается реляционная база данных с третьей нормальной формой, содержащая атомарные данные. Получившееся нормализованное хранилище используется для того, чтобы наполнить информацией дополнительные репозитории презентационных данных, т. е. данных, подготовленных для анализа. Эти репозитории, в частности, включают специализированные хранилища для изучения и «добычи» данных (Data Mining), а также витрины данных. Отличительными особенностями подхода Билла Инмона к архитектуре хранилищ данных являются:
На рис. 11.8 приведена схема хранилища данных с архитектурой шины.

Рис. 11.8. Хранилище с архитектурой шины
В отличие от подхода Билла Инмона, пространственные модели строятся для обслуживания бизнес-процессов (которые, в свою очередь, связаны с бизнес-показателями или бизнес-событиями), а не бизнес-отделов. Например, данные о заказах, которые должны быть доступны для общекорпоративного использования, вносятся в пространственное хранилище данных только один раз, в отличие от CIF-подхода, в котором их пришлось бы трижды копировать в витрины данных отделов маркетинга, продаж и финансов. После того, как в хранилище появляется информация об основных бизнес-процессах, консолидированные пространственные модели могут выдавать их перекрестные характеристики. Матрица корпоративного хранилища данных с архитектурой шины выявляет и усиливает связи между показателями бизнес-процессов (фактами) и описательными атрибутами (измерениями).
Суммируя все вышесказанное, можно отметить типичные черты подхода Ральфа Кимболла.
Преимущества и недостатки каждого из подходов напрямую вытекают из их архитектурных решений. Считается, что пространственная организация с архитектурой «звезда» облегчает доступ к данным и требует меньше времени на выполнение запросов, а также упрощает работу с атомарными данными. С другой стороны, сторонники подхода Билла Инмона критикуют эту схему за отсутствие необходимой гибкости и уязвимость структуры, полагая, что в пространственно организованные атомарные данные труднее вносить необходимые изменения.
Реляционная схема организации атомарных данных замедляет доступ к данным и требует больше времени для выполнения запросов в силу разной организации атомарных и суммарных данных. Но с другой стороны, эта схема предоставляет широкие возможности для манипулирования атомарными данными и изменения их формата и способа представления по мере необходимости.

Билл Инмон
Билл Инмон рекомендует создать хранилище данных, которое следует нисходящему подходу. В соответствии с философией Inmon, это начинается с создания большого централизованного хранилища корпоративных данных, где все доступные данные из транзакционных систем объединяются в предметно-ориентированный, интегрированный, изменяющийся во времени и энергонезависимый сбор данных, который поддерживает принятие решений. затем строятся витрины данных для аналитических нужд отделов.

Ральф Кимбалл
В отличие от подхода Билла Инмона, Ральф Кимбалл рекомендует создать хранилище данных, которое следует принципу «снизу вверх». В философии Кимбалла, он сначала начинается с критически важных витрин данных, которые служат аналитическим потребностям отделов. Затем он объединяет эти витрины данных для обеспечения согласованности данных через так называемую информационную шину. Кимбалл использует размерную модель для удовлетворения потребностей отделов в различных областях на предприятии.
Вот наиболее важные критерии выбора между подходом Кимбалла и Инмона.
| Характеристики | Кимбалл | Инмон |
|---|---|---|
| Требования к поддержке бизнес-решений | тактический | стратегическое |
| Требования к интеграции данных | Индивидуальные бизнес-требования | Корпоративная интеграция |
| Структура данных | KPI, показатели эффективности бизнеса, системы показателей ... | Данные, которые отвечают множественным и различным потребностям в информации, и неметрические данные. |
| Постоянство данных в исходных системах | Исходные системы довольно стабильны | Исходные системы имеют высокую скорость изменения |
| Набор умений | Небольшая команда универсалов | Большая команда специалистов |
| Ограничение времени | Срочные нужды для первого хранилища данных | Больше времени отводится на удовлетворение потребностей бизнеса. |
| Стоимость строительства | Низкая стоимость запуска | Высокие начальные затраты |
Основой аналитической обработки данных на базе хранилищ данных является технология OLAP (online analytical processing, аналитическая обработка в реальном времени) — технология обработки информации, включающая составление и динамическую публикацию отчетов и документов. Данная технология используется аналитиками для быстрой обработки сложных запросов к базе данных. Причина использования OLAP для обработки запросов — это скорость. Реляционные БД хранят сущности в отдельных таблицах, которые обычно хорошо нормализованы. Эта структура удобна для операционных (оперативных) БД (системы OLTP), но сложные многотабличные запросы в ней выполняются относительно медленно. Более хорошей моделью для запросов, а не для изменения, является пространственная БД
Вместе с базовой концепцией существуют три типа OLAP:
MOLAP — это классическая форма OLAP, так что ее часто называют просто OLAP. Она использует суммирующую БД, специальный вариант процессора пространственных БД и создает требуемую пространственную схему данных с сохранением как базовых данных, так и агрегатов. ROLAP работает напрямую с реляционным хранилищем, факты и таблицы с измерениями хранятся в реляционных таблицах, и для хранения агрегатов создаются дополнительные реляционные таблицы. HOLAP использует реляционные таблицы для хранения базовых данных и многомерные таблицы для агрегатов. Особым случаем ROLAP является ROLAP реального времени (Real-time ROLAP — R-ROLAP). В отличие от ROLAP в R-ROLAP для хранения агрегатов не создаются дополнительные реляционные таблицы, а агрегаты рассчитываются в момент запроса. При этом многомерный запрос к OLAP-системе автоматически преобразуется в SQL-запрос к реляционным данным.
В настоящий момент существует множество продуктов, которые предоставляют возможности организации хранилищ данных о проведения на них OLAP -анализа.
Одной из проблем обработки больших объемов информации становится технология сжатия данных.
Фракталы, эти красивые образы динамических систем, ранее использовались в машинной графике в основном для построения изображений неба, листьев, гор, травы. Красивое и, что важнее, достоверно имитирующее природный объект изображение могло быть задано всего несколькими коэффициентами. Неудивительно, что идея использовать фракталы при сжатии возникала и раньше, но считалось практически невозможным построить соответствующий алгоритм, который подбирал бы коэффициенты за приемлемое время. Итак, в 1991 г. такой алгоритм был найден. Фрактальный архиватор позволяет, например, при распаковке произвольно менять разрешение (размеры) изображения без появления эффекта зернистости. Более того, он распаковывает гораздо быстрее, чем ближайший конкурент JPEG, и не только статическую графику, но и видео.
Фактически фрактальная компрессия — это поиск самоподобных областей в изображении и определение для них параметров аффинных преобразований.
Для фрактального алгоритма компрессии, как и для других алгоритмов сжатия с потерями, очень важны механизмы, с помощью которых можно будет регулировать степень сжатия и степень потерь. К настоящему времени разработан достаточно большой набор таких методов. Во-первых, можно ограничить количество преобразований, заведомо обеспечив степень сжатия не ниже фиксированной величины. Во-вторых, можно потребовать, чтобы в ситуации, когда разница между обрабатываемым фрагментом и наилучшим его приближением выше определенного порогового значения, этот фрагмент дробился обязательно, и для него обязательно заводится технология преобразования. В-третьих, можно запретить дробить фрагменты размером меньше, допустим, четырех точек. Изменяя пороговые значения и приоритет этих условий, можно очень гибко управлять коэффициентом компрессии изображения: от побитного соответствия, до любой степени сжатия.
Компонентами типовой архитектуры ХД являются:
Отметим, что в последнее время возрастает практический интерес к использованию ХД при формировании информационной инфраструктуры организаций. Преимущества, которые получает организация от внедрения хранилищ данных, следующие.
Представленные результаты и исследования подтверждают, что применение искусственного интеллекта в области технологические решения хранилищ данных имеет потенциал для революции в различных связанных с данной темой сферах. Надеюсь, что теперь ты понял что такое технологические решения хранилищ данных, архитектура хранилищ данных, управление складами данных, фрактальные методы в архивации и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL
Ответы на вопросы для самопроверки пишите в комментариях, мы проверим, или же задавайте свой вопрос по данной теме.
Комментарии
Оставить комментарий
Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL
Термины: Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL