Лекция
Сразу хочу сказать, что здесь никакой воды про код хаффмана, и только нужная информация. Для того чтобы лучше понимать что такое код хаффмана, код шеннона-фано, алгоритм хаффмана , настоятельно рекомендую прочитать все из категории Теория информации и кодирования.
алгоритм хаффмана — алгоритм оптимального префиксного кодирования алфавита с минимальной избыточностью. Был разработан в 1952 году аспирантом Массачусетского технологического института Дэвидом Хаффманом при написании им курсовой работы. В настоящее время используется во многих программах сжатия данных. некоторые ошибочно называют - алгоритмом Хофмана или Алгоритм Гаффмана .
В отличие от алгоритма Шеннона — Фано, алгоритм Хаффмана остается всегда оптимальным и для вторичных алфавитов m2 с более чем двумя символами.
Этот метод кодирования состоит из двух основных этапов:
Рассмотрим код Хаффмана: строится по алгоритму кодового дерева, построение графа начинается с висячих вершин. Их число соответствует количеству сообщений. Вес каждой вершины — это есть вероятность появления соответствующего сообщения. И перед началом работы висячие вершины упорядочиваются по мере увеличения высот. Шаг 1: определеяется число поддеревьев графа. Если оно меньше 2, то дерево построено, если нет — шаг 2. Шаг 2: выбирается 2 вершины с минимальными весами и сравниваются. Получаается новая вершина и 2 ребра. Новая вершина имеет вес = сумме исходных вершин. Левое ребро получается 1, правое — 0. Возврат к шагу 1. В результате построения дерева получается корень всегда = 1. Чтобы получить кодовую комбинацию i-го сообщения необходимо от корня дерева спустится по ребрам к i-ой висячей вершине, выписав при этом метки ребер этого пути.
ПРИМЕР: 8 сообщений, X={x1,…x8}, B={0,1}, P1=0,19, P2=0,16, P3=0,16, P4=0,15, P5=0,12, P6=0,11, P7=0,09, P8=0,02.
Пусть обратно (чем чаще сообщение, тем короче код), x1:01, x2:111, x3:110, x4:101, x5:100, x6:001, x7:0001, x8:0000. Самые мелкие вершины сращиваем
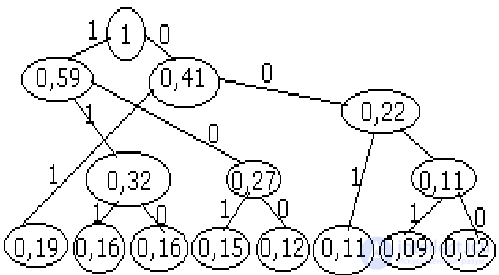
Оценим степень эффективности полученного кода. Для этого (**)
|
xi |
кодовая комбинация |
ni |
ni*Pi |
-Pi*log2 Pi |
|
X1 |
11 |
2 |
0,38 |
-0,19*log20,19 |
|
X2 |
011 |
3 |
0,48 |
-0,16*log20,16 |
|
X3 |
010 |
3 |
0,48 |
-0,16*log20,16 |
|
X4 |
001 |
3 |
0,45 |
-0,15*log20,15 |
|
X5 |
000 |
3 |
0,36 |
-0,12*log20,12 |
|
X6 |
101 |
3 |
0,33 |
-0,11*log20,11 |
|
X7 |
1001 |
4 |
0,36 |
-0,09*log20,09 |
|
X8 |
1000 |
4 |
0,08 |
-0,02*log20,02 |
Посчитаем после nср = 2,92 бит, H(x)=2,85 бит.
H(x)/log2m = nmin = 2,85 бит, Kи=(nср — nmin)/nср = 0,024, 2,4% - избыточность кода Хаффмана для этого примера.
Один из первых алгоритмов эффективного кодирования информации был предложен Д. А. Хаффманом в 1952 году. Идея алгоритма состоит в следующем: зная вероятности появления символов в сообщении, можно описать процедуру построения кодов переменной длины, состоящих из целого количества битов. Символам с большей вероятностью ставятся в соответствие более короткие коды. Коды Хаффмана обладают свойством префиксности (то есть ни одно кодовое слово не является префиксом другого), что позволяет однозначно их декодировать.
Классический алгоритм Хаффмана на входе получает таблицу частот встречаемости символов в сообщении. Далее на основании этой таблицы строится дерево кодирования Хаффмана (Н-дерево).
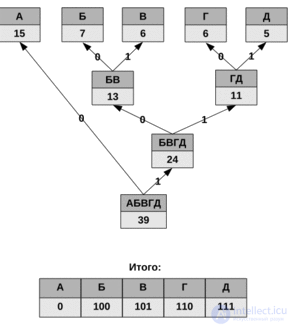
Допустим, у нас есть следующая таблица частот:
| Символ | А | Б | В | Г | Д |
|---|---|---|---|---|---|
| Частота | 15 | 7 | 6 | 6 | 5 |
Этот процесс можно представить как построение дерева, корень которого — символ с суммой вероятностей объединенных символов, получившийся при объединении символов из последнего шага, его n0 потомков — символы из предыдущего шага и т. д.
Чтобы определить код для каждого из символов, входящих в сообщение, мы должны пройти путь от листа дерева, соответствующего текущему символу, до его корня, накапливая биты при перемещении по ветвям дерева (первая ветвь в пути соответствует младшему биту). Полученная таким образом последовательность битов является кодом данного символа, записанным в обратном порядке.
Для данной таблицы символов коды Хаффмана будут выглядеть следующим образом.
| Символ | А | Б | В | Г | Д |
|---|---|---|---|---|---|
| Код | 0 | 100 | 101 | 110 | 111 |
Поскольку ни один из полученных кодов не является префиксом другого, они могут быть однозначно декодированы при чтении их из потока. Кроме того, наиболее частый символ сообщения А закодирован наименьшим количеством бит, а наиболее редкий символ Д — наибольшим.
При этом общая длина сообщения, состоящего из приведенных в таблице символов, составит 87 бит (в среднем 2,2308 бита на символ). Об этом говорит сайт https://intellect.icu . При использовании равномерного кодирования общая длина сообщения составила бы 117 бит (ровно 3 бита на символ). Заметим, что энтропия источника, независимым образом порождающего символы с указанными частотами, составляет ~2,1858 бита на символ, то есть избыточность построенного для такого источника кода Хаффмана, понимаемая как отличие среднего числа бит на символ от энтропии, составляет менее 0,05 бит на символ.
Классический алгоритм Хаффмана имеет ряд существенных недостатков. Во-первых, для восстановления содержимого сжатого сообщения декодер должен знать таблицу частот, которой пользовался кодер. Следовательно, длина сжатого сообщения увеличивается на длину таблицы частот, которая должна посылаться впереди данных, что может свести на нет все усилия по сжатию сообщения. Кроме того, необходимость наличия полной частотной статистики перед началом собственно кодирования требует двух проходов по сообщению: одного для построения модели сообщения (таблицы частот и Н-дерева), другого для, собственно, кодирования. Во-вторых, избыточность кодирования обращается в ноль лишь в тех случаях, когда вероятности кодируемых символов являются обратными степенями числа 2. В-третьих, для источника с энтропией, не превышающей 1 (например, для двоичного источника), непосредственное применение кода Хаффмана бессмысленно.
Адаптивное сжатие позволяет не передавать модель сообщения вместе с ним самим и ограничиться одним проходом по сообщению как при кодировании, так и при декодировании.
В создании алгоритма адаптивного кодирования Хаффмана наибольшие сложности возникают при разработке процедуры обновления модели очередным символом. Теоретически можно было бы просто вставить внутрь этой процедуры полное построение дерева кодирования Хаффмана, однако, такой алгоритм сжатия имел бы неприемлемо низкое быстродействие, так как построение Н-дерева — это слишком большая работа, и производить ее при обработке каждого символа неразумно. К счастью, существует способ модифицировать уже существующее Н-дерево так, чтобы отобразить обработку нового символа. Наиболее известными алгоритмами перестроения являются алгоритм Фоллера-Галлагера-Кнута (FGK) и алгоритм Виттера.
Все алгоритмы перестроения дерева при считывании очередного символа, включают в себя две операции:
Первая — увеличение веса узлов дерева. Вначале увеличиваем вес листа, соответствующего считанному символу, на единицу. Затем увеличиваем вес родителя, чтобы привести его в соответствие с новыми значениями веса потомков. Этот процесс продолжается до тех пор, пока мы не доберемся до корня дерева. Среднее число операций увеличения веса равно среднему количеству битов, необходимых для того, чтобы закодировать символ.
Вторая операция — перестановка узлов дерева — требуется тогда, когда увеличение веса узла приводит к нарушению свойства упорядоченности, то есть тогда, когда увеличенный вес узла стал больше, чем вес следующего по порядку узла. Если и дальше продолжать обрабатывать увеличение веса, двигаясь к корню дерева, то дерево перестанет быть деревом Хаффмана.
Чтобы сохранить упорядоченность дерева кодирования, алгоритм работает следующим образом. Пусть новый увеличенный вес узла равен W+1. Тогда начинаем двигаться по списку в сторону увеличения веса, пока не найдем последний узел с весом W. Переставим текущий и найденный узлы между собой в списке, восстанавливая таким образом порядок в дереве (при этом родители каждого из узлов тоже изменятся). На этом операция перестановки заканчивается.
После перестановки операция увеличения веса узлов продолжается дальше. Следующий узел, вес которого будет увеличен алгоритмом, — это новый родитель узла, увеличение веса которого вызвало перестановку.
Существует разновидность алгоритма Хаффмана, использующая контекст. В данном случае размер контекста равен единице (биграммный — два символа, триграммный — три и так далее). Это метод построения префиксного кода для моделей высших порядков, уже не источника без памяти. Он использует результат (предыдущей операции) операции над предыдущей буквой совместно с текущей буквой. Строится на основе цепи Маркова с глубиной зависимости  .
.
Алгоритм
строятся остальные кодовые деревья, с помощью которых будут кодироваться все остальные символы (кроме первого).Декодирование выполняется аналогично: из стартовой кодовой схемы получаем первый контекст, а затем переходим к соответствующему кодовому дереву. Более того, декодеру необходима таблица распределения вероятностей.
Пример
Допустим, сообщение, которое надо закодировать «abcabcabc». Нам заранее известна таблица частот символов (на основе других данных, например, статистических данных по словарю).
| a | b | c | Сумма | |
|---|---|---|---|---|
| a |  |
 |
|
 |
| b |  |
|
|
|
| c | |
|
|
 |
Имеем стартовую схему:  . Сортируем по убыванию:
. Сортируем по убыванию:  и строим кодовое дерево Хаффмана.
и строим кодовое дерево Хаффмана.
Для контекста «a» имеем:
 ,
, ,
, .
.Для контекста «b» имеем:
 ,
, ,
, .
.Для контекста «c» имеем:
 ,
, ,
, .
.Примечание: здесь p(x, y) не равно p(y, x).
Строим кодовые деревья для каждого контекста. Выполняем кодирование и имеем закодированное сообщение: (00, 10, 01, 11, 10, 01, 11, 10, 01).
В процессе работы алгоритма сжатия вес узлов в дереве кодирования Хаффмана неуклонно растет. Первая проблема возникает тогда, когда вес корня дерева начинает превосходить вместимость ячейки, в которой он хранится. Как правило, это 16-битовое значение и, следовательно, не может быть больше, чем 65535. Вторая проблема, заслуживающая еще большего внимания, может возникнуть значительно раньше, когда размер самого длинного кода Хаффмана превосходит вместимость ячейки, которая используется для того, чтобы передать его в выходной поток. Декодеру все равно, какой длины код он декодирует, поскольку он движется сверху вниз по дереву кодирования, выбирая из входного потока по одному биту. Кодер же должен начинать от листа дерева и двигаться вверх к корню, собирая биты, которые нужно передать. Обычно это происходит с переменной типа «целое», и, когда длина кода Хаффмана превосходит размер типа «целое» в битах, наступает переполнение.
Можно доказать, что максимальную длину код Хаффмана для сообщений с одним и тем же входным алфавитом будет иметь, если частоты символов образует последовательность Фибоначчи. Сообщение с частотами символов, равными числам Фибоначчи до Fib (18), — это отличный способ протестировать работу программы сжатия по Хаффману.
Принимая во внимание сказанное выше, алгоритм обновления дерева Хаффмана должен быть изменен следующим образом: при увеличении веса нужно проверять его на достижение допустимого максимума. Если мы достигли максимума, то необходимо «масштабировать» вес, обычно разделив вес листьев на целое число, например, 2, а потом пересчитав вес всех остальных узлов.
Однако при делении веса пополам возникает проблема, связанная с тем, что после выполнения этой операции дерево может изменить свою форму. Объясняется это тем, что при делении целых чисел отбрасывается дробная часть.
Правильно организованное дерево Хаффмана после масштабирования может иметь форму, значительно отличающуюся от исходной. Это происходит потому, что масштабирование приводит к потере точности статистики. Но со сбором новой статистики последствия этих «ошибок» практически сходят на нет. Масштабирование веса — довольно дорогостоящая операция, так как она приводит к необходимости заново строить все дерево кодирования. Но, так как необходимость в ней возникает относительно редко, то с этим можно смириться.
Масштабирование веса узлов дерева через определенные интервалы дает неожиданный результат. Несмотря на то, что при масштабировании происходит потеря точности статистики, тесты показывают, что оно приводит к лучшим показателям сжатия, чем если бы масштабирование откладывалось. Это можно объяснить тем, что текущие символы сжимаемого потока больше «похожи» на своих близких предшественников, чем на тех, которые встречались намного раньше. Масштабирование приводит к уменьшению влияния «давних» символов на статистику и к увеличению влияния на нее «недавних» символов. Это очень сложно измерить количественно, но, в принципе, масштабирование оказывает положительное влияние на степень сжатия информации. Эксперименты с масштабированием в различных точках процесса сжатия показывают, что степень сжатия сильно зависит от момента масштабирования веса, но не существует правила выбора оптимального момента масштабирования для программы, ориентированной на сжатие любых типов информации.
Алгоритм Хаффмана является важным инструментом сжатия данных и нашел широкое применение во многих областях, где необходимо эффективно использовать ресурсы хранения и передачи данных.
Алгоритм Хаффмана имеет широкое применение в сжатии данных, особенно в текстовых файлах. Он позволяет эффективно уменьшить размер данных, используя префиксные коды для кодирования символов. Вот некоторые области, где применяется алгоритм Хаффмана:
Сжатие данных: Алгоритм Хаффмана используется для сжатия различных типов данных, включая текстовые файлы, изображения, аудио и видео. Он позволяет уменьшить размер файлов без потери информации.
Компрессия текста: Алгоритм Хаффмана применяется для сжатия текстовых данных, таких как документы, электронная почта и веб-страницы. Он заменяет более часто встречающиеся символы короткими кодами, что позволяет снизить общий объем текстовой информации.
Сетевая передача данных: Алгоритм Хаффмана используется для сжатия данных, которые передаются по сети, например, при передаче файлов или потокового видео. Сжатие данных позволяет уменьшить время передачи и использование пропускной способности сети.
Хранение данных: Алгоритм Хаффмана применяется для сжатия данных, которые хранятся на устройствах хранения, таких как жесткие диски, флэш-накопители и облачные хранилища. Сжатие данных позволяет экономить пространство на диске и увеличивает доступную емкость хранилища.
Мультимедиа: Алгоритм Хаффмана используется в кодировании звука и изображений, например, в алгоритмах сжатия звука MP3 и сжатия изображений JPEG. Он позволяет удалить ненужную информацию из аудио и изображений, сохраняя при этом качество воспроизведения.
Архивация файлов: Алгоритм Хаффмана применяется в программных архиваторах, таких как ZIP и GZIP, для сжатия и архивации файлов и папок. Он позволяет объединять несколько файлов в один архив и сжимать их для экономии места на диске или при передаче по сети.
В 2013 году была предложена модификация алгоритма Хаффмана, позволяющая кодировать символы дробным количеством бит — ANS . На базе данной модификации реализованы алгоритмы сжатия Zstandard (Zstd, Facebook, 2015—2016) и LZFSE[fr] (Apple, OS X 10.11, iOS 9, 2016)
1) вся последовательность символов упорядочивается по убыванию значения их вероятности. 2) последовательность разбивается на 2 по возможности равновероятные группы,
3) первой группе присваивается символ “0”, второй — “1”.
4) каждая получившаяся группа развивается по возможности равновероятные и т.д. пока деление на группы возможно.
Пример: 5 событий и p1=0,4, p2=0,3, p3=0,15, p4=0,1, p5=0,05.
nср = ∑[i=1, 5] Pi * ni = 2,05 бит,
H(x)= - ∑[i=1, 5] Pi * log2 Pi=2,01 бит,
log2m=1, Ки = (2,85 — 2,01)/2,05 =0,02=2%
Знание эффективных кодов позволяет ответить на вопрос — какова должна быть минимальная длина кодовых комбинаций, чтобы передать
информацию, заложенную в источник сообщения при отсутствии помех. Меньше уровня не должно быть. На нем можно создавать надстройку, т.е. вводить дополнительные разряды для решения задач борьбы с помехами. Как правило, кодовые комбинации эффективных кодов имеют разную длину для разных сообщений. Это приводит к необходимости отмечать специальными символами начало и конец передачи сообщения, что усложняет и замедляет передачу. Коды, имеющие разную длину кодовых комбинаций, называются неравнозначными.
Пожалуйста, пиши комментарии, если ты обнаружил что-то неправильное или если ты желаешь поделиться дополнительной информацией про код хаффмана Надеюсь, что теперь ты понял что такое код хаффмана, код шеннона-фано, алгоритм хаффмана и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Теория информации и кодирования
Комментарии
Оставить комментарий
Теория информации и кодирования
Термины: Теория информации и кодирования