алгоритмы планирования запросов к жесткому диску являются важной частью операционных систем и файловых систем. Они определяют порядок обработки запросов на чтение или запись данных на диск, чтобы минимизировать время доступа и оптимизировать производительность системы ввода-вывода.
Прежде чем приступить к непосредственному изложению самих алгоритмов, давайте вспомним внутреннее устройство жесткого диска и определим, какие параметры запросов мы можем использовать для планирования.

При оценке производительности жестких дисков наиболее важной характеристикой является скорость передачи данных. При этом на скорость и общую производительность влияет целый ряд факторов:
- Интерфейс подключения — SATA/IDE/SCSI (а для внешних дисков — USB/FireWare/eSATA). Все интерфейсы имеют разную скорость обмена данных.
- Объем кэша или буфера жесткого диска. Увеличение объема буфера позволяет увеличить скорость передачи данных.
- Поддержка NCQ, TCQ и прочих алгоритмов повышения быстродействия.
- Объем диска. Чем больше данных можно записать, тем больше времени нужно на чтение информации.
- Плотность информации на пластинах.
- И даже файловая система влияет на скорость обмена данных.
Но если мы возьмем два жестких диска одинакового объема и одного интерфейса, то ключевым фактором производительности будет скорость вращения шпинделя.
шпиндель — единая ось в жестком диске, на которой установлено несколько магнитных пластин. Эти пластины закреплены на шпинделе на строго определенном расстоянии. Расстояние должно быть таким, чтобы при вращении пластин считывающие головки могли читать и записывать на диск, но при этом не касались поверхности пластин.
Чтобы диск нормально функционировал, двигатель шпинделя должен обеспечивать стабильное вращение магнитных пластин на протяжении тысяч часов. Поэтому неудивительно, что иногда проблемы с диском связаны именно с заклиниванием шпинделя, а вовсе не с ошибками в файловой системе.
Двигатель отвечает за вращение пластин, и это позволяет работать жесткому диску.
Что такое скорость вращения шпинделя?
Скорость вращения шпинделя (spindle speed) определяет, насколько быстро вращаются пластины в нормальном режиме работы жесткого диска. Скорость вращения измеряется в оборотах в минуту (RpM).
От скорости вращения зависит, как быстро компьютер может получить данные от жесткого диска. Перед тем как винчестер сможет считать данные, он должен их сначала найти.
Время, которое требуется для блока магнитных головок, чтобы перейти к запрошенной дорожке/цилиндру, называется временем поиска (seek latency). После того как считывающие головки переместятся в нужную дорожку/цилиндр, надо дождаться поворота пластин, чтобы необходимый сектор оказался под головкой. Это называется задержками на вращение (rotational latency time) и является прямой функцией скорости шпинделя. То есть, чем быстрее скорость шпинделя, тем меньше задержки на вращение.
Общие задержки на время поиска и задержки на вращение и определяют скорость доступа к данным. Во многих программах для оценки скорости hdd это параметр access to data time.
На что влияет скорость вращения шпинделя жесткого диска
Большинство стандартных 3,5″ жестких дисков сегодня имеют скорость вращения шпинделя 7200 оборотов в минуту. Для таких дисков время, за которое совершается половина оборота (avg. rotational latency), составляет 4,2 мс. Среднее время поиска у этих дисков — около 8,5 мс, что позволяет обеспечить доступ к данным примерно за 12,7 мс.
У жестких дисков WD Raptor скорость вращения магнитных пластин — 10 000 оборотов в минуту. Это уменьшает среднее время задержки на вращение до 3 мс. У «рапторов» и пластины меньшего диаметра, что позволило сократить среднее время поиска до ~5,5 мс. Итоговое среднее время доступа к данным — примерно 8,5 мс.
Есть несколько моделей SCSI (например, Seagate Cheetah), у которых скорость вращения шпинделя достигает 15 000 оборотов в минуту, а пластины еще меньше, чем у WD Raptor. Среднее время rotational latency у них — 2 мс (60 сек / 15 000 RPM / 2), среднее время поиска — 3,8 мс, среднее время доступа к данным — 5,8 мс.
Диски с высокой частотой вращения шпинделя имеют низкие значения как времени поиска, так и задержки на вращение (даже при произвольном доступе). Понятно, что жесткие диски с частотой шпинделя 5600 и 7200 обладают меньшей производительностью.
При этом при последовательном доступе к данным большими блоками разница будет несущественна, так как нет задержки на доступ к данным. Поэтому для жестких дисков рекомендуется регулярно делать дефрагментацию.
Как узнать скорость вращения шпинделя жесткого диска
На некоторых моделях скорость шпинделя написана прямо на наклейке. Найти эту информацию несложно, так как вариантов немного — 5400, 7200 или 10 000 RpM.
Если на вашем жестком диске на наклейке нет этой информации (или просто нет желания доставать диск, чтобы посмотреть на наклейку), на помощь придут специальные программы. Большинство программ для проверки HDD и анализа SMART покажут вам скорость вращения шпинделя и другую информацию по жесткому диску.
Какая скорость вращения лучше — 5400 или 7200?
На первый взгляд кажется, что чем быстрее, тем лучше. Однако надо учитывать, что с увеличением скорости вращения пластин диск сильнее нагревается и становится более шумным. Дисковые накопители с 7200 RpM универсальны для большинства задач, а диски с 5400 RpM отлично подойдут, например, для домашнего хранилища файлов.
что такое технология IntelliPower?
Технология WD IntelliPower уменьшает энергопотребление и шум за счет снижения скорости вращения шпинделя. А потеря производительности частично компенсируется оптимизацией алгоритмов кэширования. Похожая технология у HGST с целью сокращения энергопотребления называется CoolSpin.
А на что влияет скорость вращения шпинделя в гибридных дисках?
Поскольку в основе гибридных накопителей все те же жесткие диски, то и скорость вращения шпинделя влияет на скорость доступа, но уже в меньшей степени, так как используется большой кэш в энергонезависимой памяти
Строение жесткого диска и параметры планирования
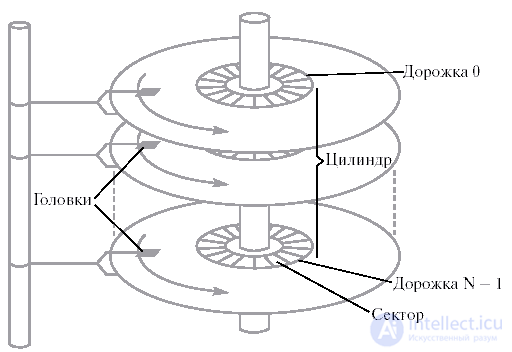
Современный жесткий магнитный диск представляет собой набор круглых пластин, находящихся на одной оси и покрытых с одной или двух сторон специальным магнитным слоем (см. рис. 13.2). Около каждой рабочей поверхности каждой пластины расположены магнитные головки для чтения и записи информации. Эти головки присоединены к специальному рычагу, который может перемещать весь блок головок над поверхностями пластин как единое целое. Поверхности пластин разделены на концентрические кольца, внутри которых, собственно, и может храниться информация. Набор концентрических колец на всех пластинах для одного положения головок (т. е. все кольца, равноудаленные от оси) образует цилиндр. Каждое кольцо внутри цилиндра получило название дорожки (по одной или две дорожки на каждую пластину). Все дорожки делятся на равное число секторов. Количество дорожек, цилиндров и секторов может варьироваться от одного жесткого диска к другому в достаточно широких пределах. Как правило, сектор является минимальным объемом информации, которая может быть прочитана с диска за один раз.
При работе диска набор пластин вращается вокруг своей оси с высокой скоростью, подставляя по очереди под головки соответствующих дорожек все их сектора. Номер сектора, номер дорожки и номер цилиндра однозначно определяют положение данных на жестком диске и, наряду с типом совершаемой операции – чтение или запись, полностью характеризуют часть запроса, связанную с устройством, при обмене информацией в объеме одного сектора.
Рис. 13.2. Схема жесткого диска
При планировании использования жесткого диска естественным параметром планирования является время, которое потребуется для выполнения очередного запроса. Время, необходимое для чтения или записи определенного сектора на определенной дорожке определенного цилиндра, можно разделить на две составляющие: время обмена информацией между магнитной головкой и компьютером, которое обычно не зависит от положения данных и определяется скоростью их передачи (transfer speed), и время, необходимое для позиционирования головки над заданным сектором, – время позиционирования (positioning time). Время позиционирования, в свою очередь, состоит из времени, необходимого для перемещения головок на нужный цилиндр, – времени поиска (seek time) и времени, которое требуется для того, чтобы нужный сектор довернулся под головку, – задержки на вращение (rotational latency). Времена поиска пропорциональны разнице между номерами цилиндров предыдущего и планируемого запросов, и их легко сравнивать. Задержка на вращение определяется довольно сложными соотношениями между номерами цилиндров и секторов предыдущего и планируемого запросов и скоростями вращения диска и перемещения головок. Без знания соотношения этих скоростей сравнение становится невозможным. Поэтому естественно, что набор параметров планирования сокращается до времени поиска различных запросов, определяемого текущим положением головки и номерами требуемых цилиндров, а разницей в задержках на вращение пренебрегают.
Планирование диска выполняется операционными системами для планирования запросов ввода-вывода, поступающих на диск. Планирование диска также известно как планирование ввода-вывода.
Планирование диска важно, потому что:
- Множественные запросы ввода-вывода могут поступать от разных процессов, и только один запрос ввода-вывода может обслуживаться контроллером диска одновременно. Таким образом, другие запросы ввода-вывода должны ждать в очереди ожидания и должны быть запланированы.
- Два или более запроса могут находиться далеко друг от друга, что может привести к большему перемещению рычага диска.
- Жесткие диски - одна из самых медленных частей компьютерной системы, и поэтому доступ к ним должен быть эффективным.
Существует множество алгоритмов планирования работы дисков, но прежде чем обсуждать их, давайте кратко рассмотрим некоторые из важных терминов:
- Время поиска : время поиска - это время, необходимое для нахождения плеча диска на указанной дорожке, где данные должны быть прочитаны или записаны. Так что алгоритм планирования диска, который дает минимальное среднее время поиска, лучше.
- Задержка при повороте : Задержка при повороте - это время, необходимое желаемому сектору диска для поворота в положение, чтобы он мог получить доступ к головкам чтения / записи. Таким образом, алгоритм планирования диска, который дает минимальную задержку вращения, лучше.
- Время передачи: Время передачи - это время передачи данных. Это зависит от скорости вращения диска и количества передаваемых байтов.
- Время доступа к диску: Время доступа к диску:
Время доступа к диску = Время поиска + Вращательная задержка + Время передачи
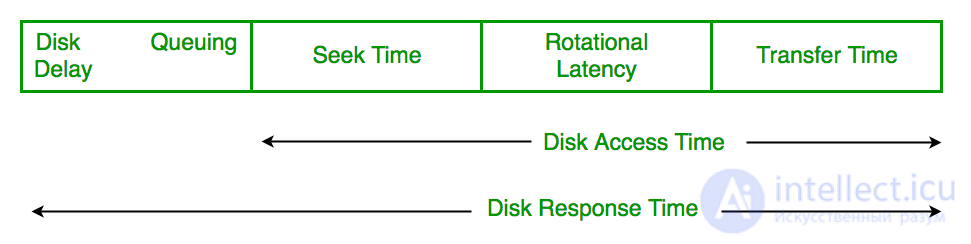
Время отклика диска: время отклика - это среднее время, затраченное запросом на ожидание выполнения операции ввода-вывода. Среднее время ответа - это время ответа на все запросы. Время отклика отклонения - это мера того, как индивидуальный запрос обслуживается относительно среднего времени ответа. Таким образом, алгоритм планирования диска, который дает минимальное время отклика дисперсии, лучше
Алгоритм First Come First Served (FCFS)
Простейшим алгоритмом, к которому мы уже должны были привыкнуть, является алгоритм First Come First Served (FCFS) – первым пришел, первым обслужен. Все запросы организуются в очередь FIFO и обслуживаются в порядке поступления. Алгоритм прост в реализации, но может приводить к достаточно длительному общему времени обслуживания запросов. Рассмотрим пример. Пусть у нас на диске из 100 цилиндров (от 0 до 99) есть следующая очередь запросов: 23, 67, 55, 14, 31, 7, 84, 10 и головки в начальный момент находятся на 63-м цилиндре. Тогда положение головок будет меняться следующим образом:
63->23->67->55->14->31->7->84->10
и всего головки переместятся на 329 цилиндров.
(63-23)+(67-23)+(67-55)+(55-14)+(31-14)+(31-7)+(84-7)+(84-10) =329
Неэффективность алгоритма хорошо иллюстрируется двумя последними перемещениями с 7 цилиндра через весь диск на 84 цилиндр и затем опять через весь диск на цилиндр 10. Простая замена порядка двух последних перемещений (7 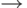 10 84) позволила бы существенно сократить общее время обслуживания запросов. Поэтому давайте перейдем к рассмотрению другого алгоритма.
10 84) позволила бы существенно сократить общее время обслуживания запросов. Поэтому давайте перейдем к рассмотрению другого алгоритма.
Алгоритм Short Seek Time First (SSTF)
Как мы убедились, достаточно разумным является первоочередное обслуживание запросов, данные для которых лежат рядом с текущей позицией головок, а уж затем далеко отстоящих. Алгоритм Short Seek Time First (SSTF) – короткое время поиска первым – как раз и исходит из этой позиции. Для очередного обслуживания будем выбирать запрос, данные для которого лежат наиболее близко к текущему положению магнитных головок. Естественно, что при наличии равноудаленных запросов решение о выборе между ними может приниматься исходя из различных соображений, например по алгоритму FCFS. Для предыдущего примера алгоритм даст такую последовательность положений головок:
63->67->55->31->23->14->10->7->84
и всего головки переместятся на 141 цилиндр. Заметим, что наш алгоритм похож на алгоритм SJF планирования процессов, если за аналог оценки времени очередного CPU burst процесса выбирать расстояние между текущим положением головки и положением, необходимым для удовлетворения запроса. И точно так же, как алгоритм SJF, он может приводить к длительному откладыванию выполнения какого-либо запроса. Необходимо вспомнить, что запросы в очереди могут появляться в любой момент времени. Если у нас все запросы, кроме одного, постоянно группируются в области с большими номерами цилиндров, то этот один запрос может находиться в очереди неопределенно долго.
Точный алгоритм SJF являлся оптимальным для заданного набора процессов с заданными временами CPU burst. Очевидно, что алгоритм SSTF не является оптимальным. Если мы перенесем обслуживание запроса 67-го цилиндра в промежуток между запросами 7-го и 84-го цилиндров, мы уменьшим общее время обслуживания. Это наблюдение приводит нас к идее целого семейства других алгоритмов – алгоритмов сканирования.
Алгоритмы сканирования (SCAN, C-SCAN, LOOK, C-LOOK)
В простейшем из алгоритмов сканирования – SCAN – головки постоянно перемещаются от одного края диска до другого, по ходу дела обслуживая все встречающиеся запросы. По достижении другого края направление движения меняется, и все повторяется снова. Пусть в предыдущем примере в начальный момент времени головки двигаются в направлении уменьшения номеров цилиндров. Тогда мы и получим порядок обслуживания запросов, подсмотренный в конце предыдущего раздела. Последовательность перемещения головок выглядит следующим образом:
63->55->31->23->14->10->7->0->67->84
и всего головки переместятся на 147 цилиндров.
Если мы знаем, что обслужили последний попутный запрос в направлении движения головок, то мы можем не доходить до края диска, а сразу изменить направление движения на обратное:
63->55->31->23->14->10->7->67->84
и всего головки переместятся на 133 цилиндра. Полученная модификация алгоритма SCAN получила название LOOK.
Допустим, что к моменту изменения направления движения головки в алгоритме SCAN, т. е. когда головка достигла одного из краев диска, у этого края накопилось большое количество новых запросов, на обслуживание которых будет потрачено достаточно много времени (не забываем, что надо не только перемещать головку, но еще и передавать прочитанные данные!). Тогда запросы, относящиеся к другому краю диска и поступившие раньше, будут ждать обслуживания несправедливо долго. Для сокращения времени ожидания запросов применяется другая модификация алгоритма SCAN – циклическое сканирование. Когда головка достигает одного из краев диска, она без чтения попутных запросов (иногда существенно быстрее, чем при выполнении обычного поиска цилиндра) перемещается на другой край, откуда вновь начинает движение в прежнем направлении. Для этого алгоритма, получившего название C-SCAN, последовательность перемещений будет выглядеть так:
63->55->31->23->14->10->7->0->99->84->67
По аналогии с алгоритмом LOOK для алгоритма SCAN можно предложить и алгоритм C-LOOK для алгоритма C-SCAN:
63->55->31->23->14->10->7->84->67
Существуют и другие разновидности алгоритмов сканирования, и совсем другие алгоритмы, но мы на этом закончим, ибо было сказано: "И еще раз говорю: никто не обнимет необъятного".
Алгоритмы планирования и перемещения головок
Алгоритм "Первый пришел, первый обслужен".
Рассмотрим пример. Пусть у нас на диске из 28 цилиндров (от 0 до 27) есть следующая очередь запросов:
27, 2, 26, 3, 19, 0
и головки в начальный момент находятся на 1 цилиндре. Тогда положение головок будет меняться следующим образом:

Алгоритм FCFS

Как видно, алгоритм не очень эффектный, но простой в реализации.
Алгоритм короткое время поиска первым (или ближайший цилиндр первым) ssf (Shortest Seek First)
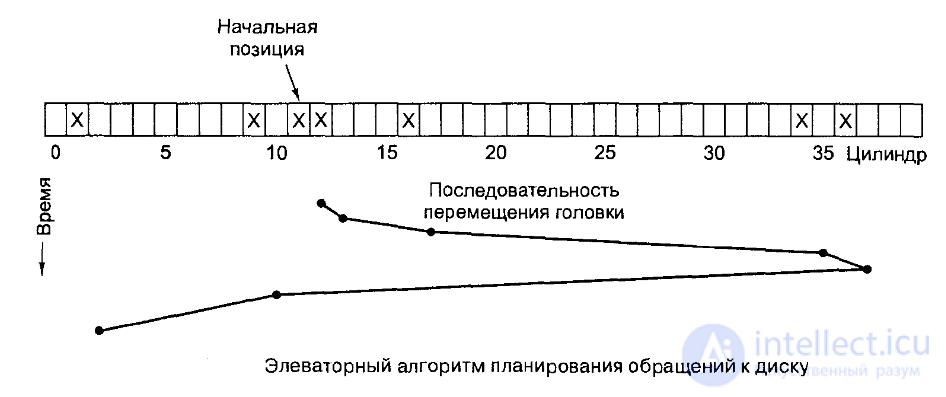
Для предыдущего примера алгоритм даст следующую последовательность положений головок:
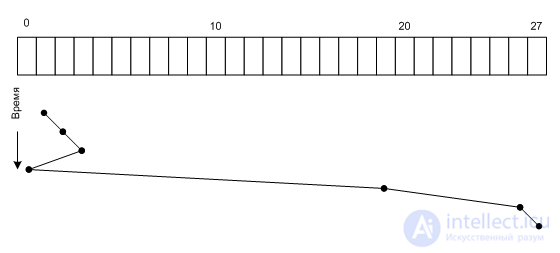
Алгоритм SSF
Как видим, этот алгоритм более эффективен. Но у него есть не достаток, если будут поступать постоянно новые запросы, то головка будет всегда находиться в локальном месте, вероятнее всего в средней части диска, а крайние цилиндры могут быть не обслужены никогда.
Алгоритм более эффективен, но у него есть недостаток: если будут поступать постоянно новые запросы, головка будет всегда находиться в локальном месте, вероятнее всего в средней части диска от грани границы могут быть неонаружены никогда.
Алгоритм SCAN
Алгоритм SCAN-головки постоянно перемещаются от одного края диска до другого края, по ходу дела обжуливая все встречающиеся запросы. Просто, но не всегда эффективно.
- SCAN: в алгоритме SCAN плечо диска движется в определенном направлении и обслуживает запросы, поступающие на его пути, а после достижения конца диска он меняет свое направление на противоположное и снова обслуживает запрос, поступающий на его пути. Итак, этот алгоритм работает как лифт и, следовательно, также известен как алгоритм лифта. В результате запросы на среднем уровне обслуживаются больше, а те, которые поступают за плечами диска, должны будут ждать.
Пример:
Предположим, что запросы, которые нужно адресовать: -82,170,43,140,24,16,190. И плечо чтения / записи находится на 50, и также указано, что плечо диска должно двигаться «к большему значению».
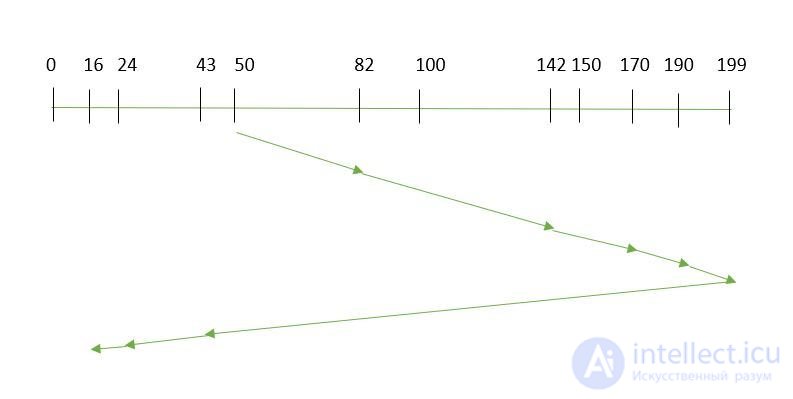
Следовательно, время поиска рассчитывается как:= (199-50) + (199-16)
= 332
Преимущества:
- Высокая пропускная способность
- Низкая дисперсия времени ответа
- Среднее время ответа
Недостатки:
- Долгое время ожидания запросов на локации, которые только что посетил диск.
Алгоритм LOOK
Алгоритм LOOK-если известно, что обслужили последний попутный запрос в направлении движения головок, то может не доходить до края диска, а сразу изменить направление движения в обратную сторону.
CLOOK: поскольку LOOK похож на алгоритм SCAN, аналогично CLOOK похож на алгоритм планирования диска CSCAN. В CLOOK дисковый рычаг, несмотря на то, что он дошел до конца, переходит только к последнему запросу для обслуживания перед головкой, а затем оттуда переходит к последнему запросу другого конца. Таким образом, это также предотвращает дополнительную задержку, которая возникла из-за ненужного перехода к концу диска.
Пример:
Предположим, что запросы, которые нужно адресовать: -82,170,43,140,24,16,190. И плечо чтения / записи находится на 50, и также указано, что плечо диска должно двигаться «в сторону большего значения».
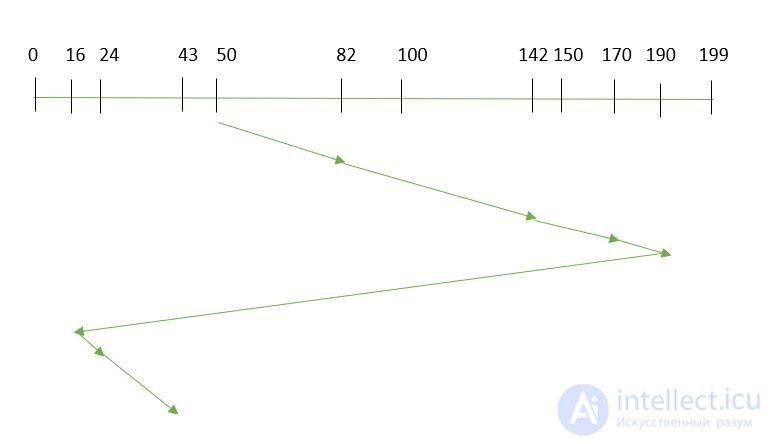
Итак, время поиска рассчитывается как:
= (190-50) + (190-16) + (43-16)
= 341
Алгоритм планирования диска C-LOOK
Учитывая массив номеров дорожек на диске и начальное положение головки, наша задача - найти общее количество операций поиска, выполненных для доступа ко всем запрошенным дорожкам, если используется алгоритм планирования диска C-LOOK . Кроме того, напишите программу для поиска последовательности поиска с помощью алгоритма планирования диска C-LOOK .
C-LOOK (Circular LOOK) Алгоритм планирования диска:
C-LOOK - это улучшенная версия алгоритмов планирования как SCAN, так и LOOK . Этот алгоритм также использует идею обертывания дорожек в виде кругового цилиндра, как алгоритм C-SCAN, но время поиска лучше, чем алгоритм C-SCAN. Мы знаем, что C-SCAN используется, чтобы избежать остановки и более единообразно обслуживает все запросы, то же самое касается C-LOOK.
В этом алгоритме голова обслуживает запросы только в одном направлении (влево или вправо) до тех пор, пока все запросы в этом направлении не будут обслужены, а затем переходит обратно к самому дальнему запросу в другом направлении и обслуживает оставшиеся запросы, что дает лучшую однородность обслуживание, а также позволяет избежать траты времени на поиск до конца диска.
Алгоритм-
-
Let Request array представляет собой массив, в котором хранятся индексы треков, которые были запрошены, в порядке возрастания времени их прибытия, а head - это положение головки диска.
-
Дается исходное направление, в котором движется голова, и она обслуживает в том же направлении.
-
Голова обслуживает все запросы по очереди в том направлении, в котором она движется.
-
Голова продолжает двигаться в том же направлении, пока все запросы в этом направлении не будут обслужены.
-
Двигаясь в этом направлении, рассчитайте абсолютное расстояние дорожек от головы.
-
Увеличьте общий счетчик поиска с этим расстоянием.
-
Положение гусеницы, обслуживаемой в настоящее время, теперь становится новым положением головы.
-
Переходим к шагу 5, пока не дойдем до последнего запроса в этом направлении.
-
Если мы достигаем последнего запроса в текущем направлении, то меняем направление и перемещаем головку в этом направлении, пока мы не дойдем до последнего запроса, который необходимо обслуживать в этом направлении, без обслуживания промежуточных запросов.
-
Поменяйте направление и переходите к шагу 3, пока все запросы не будут обработаны.
Примеры:
Ввод:
последовательность запросов = {176, 79, 34, 60, 92, 11, 41, 114}
Начальное положение головки = 50
Направление = вправо (перемещение слева направо)
Вывод:
Исходное положение головки: 50
Общее количество операций поиска = 156
Последовательность поиска
60
79
92
114
176
11
34
41
В следующей таблице показана последовательность, в которой запрашиваемые треки обслуживаются с помощью C-LOOK.
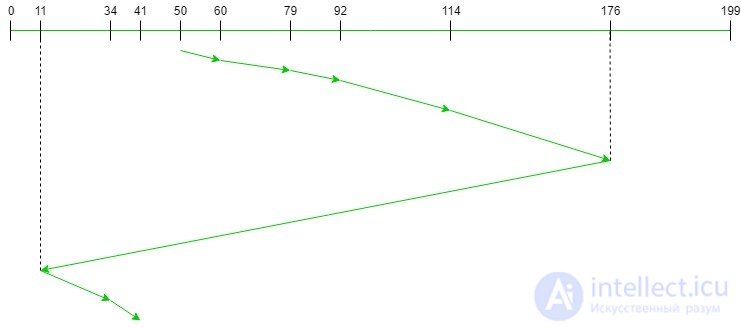
Таким образом, общее количество поисков = (60-50) + (79-60) + (92-79) + (114-92) + (176-114) + (176-11) + (34-11) + ( 41 - 34) = 321
Алгоритм C-SCAN
Алгоритм C-SCAN-циклическое санирование когда головка достигает одного из краев диска, она без чтения попутных запросов перемещаетья на нулевой цилиндр, откуда вновь начинает движение.
Учитывая массив номеров дорожек на диске и начальное положение головки, наша задача - найти общее количество операций поиска, выполненных для доступа ко всем запрошенным дорожкам, если используется алгоритм планирования диска C-SCAN .
Что такое алгоритм планирования дисков C-SCAN (Circular Elevator)?
Алгоритм планирования кругового сканирования (C-SCAN) - это модифицированная версия алгоритма планирования диска SCAN, которая устраняет неэффективность алгоритма SCAN за счет более равномерного обслуживания запросов. Как и SCAN (алгоритм лифта), C-SCAN перемещает головку с одного конца, обслуживая все запросы, на другой конец. Однако, как только головка достигает другого конца, она немедленно возвращается к началу диска, не обслуживая никаких запросов на обратном пути (см. Диаграмму ниже), и снова начинает обслуживание, как только достигает начала. Это также известно как «Алгоритм кругового лифта», поскольку он, по сути, рассматривает цилиндры как круговой список, который проходит от последнего цилиндра к первому.
Алгоритм:
- Массив Let Request представляет собой массив, в котором хранятся индексы треков, которые были запрошены, в порядке возрастания времени их прибытия. «голова» - это положение головки диска.
- Голова обслуживает только в правильном направлении от 0 до размера диска.
- При движении влево не обслуживайте ни одну из трасс.
- Когда мы дойдем до начала (левого конца), поменяйте направление.
- Двигаясь в правильном направлении, он обслуживает все треки один за другим.
- Двигаясь в правильном направлении, рассчитайте абсолютное расстояние трека от головы.
- Увеличьте общий счетчик поиска с этим расстоянием.
- Положение гусеницы, обслуживаемой в настоящее время, теперь становится новым положением головы.
- Переходите к шагу 6, пока не дойдете до правого конца диска.
- Если мы дойдем до правого конца диска, измените направление и перейдем к шагу 3, пока все дорожки в массиве запросов не будут обслужены.
Примеры:
Вход: Последовательность запросов = {176, 79, 34, 60, 92, 11, 41, 114} Исходное положение головы = 50 Выход: Исходное положение головы: 50 Общее количество операций поиска = 190 Последовательность поиска 60 79 92 114 176 199 0 11 34 41 год
Следующая диаграмма показывает последовательность, в которой запрашиваемые дорожки обслуживаются с помощью SCAN.

Следовательно, общее количество поисков рассчитывается как:
= (60-50) + (79-60) + (92-79)
+ (114-92) + (176-114) + (199-176) + (199-0)
+ (11-0) + (34-11) + (41-34)
Алгоритм RSS - это означает случайное планирование и, как и его название, это природа. Он используется в ситуациях, когда планирование включает случайные атрибуты, такие как случайное время обработки, случайные сроки выполнения, случайные веса и стохастические поломки машины, этот алгоритм идеально подходит. Вот почему он обычно используется для анализа и моделирования.
- LIFO - В алгоритме LIFO (Last In, First Out) самые новые задания обслуживаются перед существующими, то есть в порядке обработки запросов: сначала обслуживается задание, которое является самым новым или последним введенным, а затем остальные в том же порядке.
Преимущества
- Максимизирует локальность и использование ресурсов
Недостатки
- Может показаться немного несправедливым по отношению к другим запросам, и если новые запросы продолжают поступать, это вызывает голод для старых и существующих.
Пример
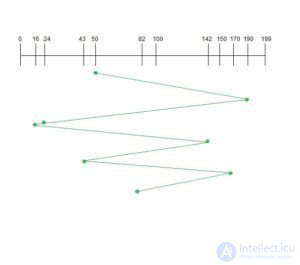
Предположим, что порядок запросов - (82,170,43,142,24,16,190),
а текущее положение головки чтения / записи: 50
- N-STEP SCAN - он также известен как алгоритм N-STEP LOOK. При этом создается буфер для N запросов. Все запросы, принадлежащие буферу, будут обслуживаться за один раз. Также после заполнения буфера новые запросы не хранятся в этом буфере и отправляются в другой. Теперь, когда эти N запросов обслуживаются, наступает время для еще N самых популярных запросов, и таким образом все получаемые запросы получают гарантированное обслуживание.
Преимущества
- Полностью устраняет голод запросов
- FSCAN - этот алгоритм использует две под-очереди. Во время сканирования все запросы в первой очереди обслуживаются, а новые входящие запросы добавляются во вторую очередь. Все новые запросы задерживаются до тех пор, пока не будут обработаны существующие запросы в первой очереди.
Преимущества
- FSCAN вместе с N-Step-SCAN предотвращает «липкость руки» (явление при планировании ввода / вывода, когда алгоритм планирования продолжает обслуживать запросы в текущем секторе или рядом с ним и, таким образом, предотвращает любой поиск)
Каждый алгоритм по-своему уникален. Общая производительность зависит от количества и типа запросов.
Примечание. Средняя задержка вращения обычно принимается равной 1/2 (задержка вращения).
Выводы
Таким образом , мы рассмотрели несколько классических алгоритмов планирования запросов к жесткому диску:
-
First-Come, First-Served (FCFS): Это простой алгоритм, при котором запросы обрабатываются в порядке их поступления. Однако он может привести к проблеме "эффекта бедного мальчика" (англ. "starvation"), когда некоторые запросы ожидают длительное время из-за постоянного поступления новых запросов.
-
Shortest Seek Time First (SSTF): Этот алгоритм выбирает запрос, который имеет наименьшее расстояние до головки диска. Он направлен на минимизацию времени перемещения головки диска. Однако у него тоже есть проблема: запросы, находящиеся на краях диска, могут быть забыты, что может привести к так называемому "эффекту забытых запросов" (англ. "forgetful read" problem).
-
SCAN (Elevator) Algorithm: Головка диска двигается от одного конца к другому и обрабатывает все запросы на своем пути. Когда она достигает конца, она меняет направление. Этот метод эффективен, но может вызвать задержку для запросов, расположенных в середине диска.
-
C-SCAN (Circular SCAN) Algorithm: Подобен алгоритму SCAN, но при достижении конечной границы диска головка возвращается на начальную границу, минимизируя временные задержки для запросов.
-
LOOK Algorithm: Похож на SCAN, но при достижении края диска головка изменяет направление без остановки. Это снижает задержки по сравнению с SCAN.
-
C-LOOK Algorithm: Комбинация C-SCAN и LOOK. Головка движется только в одном направлении, проходя через все запросы, а затем возвращается на начальную границу.
Выбор конкретного алгоритма зависит от требований к производительности, структуры данных и особенностей использования жесткого диска в конкретной системе. Некоторые современные операционные системы и файловые системы могут использовать комбинации этих алгоритмов или внесенные улучшения для более эффективного управления запросами к жесткому диску.
Вау!! 😲 Ты еще не читал? Это зря!


Комментарии
Оставить комментарий
электромеханические устройства электронных аппаратов
Термины: электромеханические устройства электронных аппаратов