Лекция
параллельное программирование существует уже около полувека и продолжает оставаться актуальной областью в программировании. Несмотря на свою долгую историю, это поле всегда остается в фокусе внимания, и это может подсказывать, что у него есть некоторые сложности. Итак, перед тем как приступать к написанию параллельных программ, важно критически разобраться в основных концепциях и принципах, которые необходимо освоить. Это подобно тому, как мы учимся основам перед тем, как начать что-то создавать. Параллельное программирование, или разработка многозадачных и многопоточных приложений, может столкнуться с различными проблемами и сложностями. Вот некоторые из основных проблем, которые могут возникнуть при параллельном программировании:
Состояние гонки (Race Conditions): Это одна из самых распространенных проблем параллельного программирования. Состояние гонки возникает, когда два или более потока (или процесса) пытаются одновременно доступиться к общему ресурсу, и результат операции зависит от того, какой поток сначала получит доступ. Это может привести к непредсказуемым и неконтролируемым результатам.
Взаимная блокировка (Deadlock): Взаимная блокировка возникает, когда два или более потока заблокированы и ждут друг друга, чтобы освободить ресурсы, необходимые для продолжения выполнения. Это может вызвать "зависание" приложения, когда ни один из потоков не может завершить свою работу.
Голодание (Starvation): Голодание может произойти, когда один или несколько потоков получают доступ к ресурсам более часто или быстрее, чем другие, что может привести к некорректной работе или долгому ожиданию других потоков.
Перегрузка (Concurrency Overhead): Использование параллелизма может привести к увеличению накладных расходов на управление потоками и синхронизацию, что может ухудшить производительность в некоторых случаях.
Сложность отладки: Поиск и устранение ошибок в параллельных программах может быть сложным и затратным процессом из-за непредсказуемого поведения и многозадачности.
Неопределенность (Indeterminism): В параллельных программах результаты выполнения могут изменяться от запуска к запуску из-за непредсказуемых факторов, таких как распределение ресурсов между потоками и процессами.
Управление ресурсами: Корректное управление ресурсами (например, памятью) в параллельных приложениях может быть сложной задачей из-за конкуренции за доступ к ресурсам.
Синхронизация и ожидание: Использование синхронизации для управления доступом к ресурсам может привести к длительным задержкам, если потоки вынуждены ждать друг друга.
Скорость выполнения (Race for Speed): В некоторых случаях, добавление большего количества потоков не обязательно приводит к увеличению производительности из-за наложения накладных расходов на управление потоками и конкуренцию за ресурсы.
В некоторых случаях линейный порядок исполнения операторов программы необходим из-за особенностей системы или алгоритма, а в других случаях этот порядок можно изменить для более эффективной параллельной обработки. Рассмотрим классические примеры ситуаций, когда вычислительные алгоритмы хорошо распараллеливаются:
Разделение данных (Data Parallelism): В этом случае данные разбиваются на небольшие части, и каждый поток или ядро процессора работает с отдельной частью данных независимо. Примерами являются операции на массивах данных, такие как суммирование, умножение и фильтрация.
Задачи с независимыми подзадачами (Task Parallelism): В этом случае алгоритм состоит из набора независимых подзадач, которые могут быть выполнены параллельно. Классическим примером является параллельное выполнение различных вычислений на множестве независимых объектов или элементов данных.
Модель акторов (Actor Model): Это абстрактная модель параллельного вычисления, в которой акторы (независимые исполнительные единицы) обмениваются сообщениями. Эта модель подходит для построения параллельных систем с асинхронной коммуникацией между компонентами.
Задачи с разделяемым состоянием (Shared-State Concurrency): В этом случае несколько потоков могут иметь доступ к общим данным, но синхронизация должна быть правильно организована. Примерами могут служить многозадачные приложения с общей базой данных.
Рекурсивное разделение (Recursive Decomposition): Некоторые алгоритмы, такие как алгоритм быстрого умножения матриц (Strassen's algorithm) или алгоритм сортировки слиянием (Merge Sort), могут быть эффективно распараллелены с помощью рекурсивного разделения задачи на более мелкие подзадачи.
Однако стоит отметить, что не все алгоритмы можно просто распараллелить. Некоторые задачи имеют естественные зависимости между операциями, и их параллельная обработка может потребовать сложных алгоритмов синхронизации или даже быть невозможной.
Выбор подходящего способа параллельной обработки зависит от конкретной задачи и требует анализа алгоритма, структуры данных и доступных ресурсов.
Пример 15.1.1. Умножение матриц - это случай, на котором достаточно широкие массы программистов и заказчиков вычислительных программ осознали потенциальную выгодность распараллеливания. Если разбить матрицу произведения k*m x l*n на подматрицы размера m x n, то для вычисления каждой такой подматрицы достаточно иметь m строк первого сомножителя и n столбцов второго. Разделив вычисления по независимым процессорам, мы можем ценой некоторого дублирования исходных данных значительно быстрее получить результат.
Аналогично распараллеливается задача решения системы линейных уравнений.
Пример 15.1.2. Пусть задача представляется как совокупность нескольких взаимодействующих автоматов (таким образом, в принципеона укладывается в рамки автоматного программирования, но единая система структурируется на подсистемы, и большинство действий работают внутри подсистем). Тогда у нас возникает естественный параллелизм.
Таковы многие игровые задачи, в которых задействовано несколько персонажей, таково же и большинство задач синтаксического разбора.
На этих двух примерах видно, что существуют существенные различия. В первом примере задачи не зависят от того, как будет проводиться вычисление. Здесь мы используем свойства конкретного алгоритма, который может быть эффективно разделен на части для параллельной обработки. Этот алгоритм может иметь множество возможных связей данных, которые можно реализовать в структуре данных вычислительных систем, включая последовательную обработку.
Во втором примере параллелизм необходим из-за природы задачи, так как система разбивается на подсистемы. Важно отметить, что теоретические решения в данном случае часто оказываются практически неосуществимыми. Современные параллельные системы обычно имеют фиксированное и, как правило, небольшое число процессоров. Если же процессоров много, то они могут быть жестко связаны в структуру. Поэтому задачи, которые естественным образом подразумевают параллелизм, редко могут быть эффективно выполнены в таких системах. Значительно проще адаптировать задачи, которые не являются параллельными по своей природе, но могут быть разделены на параллельные части, так как структуру выполнения алгоритма можно подстроить под требования конкретной системы.
В жизни каждый из Вас встречался с простейшим видом параллелизма: длительный и относительно автономный процесс печати запускается, как правило, параллельно с выполнением других программ. Случай, когда Вы одновременно запустили несколько программ, как правило, настоящим параллелизмом не является (это рассматривается чуть ниже).
Результатом команды считается результат участника, пришедшего последним.
(из правил соревнований по военно-прикладным видам спорта)
- Доктор, а чем я болен?
- Не волнуйтесь, больной, вскрытие покажет.
(русский анекдот)
Один из видов параллелизма, который возникает при умножении матриц, кажется подходящим для структурного программирования, но на самом деле не является настоящим параллелизмом. В структурном программировании данные организованы в сеть, и программа движется по этой сети. Эта сеть имеет частичный порядок, и если можно выделить несколько независимых подсетей, проходящих через некоторые части исходной сети от начала до конца, то эти подсети можно выполнить на отдельных вычислительных устройствах. В критические моменты времени эти устройства могут взаимодействовать между собой. Обычно есть несколько способов разделения сети данных, и поэтому один и тот же алгоритм можно выполнить на параллельных системах с различной архитектурой.
Пример 15.2.1. Пусть сеть данных имеет следующий вид (рис. 15.1)

Тогда ее естественно исполнять на одно-, двух- либо трехпроцессорной машине. В случае многопроцессорной машины в начале и на заключительном этапе вычисление идет последовательно, а три ветви распределяются между процессорами. В частности, если две боковые ветви занимают меньше времени счета, чем главная, можно на двухпроцессорной машине распределить их обе на один и тот же процессор.
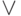 - параллелизм, когда для успешного завершения параллельного блока достаточно, чтобы к успеху пришел один из запущенных процессов.
- параллелизм, когда для успешного завершения параллельного блока достаточно, чтобы к успеху пришел один из запущенных процессов.Рассмотрим теперь, каковы же общие условия применимости - параллелизма. Частный пример про льва показывает, что в принципеможно было бы представить "процедуру" поиска беглеца в виде следующего условного предложения:
if
Лев в квартале1 -> Искать в квартале 1,
Лев в квартале2 -> Искать в квартале 2,
Лев в квартале3 -> Искать в квартале 3,
Лев в квартале4 -> Искать в квартале 4
fi
Но беда в том, что для выяснения истинности охраны нужно выполнить охраняемую команду, т.е. найти льва. Таким образом, данный условный оператор может служить лишь призраком.
Далее, имеется еще одно неявное условие, которое иллюстрируется вторым эпиграфом. Если исполнение охраняемой команды с неподходящей охраной может навредить (ресурсы-то оно займет, вред - это нечто более существенное, наподобие лечения согласно неверному диагнозу), то мы скорее всего будем вынуждены производить вскрытие программы после внезапной и мучительной ее кончины.
Таким образом, - параллелизм является подпоркой для эффективной реализации призрачного условного оператора, удовлетворяющего двум требованиям:
Тогда можно запустить различные варианты параллельно на разных процессорах и посмотреть, какой первый придет к удаче.
В качестве примера задачи, естественно допускающей > - параллелизм и не являющейся задачей поиска, можно рассмотреть часто возникающую в дифференциальных играх (в частности, в игре "перехватчик и носитель") ситуацию, когда имеется точка выбора. После данной точки предлагается несколько несовместимых способов, а чтобы определить, какая из стратегий приведет к поимке цели, нужно просчитать поведение системы при рассматриваемой стратегии до конца. Тогда, если впереди точка выбора и нужно заранее принять решение, целесообразно запустить сразу несколько процессов моделирования.
Третий вид параллелизма на самом деле параллелизмом не является, и, пожалуй, шире всего распространен в практике программирования. Это квазипараллелизм. Вы встречаетесь с ним в программах, когда порождаете подпроцесс командой типа thread. В этом случае несколько процессов исполняются как один процесс, в котором перемешаны шаги подпроцессов, так что у программиста создается впечатление, что процессы исполняются параллельно. Квазипараллелизм может с внешней стороны выглядеть как любой из двух рассмотренных ранее видов параллелизма. В первом приближении квазипараллелизм дает лишь чистый проигрыш, но фактически он позволяет занять естественно образующиеся в одном из процессов промежутки ожидания (например, ввода или вывода данных) работой других процессов. Именно так работает Ваш плейер, пока Вы ломаете голову над ошибками в своей программе.
Пример 15.2.2. Классическим примером эффективного использования - параллелизма на плохо связанной между собой распределенной системе является массированная хакерская атака какого-либо пароля. Тысячи хакеров, разделив между собою поле поиска, запускают программы перебора на своих машинах. Кто-нибудь да найдет, а тот факт, что другие могут еще несколько дней (поскольку по ночам хакеры обычно "работают", а днем спят) гонять программу перебора, уже ни на что не влияет: все равно выигрыш получен колоссальный.
До сих пор мы рассматривали идеальный случай, когда процессы независимы между собой и вопрос об их взаимодействии возникает лишь в момент их завершения. Но на практике так конечно же бывает крайне редко. Процессы практически всегда взаимосвязаны, и поэтому нужно рассмотреть вопрос об организации связей между ними.
Первая связь - общие данные. Рассмотрим самый простой случай, когда у процессов есть общее поле памяти, в которое они записывают обновленные данные и читают их в случае необходимости. Даже в этом случае возникают сложности. Если один из процессов начал обновлять данные в поле, а другой как раз в это время их читает, то может случиться так, что он получит мешанину из старых и обновленных данных (такой случай в распределенных системах и в базах данных рассматривается как нарушение целостности данных1 ).
Конечно, проще всего установить монопольное использование общего ресурса: программа, обратившаяся к этому ресурсу, устанавливает флаг, и пока флаг поднят, никто другой обратиться к нему не может. Но представьте себе, например, коллективную работу над пухлым техническим заданием. Мне нужно, скажем, внести изменения в главу 3, а я не могу сделать этого, поскольку уже пару часов некто корпеет над главой 13, которая практически от главы 3 не зависит. В этом случае прибегают к корпоративным системам поддержки распределенной работы (в качестве положительного примера устойчиво работающей системы можно привести Lotus Works, правда, с 2002 г. автор с ней не работал, так что улучшения, сделанные с тех пор, могли повлечь потерю надежности). В них решаются тонкие задачи поддержания целостности данных при поступлении изменений из множества источников, при сбоях серверов, сети и т.п. Все это делается таким образом, чтобы работа одного из сотрудников практически не мешала работе других (а если уж мешает, значит, оба пытаются залезть в одно и то же место, но для этих случаев предусмотрена система развязки конфликтов).
Критический интервал, как часто бывает в программировании, понятие, существующее в двух ипостасях: аппаратной и логической.Логический критический интервал определяется (вернее, в принципе должен определяться) потребностями работы системы программ и может быть задан естественными программными средствами. Но беда в том, что для аппаратуры даже столь элементарное действие, как проверка флага занятости ресурса и установка его нового значения, может быть делимым, и в промежутке между Вашим чтением и записью кто-то другой уже запишет, что ресурс занят, а дальше... Поэтому есть аппаратные критические интервалы, которые для обычного пользователя упрятаны внутри команд синхронизации. Эти интервалы система старается минимизировать, поскольку в такое времяприостановка работы критического процесса и передача управления другому крайне нежелательны. Другое дело логический критический интервал. Тут можно приостановить процесс и запустить другой, лишь бы он не обращался к закрытому ресурсу.
Когда общий ресурс один, все более или менее ясно. Но вот когда их много, и могут потребоваться сразу несколько из них...
Пример 15.3.1. Пять безмолвных философов сидят вокруг круглого стола, перед каждым философом стоит тарелка спагетти. Вилки лежат на столе между каждой парой ближайших философов.Каждый философ может либо есть, либо размышлять. Прием пищи не ограничен количеством оставшихся спагетти — подразумевается бесконечный запас. Тем не менее, философ может есть только тогда, когда держит две вилки — взятую справа и слева .
Каждый философ может взять ближайшую вилку (если она доступна) или положить — если он уже держит ее. Взятие каждой вилки и возвращение ее на стол являются раздельными действиями, которые должны выполняться одно за другим.
Вопрос задачи заключается в том, чтобы разработать модель поведения (параллельный алгоритм), при котором ни один из философов не будет голодать, то есть будет вечно чередовать прием пищи и размышления.

Если все пять философов одновременно сядут за стол и возьмут по вилке в правую руку, то они так за этим столом и умрут с голоду.
Этот пример - классическая задача параллельного программирования. Все теоретические дисциплины управления параллельными процессами проверяются на ней.
Задача сформулирована таким образом, чтобы иллюстрировать проблему избежания взаимной блокировки (англ. deadlock) — состояния системы, при котором прогресс невозможен.
Например, можно посоветовать каждому философу выполнять следующий алгоритм:
Это решение задачи некорректно: оно позволяет системе достичь состояния взаимной блокировки, когда каждый философ взял вилку слева и ждет, когда вилка справа освободится.
Проблема ресурсного голодания (англ. resource starvation) может возникать независимо от взаимной блокировки, если один из философов не может завладеть левой и правой вилкой из-за проблем синхронизации. Например, может быть предложено правило, согласно которому философы должны класть вилку обратно на стол после пятиминутного ожидания доступности другой вилки, и ждать еще пять минут перед следующей попыткой завладеть вилками. Эта схема устраняет возможность блокировки (так как система всегда может перейти в другое состояние), но по-прежнему существует возможность «зацикливания» системы (англ. livelock), при котором состояние системы меняется, но она не совершает никакой полезной работы. Например, если все пять философов появятся в столовой одновременно и каждый возьмет левую вилку в одно и то же время, то философы будут ждать пять минут в надежде завладеть правой вилкой, потом положат левую вилку и будут ждать еще пять минут прежде, чем попытаться завладеть вилками снова.
Взаимное исключение (англ. mutual exclusion) является основной идеей «Проблемы обедающих философов». Эта проблема представляет собой общий, абстрактный сценарий, позволяющий объяснить проблемы этого типа. Ошибки философов наглядно демонстрируют те трудности, которые возникают в реальном программировании, когда нескольким программам требуется исключительный доступ к совместно используемым ресурсам. Эти вопросы изучаются в области параллельных вычислений.
Изначальная цель Дейкстры при формулировании «проблемы обедающих философов» заключалась в демонстрации возможных проблем при работе с внешними устройствами компьютера, например, ленточными накопителями. Тем не менее, область применения данной задачи простирается гораздо дальше и сложности, рассматриваемые в задаче, чаще возникают, когда несколько процессов пытаются получить доступ к набору данных, который обновляется.
Системы, которые должны иметь дело с большим количеством параллельных процессов (например, ядра операционных систем), используют тысячи блокировок и точек синхронизации. Это требует строгого соблюдения методик и протоколов, если необходимо избегать взаимных блокировок, голодания и повреждения данных.
Второй вид связи параллельных процессов - критические точки. Когда процесс достиг критической точки, это означает, что он может двигаться дальше лишь в том случае, если другие процессы также достигнут соответствующей критической точки. Например, для вычисления следующей итерации необходимо убедиться в том, что предыдущая итерация уже всеми закончена. Для следующего поиска необходимо узнать, что хотя бы один из параллельно работающих процессов уже нашел предыдущие данные.
Есть один важный частный случай &-параллелизма, когда критические точки и критические интервалы не вызывают проблем. Это -конвейерный параллелизм. При конвейерном параллелизме основную часть времени процессы работают независимо. Затем работа всех частных процессов приостанавливается, происходит обмен данными и просмотр происшедших событий. Такая организация работы аналогична заводскому конвейеру: пока конвейер стоит, рабочие выполняют свои операции; затем конвейер движется, передавая результаты операций следующему исполнителю.
Это было неформальное введение в теоретические тонкости, возникающие при взаимодействии процессов (все равно, действительно параллельных или квазипараллельных). А на практике часто важнее другие детали.
Хорошее распараллеливание невозможно без подробного анализа программы. В самом деле, если один из процессоров несет 99% вычислительной нагрузки, то мы на распараллеливании лишь прогадаем, поскольку добавятся накладные расходы на синхронизацию процессов. Так что первая проблема практического распараллеливания - предсказание сложности вычислений различных блоков программы. Только если удается равномерно распределить вычисления по процессорам, причем такая равномерность должна сохраняться внутри каждого интервала между взаимодействиями процессов, распараллеливание дает выигрыш. В параллельном программированииавтор наблюдал примеры, когда вроде бы безобидное и абсолютно корректное с точки зрения обычного программирования улучшениеодного из блоков приводило к ухудшению работы всей программы. Так что оптимизация не всегда монотонна по отношению к разбиению на подсистемы.
Теперь рассмотрим один из методов квазипараллельного программирования, зачастую хорошо подходящий для моделирования естественного параллелизма автоматного программирования и потенциального параллелизма событийного программирования. Этомоделирование в системе с логическим дискретным временем.
Концепция времени является одной из важнейших во многих областях. Более того, в известном американском афоризме Time is moneyабсолютная ценность низводится до уровня условной. Время мы не можем получить ни от кого, не можем сохранить, можем лишь тратить.
При компьютерном моделировании поведения объектов целесообразно выделить два аспекта:
Если время не моделируется, а берется из реального мира, говорят о системах реального времени . Если же время является частью виртуального мира системы, то это - логическое время. Выделяя его прикладные аспекты, часто говорят о логическом времени как обусловном, или модельном, времени.
Рассмотрим тот простейший (но исключительно важный) случай времени, когда время может быть представлено как линейно упорядоченная совокупность шагов, а все процессы, протекающие между шагами, можно считать неделимыми. Тогда на временной оси у нас есть лишь дискретная совокупность точек, в которых нужно поддерживать целостность системы и каждого из процессов. Такая дисциплина возможна и для систем реального времени, если допустима некоторая задержка ответа на событие (такой случай называетсямягким реальным временем ). Тогда можно дождаться естественного завершения шага нашего процесса и лишь в промежутке между шагами просматривать события.
Если время является не только дискретным, но и логическим, то говорят о системе с дискретными событиями. Эта ситуация хорошо подходит для применения и моделирования как конвейерного, так и - параллелизма.
Пример 15.3.2. Рассмотрим модельную задачу. Пусть нужно найти кратчайший путь в нагруженном ориентированном графе, где каждаядуга оснащена числом, интерпретируемым как ее длина. Это традиционно интерпретируется как определение кратчайшего пути между городами A и B, связанными сетью однонаправленных дорог.
Покажем, что решение задачи можно построить как систему взаимодействующих процессов с дискретным временем. Это - хороший метод структурирования задачи и отделения деталей от существенных черт: сначала мы строим абстрактное представление, а затем конкретизируем его, например укладывая, по сути своей, параллельный алгоритм в рамки последовательной программы3. Идея этого подхода восходит к У.-И. Далу и Ч. Хоору, которые использовали данную задачу для демонстрации возможностей системы с дискретными событиями, предоставляемой языками SIMULA 60 и SIMULA 67, совпадавшими по модели времени и структуре управления процессами.
Базовой концепцией в данной задаче естественно является - параллелизм. Определение кратчайшего расстояния можно представить как соревнование действующих агентов "разбредающихся" по разным дорогам. Сразу же разграничиваются два класса алгоритмов: прямые, когда общий процесс начинается с A, и обратные, для которых стартовым городом назначается B. Для показа принципиальных моментов достаточно рассмотреть по одному прямому и обратному алгоритму.
Видно, что алгоритм завершает работу, когда найден путь из A в B либо когда все агенты оказываются ликвидированы.
Как и обычно, более жесткие условия на окончательную программу влекут за собой во многих отношениях более мягкие требования к прототипу (нужно расширить возможности его перестройки в разные варианты окончательной программы), но при этом желательно максимально возможное повышение уровня понятий прототипа. Если в конце концов программа будет реализована квазипараллельно, не нужно обращать внимание на то, сколько агентов могут действовать одновременно. В частности, в случае заведомого наличия пути из A в B можно не проверять запретность либо ослабить ее до случая, когда предок данного агента посещал данный город, и, следовательно, он оказался на запомненном пути. В этом случае не потребуется запоминание глобальной, а точнее, общей для всех агентов информации о графе дорог и городов.
Рис. 15.2 иллюстрирует работу всех трех алгоритмов: прямого (a), прямого с пометками (b) и обратного с пометками-рекомендациями (c). Надписи на дугах-дорогах обозначают агентов, верхние индексы на них - порядок порождения агентов. В косых скобках записаны локально хранимые сведения о посещаемых городах. Зачеркнутые надписи указывают на уничтожение агента в связи с использованием сведений о посещениях городов.
Как прямой, так и обратный алгоритмы работоспособны, если обеспечить одновременную работу сразу всех процессов агентов. Если вычислитель дает возможность многопроцессорной обработки, причем с потенциально неограниченным5 числом процессоров, то это условие выполнено автоматически.
Возникает вопрос о средствах эмуляции дискретных событий. Имеются пакеты работы с дискретными событиями, но еще в 60-е гг. было показано, что мышление в терминах времени на самом деле требует собственного языка. Классическим примером здесь до сих пор является язык SIMULA 67. Он в явном виде провозглашает имитацию параллелизма и, следовательно, дает человеку возможность мыслить в терминах действующих агентов, что представляется более гибким и естественным способом выражения многих алгоритмов. Систему с дискретными событиями можно рассматривать в качестве общего метода преодоления противоречия между принципиальным параллелизмом и реальной последовательностью вычислений.
Состояние называется:
Можно считать, что с помощью управляющего списка процессам задаются относительные приоритеты.
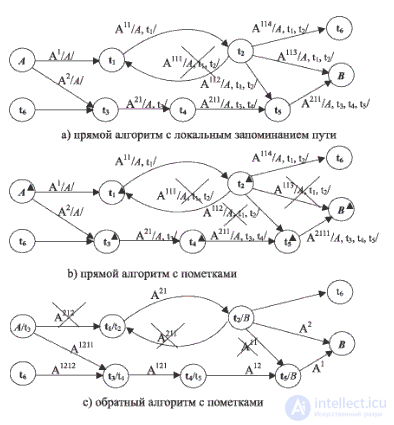
На рис. 15.3 изображено начало последовательности состояний управляющего списка, которая получается при выполнении алгоритма с данными, представленными на рис. 15.2с. В верхней части рисунка изображена модель времени: на горизонтальной оси отмечены моменты, когда состояние агентов меняется (  - функция времени перемещения между городами; a, b, c и d - моменты для дальнейшего пояснения). В нижней части рисунка показана последовательность изменений управляющего списка (его состояния выделены прямоугольными блоками, в которых для наглядности вертикальные стрелки обозначают связи процессов, назначенных на одно и то же время, а горизонтальные стрелки - упорядоченность процессов по модельному времени ).
- функция времени перемещения между городами; a, b, c и d - моменты для дальнейшего пояснения). В нижней части рисунка показана последовательность изменений управляющего списка (его состояния выделены прямоугольными блоками, в которых для наглядности вертикальные стрелки обозначают связи процессов, назначенных на одно и то же время, а горизонтальные стрелки - упорядоченность процессов по модельному времени ).
Даже зацикливание некоторых агентов не помешает выполнению алгоритма, если только вместимость управляющего списка будет достаточной.
В качестве хорошего изложения современного состояния дел в технике практического параллельного программирования можно рекомендовать систему MPI и Open MP которые включают в себя средства квазипараллельного исполнения параллельных программ, отличные от системы с дискретными событиями. Эти средства мы не описываем, поскольку для реальных программ они нужны лишь как метод отладки параллельных программ на машине с недостаточной конфигурацией (причем метод, не вызывающий особых восторгов).
Для решения этих проблем разработчики используют различные техники и инструменты, такие как мьютексы, семафоры, мониторы и атомарные операции. Они также стремятся проектировать приложения с учетом возможности параллелизма и избегать гонок и блокировок.
Ответы на вопросы для самопроверки пишите в комментариях, мы проверим, или же задавайте свой вопрос по данной теме.
Комментарии
Оставить комментарий
Стили и методы программирования
Термины: Стили и методы программирования