Лекция
Привет, Вы узнаете о том , что такое бустинг, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое бустинг, алгоритмы бустинга , настоятельно рекомендую прочитать все из категории Машинное обучение.
бустинг (англ. boosting — усиление) — композиционный метаалгоритм машинного обучения, применяется, главным образом, для уменьшения смещения, а также дисперсии в обучении с учителем. Также определяется как семейство алгоритмов машинного обучения, преобразующих слабые обучающие алгоритмы к сильным .
Бустинг (boosting) - это метод машинного обучения, который используется для создания сильной ансамблевой модели путем комбинирования слабых моделей обучения, таких как деревья решений или регрессионные модели. Бустинг основан на идее последовательного обучения моделей, где каждая новая модель старается исправить ошибки предыдущих моделей.
Основной принцип бустинга заключается в том, чтобы последовательно обучать модели на взвешенных или изменяющихся обучающих данных, фокусируясь на объектах, на которых предыдущие модели показали плохую производительность. В результате модели, взятые вместе, образуют сильную композицию моделей, которая лучше справляется с задачей предсказания, чем отдельные модели.
Некоторые из популярных алгоритмов бустинга включают:
AdaBoost (Adaptive Boosting): Он использует взвешивание обучающих данных, чтобы модели фокусировались на объектах, на которых предыдущие модели допустили ошибки. Веса объектов обновляются на каждой итерации, чтобы учесть предыдущие ошибки.
Gradient Boosting: Он работает путем обучения моделей на остатках предыдущих моделей. Каждая новая модель старается уменьшить остатки предыдущих моделей, что приводит к улучшению качества предсказаний.
XGBoost (Extreme Gradient Boosting): Это оптимизированная версия градиентного бустинга, которая использует ряд оптимизаций и эвристик для улучшения производительности и точности моделей.
LightGBM: Это еще одна эффективная реализация градиентного бустинга, которая обладает высокой скоростью работы и хорошей масштабируемостью. Он использует сжатие данных и другие оптимизации для ускорения обучения моделей.
алгоритмы бустинга широко используются для решения задач классификации и регрессии, а также для ранжирования и других задач машинного обучения. Они обладают высокой предсказательной способностью и являются одними из наиболее мощных алгоритмов в области машинного обучения.
Бустинг основан на вопросе, поднятом Кернсом и Вэлиантом (1988, 1989) : «Может ли набор слабых обучающих алгоритмов создать сильный обучающий алгоритм?». Слабый обучающий алгоритм определяется как классификатор, который слабо коррелирует с правильной классификацией (может пометить примеры лучше, чем случайное угадывание). В отличие от слабого алгоритма, сильный обучающий алгоритм является классификатором, хорошо коррелирующим с верной классификацией.
Положительный ответ Роберта Шапирe в статье 1990 года на вопрос Кернса и Вэлианта имел большое значение для теории машинного обучения и статистики, и привел к созданию широкого спектра алгоритмов бустинга .
Гипотеза о бустинге относилась к процессу настройки алгоритма слабого обучения для получения строгого обучения. Неформально, спрашивается, вытекает ли из существования эффективного алгоритма обучения, выходом которого служит гипотеза, эффективность которой лишь слегка лучше случайного гадания (то есть слабое обучение), существование эффективного алгоритма, который дает гипотезу произвольной точности (то есть сильное обучение) . Алгоритмы, которые получают быстро такую гипотезу, становятся известны просто как «бустинг». Алгоритм «arcing» Фройнда и Шапире (Adaptive Resampling and Combining) , как общая техника, является более-менее синонимом бустингу
В то время как бустинг алгоритмически не ограничен, большинство алгоритмов бустинга состоит из итеративного обучения слабых классификаторов с целью сборки их в сильный классификатор. Когда они добавляются, им обычно приписываются некоторым образом веса, которые, обычно, связаны с точностью обучения. После того, как слабый классификатор добавлен, веса пересчитываются, что известно как «пересчет весовых коэффициентов». Об этом говорит сайт https://intellect.icu . Неверно классифицированные входные данные получают больший вес, а правильно классифицированные экземпляры теряют вес[nb 1]. Тем самым последующее слабое обучение фокусируется больше на примерах, где предыдущие слабые обучения дали ошибочную классификацию.
Есть много алгоритмов бустинга. Исходные алгоритмы, предложенные Робертом Шапире (рекурсивное доминирование, англ. recursive majority gate formulation) и Йоавом Фройндом (бустинг по доминированию) , не были адаптивными и не могли дать полного преимущества слабых обучений. Шапире и Фройнд затем разработали AdaBoost (Adaptive Boosting) — адаптивный алгоритм бустинга, который выиграл престижную премию Геделя.
Только алгоритмы, для которых можно доказать, что они являются алгоритмами бустинга в формулировке приближенно правильного обучения, могут быть точно названы алгоритмами бустинга. Другие алгоритмы, близкие по духу алгоритмам бустинга, иногда называются «алгоритмами максимального использования» (англ. leveraging algorythms), хотя они иногда также неверно называются алгоритмами бустинга .
Основное расхождение между многими алгоритмами бустинга заключается в методах определения весовых коэффициентов точек тренировочных данных и гипотез. Алгоритм AdaBoost очень популярен и исторически наиболее знаменателен, так как он был первым алгоритмом, который смог адаптироваться к слабому обучению. Алгоритм часто используется как базовое введение в алгоритмы бустинга в курсах обучения машин в университетах . Есть много недавно разработанных алгоритмов, таких как LPBoost, TotalBoost, BrownBoost, xgboost, MadaBoost, LogitBoost и др.. Многие алгоритмы бустинга попадают в модель AnyBoost , это показывает, что бустинг осуществляет градиентный спуск в пространстве функций используя выпуклую функцию потерь.
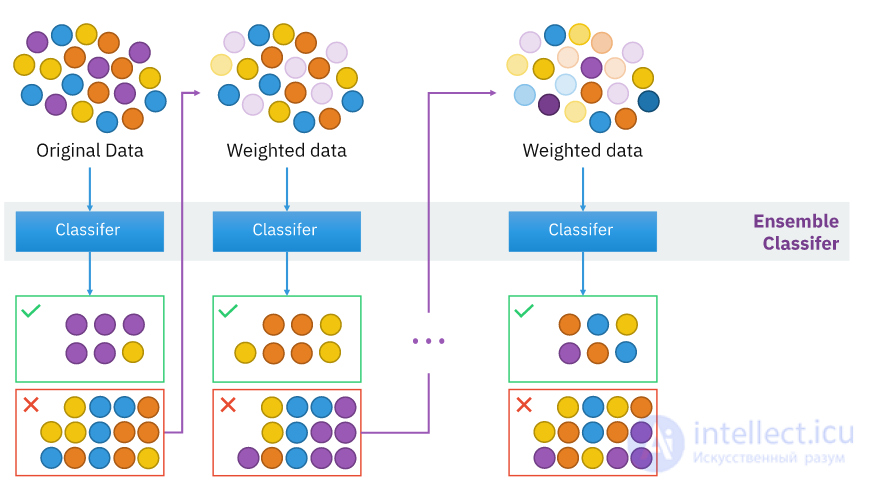
Иллюстрация, демонстрирующая интуицию алгоритма повышения, состоящего из параллельных учащихся и взвешенного набора данных.
Если даны изображения, содержащие различные известные в мире объекты, классификатор может быть обучен на основе них для автоматической классификации объектов в будущих неизвестных изображениях. Простые классификаторы, построенные на основе некоторых признаков изображения объекта, обычно оказываются малоэффективными в классификации. Использование методов бустинга для классификации объектов — это путь объединения слабых классификаторов специальным образом для улучшения общей возможности классификации.
Классификация признаков является типичной задачей компьютерного зрения, где определяется, содержит ли изображение некоторую категорию объектов или нет. Идея тесно связана с распознаванием, идентификацией и обнаружением. Классификация по обнаружению объекта обычно содержит выделение признаков, обучение классификатора и применение классификатора к новым данным. Есть много способов представления категории объектов, например по анализу формы, с помощью модели «мешок слов» , с помощью локальных описателей, таких как SIFT, и так далее. Примерами классификаторов с учителем служат наивные байесовские классификаторы, методы опорных векторов, смесь гауссиан и нейронные сети. Однако исследования показали, что категории объектов и их положение в изображениях могут быть обнаружены также с помощью обучения без учителя
Распознавание категорий объектов в изображениях является сложной задачей в компьютерном зрении, особенно если число категорий велико. Это является следствием высокой внутренней изменчивости классов и необходимости обобщения различных понятий внутри класса. Объекты в одной категории могут выглядеть совершенно различными. Даже один и тот же предмет может выглядеть непохожим с различных точек обзора, при другом масштабе или освещении. Шум заднего плана и частичные наложения также добавляют сложности в распознавание . Люди способны распознавать тысячи типов объектов, в то время как большинство существующих систем распознавания объектов тренируются для распознавания лишь нескольких, например человеческих лиц, автомобилей, простых объектов и т. д. . Исследования по увеличению числа категорий и возможности добавления новых категорий ведутся активно и, хотя общая проблема пока не решена, разработаны детекторы большого числа категорий (до сотен и тысяч ). Достигается это, в частности, с помощью совместного использования признаков и бустинга.
Пакет AdaBoost может быть использован для распознавания лиц как пример двоичной классификации. Две категории — это лица и фон. Общий алгоритм выглядит следующим образом:
После бустинга классификатор, построенный из 200 признаков, может достигать 95 % успешных распознаваний при  ошибок положительного распознавания .
ошибок положительного распознавания .
Другое приложение бустинга для двоичной классификации — система, которая распознает пешеходов с помощью паттернов движения и внешности . В этой работе впервые комбинируется информация о движении и внешность как признаки для обнаружения движущегося человека. В работе предпринимается подход, похожий на модель обнаружения объектов Виолы — Джонса.
По сравнению с двоичной классификацией, мультиклассовая классификация разыскивает общие признаки, которые могут использоваться совместно категориями в одно и то же время. Они оказываются более общими наподобие признака «граница». Во время обучения классификаторы для каждой категории могут быть тренированы совместно. По сравнению с раздельной тренировкой такая тренировка обладает лучшей обобщаемостью, требует меньше тренировочных данных и нужно меньше признаков для достижения необходимого результата.
Основная работа алгоритма похожа на двоичный случай. Разница заключается в том, что мера совместной ошибки тренировки может быть определено заранее. Во время каждой итерации алгоритм выбирает классификатор одного признака (признаки, которые могут быть совместно классифицированы, поощряются). Это может быть сделано путем преобразования мультиклассовой классификации в двоичную (набор категорий / остальные категории) или путем введения штрафа от категорий, которые не имеют признаков, распознаваемых классификатором .
В статье «Sharing visual features for multiclass and multiview object detection» (Совместное использование визуальных признаков для мультиклассового обнаружения объектов в нескольких проекциях), А. Торральба с соавторами использовали GentleBoost для бустинга и показали, что, если тренировочные данные ограничены, обучение с помощью совместно используемых признаков делает работу много лучше, чем без совместного использования. Также для заданного уровня производительности общее число признаков, требующихся (а потому и время работы классификатора) для обнаружения совместного использования признаков, растет примерно логарифмически от числа классов, то есть медленнее, чем линейно, что наблюдается в случае отсутствия совместного использования. Похожие результаты показаны в статье «Инкрементальное обучение обнаружения объектов, используя алфавит визуальных образов», впрочем, для бустинга авторы использовали AdaBoost.
Алгоритмы бустинга могут основываться на выпуклых или невыпуклых алгоритмах оптимизации. Выпуклые алгоритмы, такие как AdaBoost и LogitBoost, могут «потерпеть крушение» из-за случайного шума, так как не могут обучить базовым и поддающимся научению комбинациям слабых гипотез . На это ограничение указали Лонг и Серведо в 2008. Однако в 2009 несколько авторов продемонстрировали, что алгоритмы бустинга, основанные на невыпуклой оптимизации, такие как BrownBoost, могут быть обучены из данных с шумами и лежащий в основе классификатор Лонг-Серведио для набора данных может быть обучен.
Исследование, описанное в статье про бустинг, подчеркивает ее значимость в современном мире. Надеюсь, что теперь ты понял что такое бустинг, алгоритмы бустинга и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Машинное обучение
Комментарии
Оставить комментарий
Машинное обучение
Термины: Машинное обучение