Лекция
Привет, Вы узнаете о том , что такое абстрактный тип данных, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое абстрактный тип данных, abstract data type, adt, атд, , настоятельно рекомендую прочитать все из категории Структуры данных.
абстрактный тип данных ( атд ) — это математическая модель для типов данных, где тип данных определяется поведением (семантикой) с точки зрения пользователя данных, а именно в терминах возможных значений, возможных операций над данными этого типа и поведения этих операций.
Формально АТД может быть определен как множество объектов, определяемое списком компонентов (операций, применимых к этим объектам, и их свойств). Вся внутренняя структура такого типа спрятана от разработчика программного обеспечения — в этом и заключается суть абстракции. Абстрактный тип данных определяет набор функций, независимых от конкретной реализации типа, для оперирования его значениями. Конкретные реализации АТД называются структурами данных.
В программировании абстрактные типы данных обычно представляются в виде интерфейсов, которые скрывают соответствующие реализации типов. Программисты работают с абстрактными типами данных исключительно через их интерфейсы, поскольку реализация может в будущем измениться. Такой подход соответствует принципу инкапсуляции в объектно-ориентированном программировании. Сильной стороной этой методики является именно сокрытие реализации. Раз вовне опубликован только интерфейс, то пока структура данных поддерживает этот интерфейс, все программы, работающие с заданной структурой абстрактным типом данных, будут продолжать работать. Разработчики структур данных стараются, не меняя внешнего интерфейса и семантики функций, постепенно дорабатывать реализации, улучшая алгоритмы по скорости, надежности и используемой памяти.
Различие между абстрактными типами данных и структурами данных, которые реализуют абстрактные типы, можно пояснить на следующем примере. Абстрактный тип данных список может быть реализован при помощи массива или линейного списка с использованием различных методов динамического выделения памяти. Однако каждая реализация определяет один и тот же набор функций, который должен работать одинаково (по результату, а не по скорости) для всех реализаций.
Абстрактные типы данных позволяют достичь модульности программных продуктов и иметь несколько альтернативных взаимозаменяемых реализаций отдельного модуля.
В информатике , абстрактный тип данных ( ADT ) является математической моделью для типов данных . Абстрактный тип данных определяется его поведением ( семантикой ) с точки зрения пользователя , данных, в частности, с точки зрения возможных значений, возможных операций над данными этого типа и поведения этих операций. Эта математическая модель отличается от структур данных , которые представляют собой конкретные представления данных и представляют собой точку зрения разработчика, а не пользователя.
Формально ADT может быть определен как «класс объектов, чье логическое поведение определяется набором значений и набором операций»; это аналог алгебраической структуры в математике. Что подразумевается под «поведением», зависит от автора, причем два основных типа формальных спецификаций поведения - аксиоматическая (алгебраическая) спецификация и абстрактная модель; Они соответствуют аксиоматической семантике и операционной семантике в качестве абстрактной машины , соответственно. Некоторые авторы также включают вычислительную сложность(«стоимость»), как с точки зрения времени (для вычислительных операций) и пространства (для представления значений). На практике многие распространенные типы данных не являются ADT, поскольку абстракция не идеальна, и пользователи должны знать о таких проблемах, как арифметическое переполнение , которые связаны с представлением. Например, целые числа часто хранятся как значения фиксированной ширины (32-разрядные или 64-разрядные двоичные числа) и, таким образом, испытывают переполнение целых чисел, если превышено максимальное значение.
ADT представляют собой теоретическую концепцию в области компьютерных наук, используемую при разработке и анализе алгоритмов , структур данных и программных систем, и они не соответствуют специфическим особенностям компьютерных языков - основные компьютерные языки напрямую не поддерживают формально определенные ADT. Тем не менее, различные языковые функции соответствуют определенным аспектам ADT, и их легко спутать с собственно ADT; К ним относятся абстрактные типы , непрозрачные типы данных , протоколы и дизайн по контракту . ADT были впервые предложены Барбарой Лисков и Стивеном Н. Зиллесом в 1974 году, как часть развития языка CLU .
Например, целые числа представляют собой ADT, определяемые как значения ..., -2, -1, 0, 1, 2, ... и операциями сложения, вычитания, умножения и деления вместе с большим, чем , меньше чем и т. д., которые ведут себя в соответствии со знакомой математикой (с заботой о целочисленном делении ), независимо от того, как целые числа представлены компьютером. [a] Явно, «поведение» включает в себя выполнение различных аксиом (ассоциативность и коммутативность сложения и т. д.) и предварительные условия для операций (не может делиться на ноль). Обычно целые числа представлены в структуре данных в виде двоичных чисел , чаще всего , как дополнение по , но может быть двоично-десятичной или вих можно дополнить , но пользователь абстрагируется от конкретного выбора представления и может просто использовать данные в качестве типов данных.
ADT состоит не только из операций, но также из значений базовых данных и ограничений на операции. «Интерфейс» обычно относится только к операциям и, возможно, к некоторым ограничениям на операции, особенно к предварительным условиям и постусловиям, но не к другим ограничениям, таким как отношения между операциями.
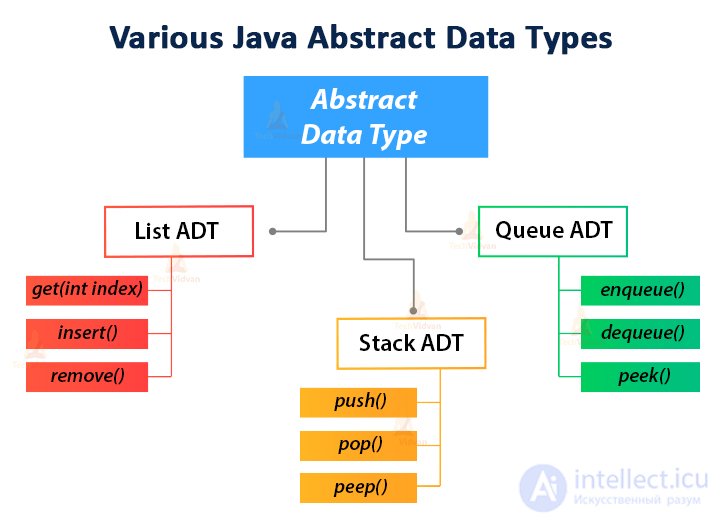
Примеры АТД
Некоторые распространенные ADT, которые доказали свою полезность в самых разных приложениях:
Каждый из этих ADT может быть определен многими способами и вариантами, не обязательно эквивалентными. Например, абстрактный стек может иметь или не иметь countоперацию, которая сообщает, сколько элементов было отправлено, но еще не извлечено. Этот выбор имеет значение не только для клиентов, но и для реализации.
Абстрактный графический тип данных
Расширение ADT для компьютерной графики было предложено в 1979 году: абстрактный графический тип данных (AGDT). Его представили Надя Магненат Тельманн и Даниэль Тельманн . AGDT предоставляют преимущества ADT со средствами для структурированного построения графических объектов.
Например, абстрактный стек , представляющий собой структуру «первым пришел-первым вышел», может быть определен тремя операциями: pushвставка элемента данных в стек; pop, который удаляет элемент данных из него; и peekили top, который обращается к элементу данных в верхней части стека без удаления. Абстрактная очередь , представляющая собой структуру «первым пришел - первым обслужена», также будет иметь три операции: enqueueвставка элемента данных в очередь; dequeue, который удаляет первый элемент данных из него; а такжеfront, который получает доступ и обслуживает первый элемент данных в очереди. Не было бы никакого способа дифференцировать эти два типа данных, если бы не было введено математическое ограничение, которое для стека указывает, что каждый всплывший всегда возвращает самый последний выдвинутый элемент, который еще не был извлечен. При анализе эффективности алгоритмов, использующих стеки, можно также указать, что все операции занимают одно и то же время независимо от того, сколько элементов данных было помещено в стек, и что стек использует постоянный объем памяти для каждого элемента.
Абстрактные типы данных - это чисто теоретические объекты, используемые (среди прочего) для упрощения описания абстрактных алгоритмов, для классификации и оценки структур данных, а также для формального описания систем типов языков программирования. Однако ADT может быть реализован конкретными типами данных или структурами данных многими способами и на многих языках программирования; или описано на языке формальной спецификации . ADT часто реализуются как модули : интерфейс модуля объявляет процедуры, которые соответствуют операциям ADT, иногда с комментариями, которые описывают ограничения. Эта информация скрываетсяСтратегия позволяет менять реализацию модуля, не мешая клиентским программам.
Термин абстрактный тип данных также можно рассматривать как обобщенный подход ряда алгебраических структур , таких как решетки, группы и кольца. Понятие абстрактных типов данных связано с концепцией абстракции данных , важной в объектно-ориентированном программировании и проектировании с помощью контрактных методологий разработки программного обеспечения .
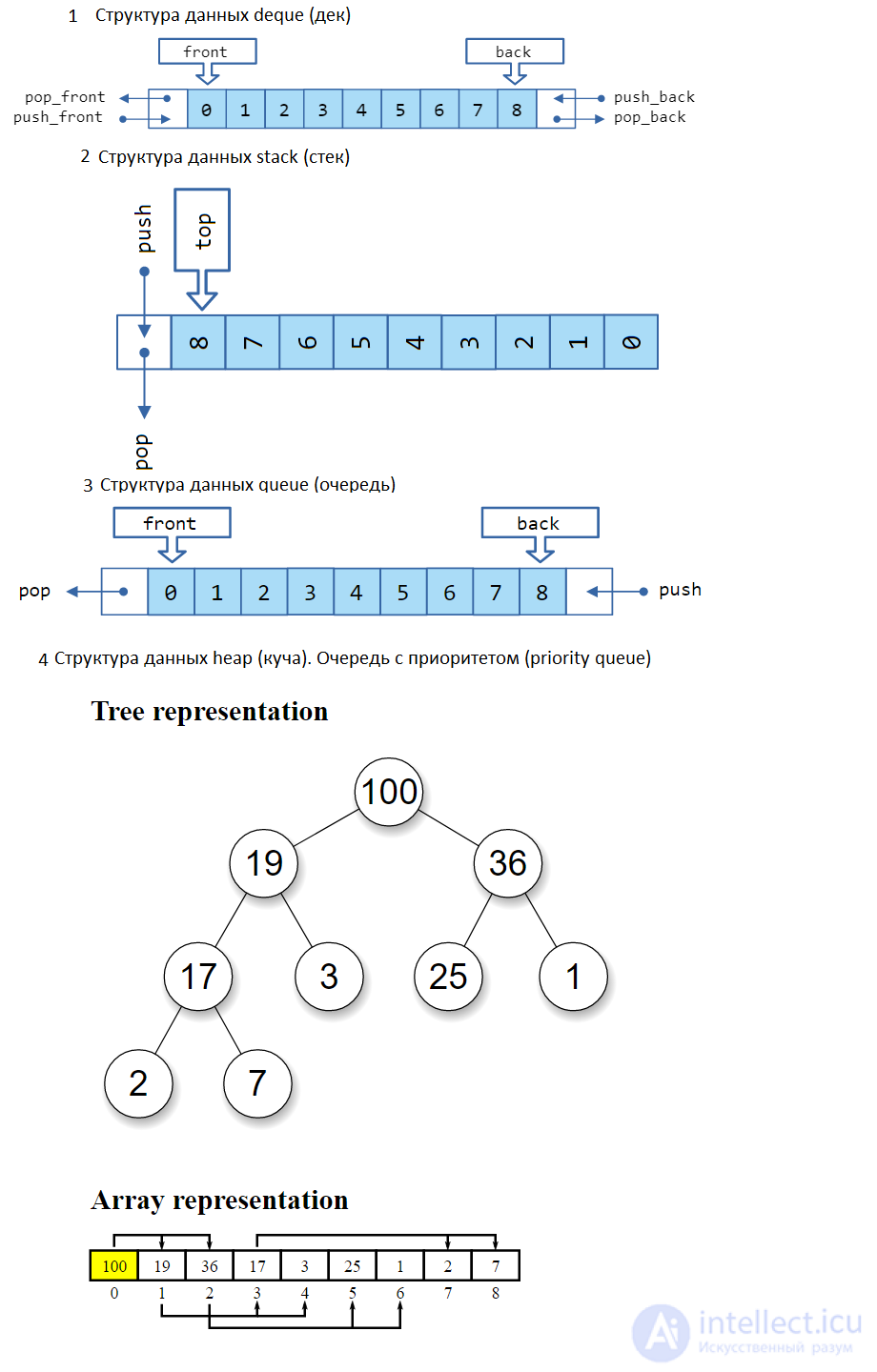
Структуры данных, которые мы рассмотрим на этом уроке, объединены тем, что создаются на основе массивов для эффективного решения определенного круга задач. В язык C++ структуры данных стек, очередь и куча можно реализовать на основе классов контейнеров vector и deque. С вектором мы познакомились ранее, настало время познакомиться с деком.
Дек, двусвязная очередь (от англ. deque — double ended queue) — структура данных, представляющая из себя список элементов, в которой добавление новых элементов и удаление существующих производится с обоих концов массива. Это позволяет многие задачи решать непосредственно с помощью дека, абстрагируясь до нужной структуры данных.

Контейнер deque очень похож на vector. deque также является последовательным контейнером произвольного доступа, следовательно, поддерживается индексация ([], at()), методы front() и back(), а также большинство других методов класса vector. Дек имеет аналогичные итераторы, в том числе, реверсивные. Но, в отличие от vector, расширение deque происходит более эффективно, т. к. перераспределение памяти не происходит (элементы не переносятся в новую область, в случае переполнения текущей). Дек более сложная структура данных, его элементы не всегда находятся в одной области памяти. Если вектор можно сравнить с С-массивом, то дек можно представить как комплект нескольких С-массивов (один или более), используемых как единый объект.
Главное отличие deque от (как vector) в том, что он открыт с обоих концов. Вставка элементов в начало и в конец deque осуществляется очень быстро. Но обход дека с помощью итераторов, будет осуществляться медленнее, чем обход вектора. При каждой вставке и удалении не в начало или не в конец дека приведет к недействительности итераторов как начала, так и конца (в том числе, указателей и ссылок на остальные элементы). Если вставка производится в начале или в конце массива, то недействительными окажутся только итераторы, ссылки же и указатели останутся в силе.
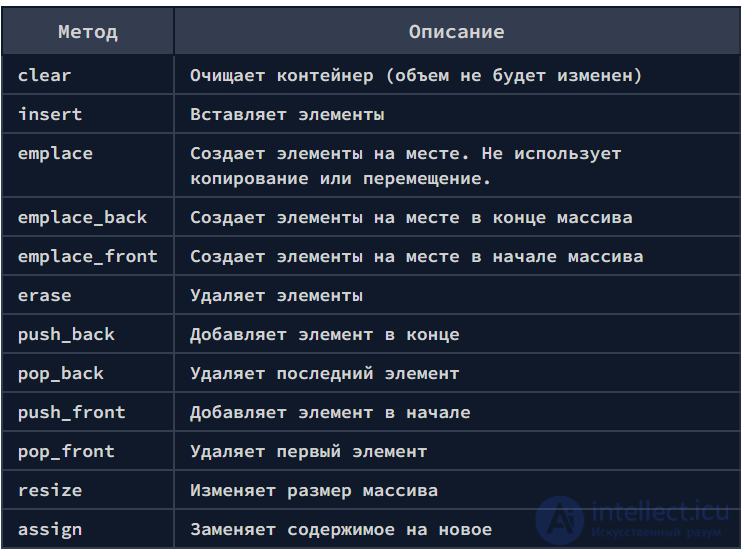
Для контейнера deque не определены методы работы с объемом capacity() и reserve(), но метод shrink_to_fit() использовать можно. Связано это с тем, что при уменьшении размера дека, объем его не уменьшается. Этот метод необязательно выполняет операцию уменьшения capacity() до size().
Решим с помощью дека следующую задачу.
Задача 1. Дан массив ar и числа m и n, определяющие позиции элементов в массиве ar (m < n). Определить на этом отрезке минимальный элемент. Задачу эту решить с помощью дека.

На основе дека можно моделировать структуры данных стек и очередь. Для этого в C++ используются контейнеры-адаптеры. Шаблонный класс контейнера-адаптера stack представляет собой надстройку над базовым контейнером и предоставляет только определенный набор функций, характерный для стека.
Стек - это структура данных, в которой элементы добавляются и удаляются в вершине стека. Массив элементов, организован по принципу LIFO (англ. last in — first out, «последним пришел — первым вышел»). Такую структуру можно представить как стопка тарелок (или книг): доступ ко второй (сверху) тарелке можно получить только после того, как будет взята первая тарелка.

В основу адаптера stack положен (по умолчанию) контейнер deque.
Для stack определены следующие методы:

Помимо этих методов, поддерживаются все операции сравнения и операция присваивания.
Рассмотрим одну из задач, которую легко можно решить с помощью стека.
Задача 2. В постфиксной записи арифметического выражения операция записывается после двух операндов. Об этом говорит сайт https://intellect.icu . Например, сумма двух чисел A и B записывается как A B +. Запись B C + D * обозначает (B + C) * D, а запись A B C + D * + означает A + (B + C) * D. Достоинство постфиксной записи в том, что она не требует скобок и дополнительных соглашений о приоритете операций для своего чтения.
Дано выражение в постфиксной записи, содержащее числа, операции +, –, *. Вычислите значение выражения, записанного в постфиксной форме (называемой также обратной польской записью). Числа и символы должны разделяться одним пробелом.
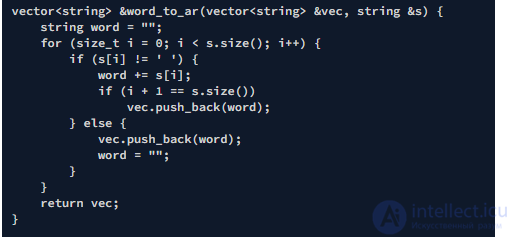
Ввод/вывод
Введите строку, изображающую арифметическое выражение: 5 5 4 + 10 * + 95
Очередь — это структура данных, в которой добавление элемента возможно лишь в конец очереди, а выборка — только из начала очереди, при этом выбранный элемент из очереди удаляется. Массив элементов, организован по принципу FIFO (англ. First In — First Out, «первый пришел — первый вышел»).

Для реализации этой структуры данных в C++ используется адаптер queue. В основу адаптера queue положен (по умолчанию) контейнер deque.
Для queue определены следующие методы:

Помимо этих методов, поддерживаются все операции сравнения и операция присваивания.
Очередь нашла свое применение в алгоритмах так называемого обхода дерева (или графа) в ширину (англ. breadth-first search, BFS). Не вдаваясь глубоко в теорию графов, рассмотрим пример такой задачи на основе задачи ЕГЭ.
Задача 3. Вася, решая задачи формата ЕГЭ, дошел до задачи об исполнителе:
«У исполнителя Калькулятор две команды:
34Выполняя первую из них, Калькулятор прибавляет к числу на экране 3, а выполняя вторую, умножает его на 4».
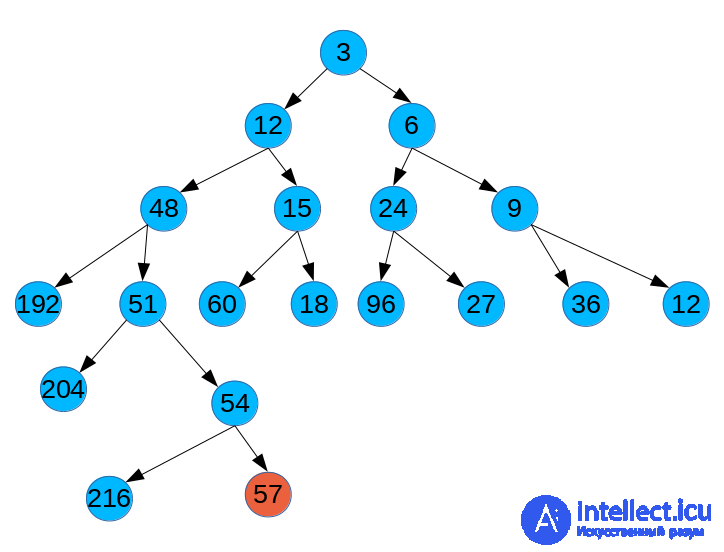
Далее, в задаче требовалось получить из числа 3 число 57 не более, чем за 6 команд. Однако Вася заинтересовался, как можно для произвольных чисел a и b построить программу наименьшей длины получения числа b из числа a. Напишите программу, которая по заданным числам a и b вычислит наименьшее количество команд Калькулятора, которое нужно, чтобы получить из a число b. Общее количество команд не должно превышать 10.
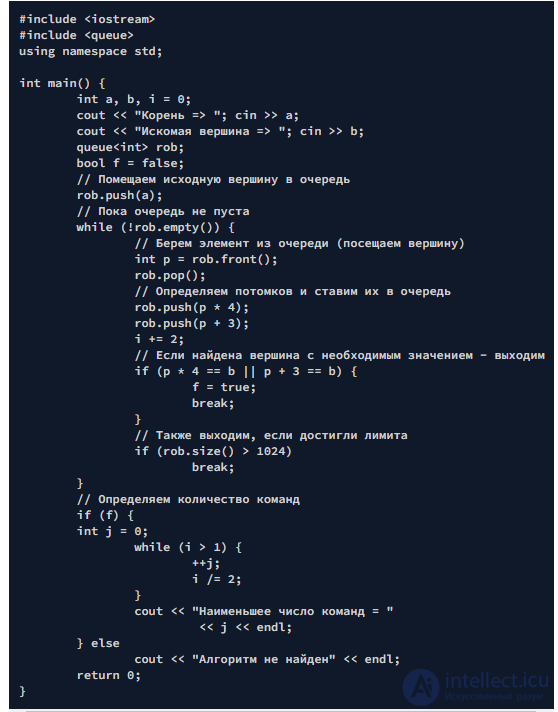
Куча (другие названия: двоичная куча, пирамида, сортирующее дерево) — это структура данных представленная в виде дерева. В классической куче нет ограничений на число потомков, но на практике их всегда два. Поэтому такую кучу называют двоичной кучей. Она удовлетворяет свойству кучи: если B является узлом-потомком узла A, то ключ A ≥ ключ B. Из этого следует, что элемент с наибольшим ключом всегда является корневым узлом кучи, поэтому иногда такие кучи называют max-кучами (максимальными кучами).
Для двоичного дерева кучи должны выполняться три условия:
Для реализации кучи можно взять любой последовательный контейнер или C-массив. Корневой элемент — A , а потомки элемента A[i] — A[2*i+1] и A[2*i+2].

Тогда индексы, в виде дерева, можно представить следующим образом:

Куча является максимально эффективной реализацией абстрактного типа данных, который называется очередью с приоритетом (priority queue). Очередь с приоритетом применяется в программах, которые включают в себя поиск максимального (или минимального) элемента в некотором массиве данных (например, самые активные пользователи социальной сети). Но это не единственное ее применение. С помощью очереди с приоритетом можно организовать планировщик задач, поиск оптимальных путей, прогнозирование событий и многие др. задачи.
algorithm (см. здесь).priority_queue (наряду с очередью и стеком) является адаптером контейнеров. В основе очереди с приоритетом находится, по умолчанию, контейнер vector (это может быть изменено, как и для других адаптеров). priority_queue предупреждает случайное аннулирование кучи. Элементы очереди сортируются автоматически по убыванию (max-куча). Направление сортировки можно изменить с помощью компаратора.
Для priority_queue (заголовок - queue) определены следующие методы:

С помощью кучи можно осуществить пирамидальную сортировку. Она выполняется путем вставки всех элементов последовательности в кучу и, затем, извлечением всех элементов кучи от наибольшего значения по порядку. Рассмотрим два варианта. Первый вариант основан на использовании priority_queue. Минус варианта - это вывод (или иная операция) с удалением элементов.

В priority_queue C++ реализована max-куча. В ней, как уже было сказано, элементы упорядочены от большего к меньшему. Чтобы изменить направление сортировки, в шаблонном параметре конструктора передается, помимо типа элементов, еще два необязательных элемента: тип базового контейнера и компаратор, изменяющий направление сортировки на обратное (см. стр. 18 в программе 9.6.4; в качестве компаратора выступает встроенная функция сравнения или функтор - greater).
array, поскольку последний не поддерживает операцию insert.Второй вариант основан на использовании библиотеки обобщенных алгоритмов.
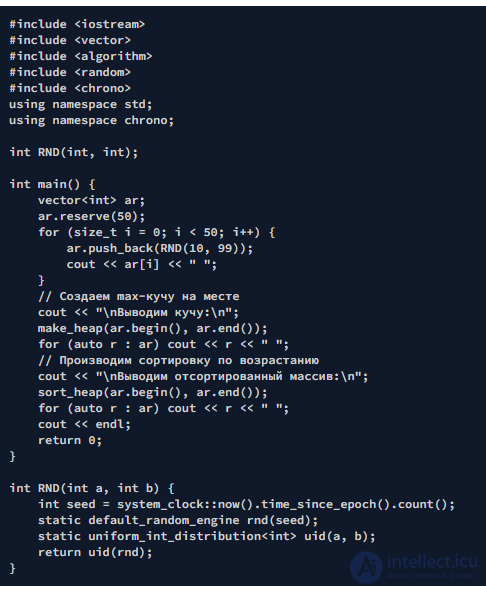
После выполнения сортировки, массив утрачивает свойство кучи.
Решим следующую задачу.
Задача 4. В игре участвуют N игроков (N >= 3). В каждом раунде пользователи по очереди бросают кость. Результаты суммируются по каждому раунду, количество которых не ограничено. По итогам игры выявляются три участника с максимальным результатом. Абсолютным победителем является игрок, первым набравший более 20 очков.
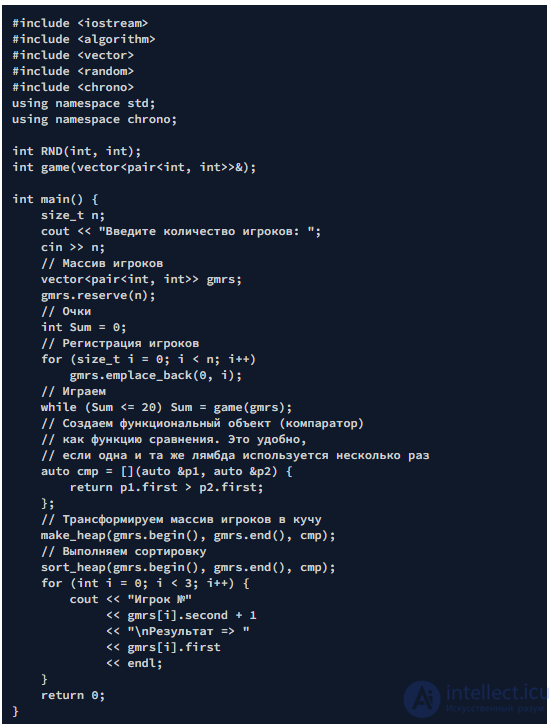
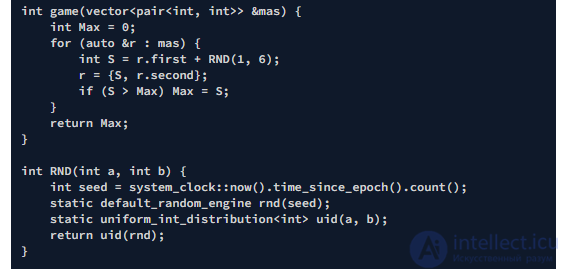
Возможный вывод
Введите количество игроков: 6 Игрок №2 Результат => 24 Игрок №5 Результат => 23 Игрок №6 Результат => 18
Абстрактный тип данных определяется как математическая модель объектов данных, которые составляют тип данных, а также функций, которые работают с этими объектами. Нет стандартных соглашений для их определения. Можно провести широкое разделение между «императивными» и «функциональными» стилями определений.
В философии императивных языков программирования абстрактная структура данных понимается как изменяемая сущность, что означает, что она может находиться в разных состояниях в разное время. Некоторые операции могут изменить состояние ADT; следовательно, важен порядок, в котором оцениваются операции, и одна и та же операция над одними и теми же объектами может иметь разные последствия, если она выполняется в разное время - точно так же, как инструкции компьютера или команды и процедуры императивного языка. Чтобы подчеркнуть это мнение, принято говорить, что операции выполняются или применяются , а не оцениваются, Императивный стиль часто используется при описании абстрактных алгоритмов. (См. «Искусство компьютерного программирования » Дональда Кнута для более подробной информации)
Абстрактная переменная
Определения ADT в императивном стиле часто зависят от концепции абстрактной переменной , которую можно рассматривать как простейшую нетривиальную ADT. Абстрактная переменная V является изменяемой сущностью, которая допускает две операции:
с ограничением, что
Как и во многих других языках программирования, операция store( V , x ) часто записывается как V ← x (или некоторые аналогичные обозначения), и fetch( V ) подразумевается всякий раз, когда переменная V используется в контексте, где требуется значение. Так, например, V ← V + 1 обычно понимается как сокращение для store( V , fetch( V ) + 1).
В этом определении неявно предполагается , что сохранение значения в переменную U не оказывает никакого влияния на состояние отдельной переменной V . Чтобы сделать это предположение явным, можно добавить ограничение
В более общем смысле определения ADT часто предполагают, что любая операция, которая изменяет состояние одного экземпляра ADT, не влияет на состояние любого другого экземпляра (включая другие экземпляры того же ADT) - если аксиомы ADT не подразумевают, что два экземпляра связаны ( алиас ) в этом смысле. Например, при расширении определения абстрактных переменным , чтобы включить абстрактные записи , операцию , которая выбирает поле из записи переменной R должны уступить переменную V , которая является псевдонимом к той части R .
Определение абстрактной переменной V также может ограничить сохраненные значения х членов определенного набора X , называется диапазоном или типа из V . Как и в языках программирования, такие ограничения могут упростить описание и анализ алгоритмов и улучшить их читабельность.
Обратите внимание , что это определение ничего не говорит о результате оценки не означает fetch( V ) , когда V является не-инициализирован , то есть, перед выполнением любой storeоперации на V . Алгоритм, который делает это, обычно считается недействительным, потому что его эффект не определен. (Тем не менее, есть некоторые важные алгоритмы, эффективность которых сильно зависит от предположения , что такое fetchзаконно, и возвращают некоторое произвольное значение диапазона переменного. )
Создание экземпляра
Некоторые алгоритмы должны создавать новые экземпляры некоторых ADT (например, новые переменные или новые стеки). Чтобы описать такие алгоритмы, обычно в определение ADT включается createоперация (), которая дает экземпляр ADT, обычно с аксиомами, эквивалентными
Эта аксиома может быть усилена, чтобы исключить также частичное совмещение имен с другими примерами. С другой стороны, эта аксиома все еще позволяет реализациям create() выдавать ранее созданный экземпляр, который стал недоступен для программы.
Пример: абстрактный стек (обязательно)
В качестве другого примера определение абстрактного стека в императивном стиле может указывать, что состояние стека S может быть изменено только операциями
с ограничением, что
Поскольку присваивание V ← x по определению не может изменить состояние S , это условие подразумевает, что V ← pop( S ) восстанавливает S до состояния, которое было до push( S , x ). Из этого условия и свойств абстрактных переменных следует, например, что последовательность
{ push( S , х ); push( S , у ); U ← pop( S ); push( S , Z ); V ← pop( S ); W ← pop( S )}
где x , y и z - любые значения, а U , V , W - попарно различные переменные, эквивалентно
{ U ← y ; V ← z ; W ← x }
Здесь неявно предполагается, что операции с экземпляром стека не изменяют состояние любого другого экземпляра ADT, включая другие стеки; это,
Абстрактное определение стека , как правило , включает в себя также булева -значную функцию empty( S ) и create() операцию , которая возвращает экземпляр стека, с аксиомами , эквивалентными
Стиль одного экземпляра
Иногда ADT определяется, как если бы во время выполнения алгоритма существовал только один его экземпляр, и все операции были применены к этому экземпляру, который явно не записан. Например, абстрактный стек выше , может быть определена с операциями push( х ) и pop(), которые работают на в только существующий стек. Определения ADT в этом стиле можно легко переписать, чтобы допустить несколько сосуществующих экземпляров ADT, добавив явный параметр экземпляра (как S в предыдущем примере) к каждой операции, которая использует или изменяет неявный экземпляр.
С другой стороны, некоторые ADT невозможно определить осмысленно, не принимая несколько экземпляров. Это тот случай, когда одна операция принимает два разных экземпляра ADT в качестве параметров. Например, рассмотрите возможность дополнения определения абстрактного стека операцией compare( S , T ), которая проверяет, содержат ли стеки S и T одинаковые элементы в том же порядке.
Другой способ определить ADT, более близкий к духу функционального программирования , состоит в том, чтобы рассматривать каждое состояние структуры как отдельную сущность. В этом представлении любая операция, которая модифицирует ADT, моделируется как математическая функция, которая принимает старое состояние в качестве аргумента и возвращает новое состояние как часть результата. В отличие от императивных операций, эти функции не имеют побочных эффектов . Следовательно, порядок их оценки не имеет значения, и одна и та же операция, примененная к одним и тем же аргументам (включая одни и те же входные состояния), всегда будет возвращать одинаковые результаты (и выходные состояния).
В функциональном представлении, в частности, нет способа (или необходимости) определить «абстрактную переменную» с семантикой императивных переменных (а именно, с fetchи storeоперациями). Вместо того, чтобы хранить значения в переменных, они передаются в качестве аргументов функциям.
Пример: абстрактный стек (функционал)
Например, полное определение функционального стиля абстрактного стека может использовать три операции:
В определении функционального стиля нет необходимости в createоперации. Действительно, нет понятия «экземпляр стека». Состояния стека можно рассматривать как потенциальные состояния одной структуры стека, а два состояния стека, которые содержат одинаковые значения в одном и том же порядке, считаются идентичными состояниями. Это представление фактически отражает поведение некоторых конкретных реализаций, таких как связанные списки с хэш-минусами .
Вместо create() определение абстрактного стека в функциональном стиле может предполагать существование специального состояния стека, пустого стека , обозначенного специальным символом, таким как Λ или "()"; или определить bottomоперацию (), которая не принимает аргументов и возвращает это специальное состояние стека. Обратите внимание, что аксиомы подразумевают, что
В определении стека в функциональном стиле не требуется emptyпредикат: вместо этого можно проверить, пуст ли стек, проверяя, равен ли он Λ.
Обратите внимание, что эти аксиомы не определяют влияние top( s ) или pop( s ), если только s не является состоянием стека, возвращаемым a push. Поскольку pushстек остается не пустым, эти две операции не определены (следовательно, недействительны), когда s = Λ. С другой стороны, аксиомы (и отсутствие побочных эффектов) подразумевают, что push( s , x ) = push( t , y ) тогда и только тогда, когда x = y и s = t .
Как и в некоторых других разделах математики, принято также предполагать, что состояниями стека являются только те состояния, существование которых можно доказать из аксиом за конечное число шагов. В приведенном выше примере абстрактного стека это правило означает, что каждый стек является конечной последовательностью значений, которая становится пустым стеком (Λ) после конечного числа pops. Сами по себе вышеприведенные аксиомы не исключают существования бесконечных стеков (которые можно popредактировать вечно, каждый раз получая другое состояние) или круговых стеков (которые возвращаются в одно и то же состояние после конечного числа pops). В частности, они не исключают такие состояния s , что pop( s ) = s или push( s ,x ) = s для некоторого x . Однако, поскольку невозможно получить такие состояния стека с помощью данных операций, предполагается, что они «не существуют».
Помимо поведения с точки зрения аксиом, в определение операции ADT также можно включить их алгоритмическую сложность . Александр Степанов , дизайнер стандартной библиотеки шаблонов C ++ , включил гарантии сложности в спецификацию STL, утверждая:
Причиной введения понятия абстрактных типов данных было использование взаимозаменяемых программных модулей. Вы не можете иметь взаимозаменяемые модули, если эти модули не имеют похожее поведение сложности. Если я заменю один модуль другим модулем с таким же функциональным поведением, но с различными компромиссами сложности, пользователь этого кода будет неприятно удивлен. Я мог сказать ему все, что мне нравится, об абстракции данных, и он все еще не хотел бы использовать код. Утверждения сложности должны быть частью интерфейса.
- Александр Степанов
Абстракция дает обещание, что любая реализация ADT имеет определенные свойства и возможности; зная, что это все, что требуется для использования объекта ADT. Пользователю не нужны никакие технические знания о том, как работает реализация для использования ADT. Таким образом, реализация может быть сложной, но при фактическом использовании она будет заключена в простой интерфейс.
Код, который использует объект ADT, не нужно будет редактировать, если изменилась реализация ADT. Поскольку любые изменения в реализации должны по-прежнему соответствовать интерфейсу, и поскольку код, использующий объект ADT, может ссылаться только на свойства и возможности, указанные в интерфейсе, изменения могут быть внесены в реализацию, не требуя каких-либо изменений в коде, где используется ADT. ,
Различные реализации ADT, имеющие все те же свойства и возможности, эквивалентны и могут быть несколько взаимозаменяемы в коде, который использует ADT. Это дает большую гибкость при использовании объектов ADT в различных ситуациях. Например, разные реализации ADT могут быть более эффективными в разных ситуациях; их можно использовать в ситуации, когда они предпочтительнее, что повышает общую эффективность.
Некоторые операции, которые часто указываются для ADT (возможно, под другими именами)
В определениях ADT императивного стиля часто можно найти
freeОперация обычно не актуальны или смысла, так как АТД теоретические сущности , которые не «использовать память». Тем не менее, это может быть необходимо, когда нужно проанализировать хранилище, используемое алгоритмом, который использует ADT. В этом случае нужны дополнительные аксиомы, которые определяют, сколько памяти использует каждый экземпляр ADT, в зависимости от его состояния, и сколько из него возвращается в пул free.
Дополнительная информация: непрозрачный тип данных
Реализация ADT означает предоставление одной процедуры или функции для каждой абстрактной операции. Экземпляры ADT представлены некоторой конкретной структурой данных , которой манипулируют эти процедуры в соответствии со спецификациями ADT.
Обычно существует много способов реализовать один и тот же ADT, используя несколько разных конкретных структур данных. Таким образом, например, абстрактный стек может быть реализован с помощью связанного списка или массива .
Чтобы клиенты не зависели от реализации, ADT часто упаковывается как непрозрачный тип данных в один или несколько модулей , интерфейс которых содержит только сигнатуру (количество и типы параметров и результатов) операций. Реализация модуля, а именно тела процедур и конкретной структуры данных, может быть скрыта от большинства клиентов модуля. Это позволяет изменить реализацию, не затрагивая клиентов. Если реализация выставлена, она известна как прозрачный тип данных.
При реализации ADT каждый экземпляр (в определениях императивного стиля) или каждое состояние (в определениях функционального стиля) обычно представляется каким-либо дескриптором .
Современные объектно-ориентированные языки, такие как C ++ и Java , поддерживают форму абстрактных типов данных. Когда класс используется в качестве типа, это абстрактный тип, который ссылается на скрытое представление. В этой модели ADT обычно реализуется как класс , и каждый экземпляр ADT обычно является объектом этого класса. Интерфейс модуля обычно объявляет конструкторы как обычные процедуры, а большинство других операций ADT - как методыэтого класса. Однако такой подход нелегко инкапсулирует несколько вариантов представления, найденных в ADT. Это также может подорвать расширяемость объектно-ориентированных программ. В чисто объектно-ориентированной программе, которая использует интерфейсы как типы, типы относятся к поведению, а не к представлениям.
В качестве примера здесь является реализацией абстрактного стека выше в языке программирования Си .
Интерфейс императивного стиля
Интерфейс императивного стиля может быть:
typedef struct stack_Rep stack_Rep ; // тип: представление экземпляра стека (непрозрачная запись) typedef stack_Rep * stack_T ; // type: дескриптор экземпляра стека (непрозрачный указатель) typedef void * stack_Item ; // тип: значение хранится в экземпляре стека (произвольный адрес) stack_T stack_create ( void ); // создает новый пустой экземпляр стека void stack_push ( stack_T s , stack_Item x ); // добавляет элемент в начало стека stack_Item stack_pop ( stack_T s ); // удаляет верхний элемент из стека и возвращает его bool stack_empty ( stack_T s ); // проверяет, пуст ли стек
Этот интерфейс может быть использован следующим образом:
#include // включает интерфейс стека
stack_T s = stack_create (); // создаем новый пустой экземпляр стека
int x = 17 ;
stack_push ( s , & x ); // добавляет адрес x вверху стека
void * y = stack_pop ( s ); // удаляет адрес x из стека и возвращает его,
если ( stack_empty ( s )) { } // что-то делает, если стек пуст
Этот интерфейс может быть реализован многими способами. Реализация может быть произвольно неэффективной, поскольку приведенное выше формальное определение ADT не определяет, сколько места может использовать стек, и сколько времени должна занимать каждая операция. Также не указывается, продолжает ли существовать состояние s стека после вызова x ← pop( s ).
На практике формальное определение должно указывать, что пространство пропорционально количеству отправленных и еще не извлеченных элементов; и что каждая из вышеперечисленных операций должна завершаться за постоянное количество времени, независимо от этого числа. Чтобы соответствовать этим дополнительным спецификациям, реализация может использовать связанный список или массив (с динамическим изменением размера) вместе с двумя целыми числами (количество элементов и размер массива).
Интерфейс в функциональном стиле
Определения ADT в функциональном стиле больше подходят для языков функционального программирования и наоборот. Тем не менее, можно предоставить интерфейс в функциональном стиле даже на таком императивном языке, как C. Например:
typedef struct stack_Rep stack_Rep ; // тип: представление состояния стека (непрозрачная запись) typedef stack_Rep * stack_T ; // type: дескриптор состояния стека (непрозрачный указатель) typedef void * stack_Item ; // тип: значение состояния стека (произвольный адрес) stack_T stack_empty ( void ); // возвращает состояние пустого стека stack_T stack_push ( stack_T s , stack_Item x ); // добавляет элемент в начало состояния стека и возвращает результирующее состояние стека stack_T stack_pop ( stack_T s ); // удаляет верхний элемент из состояния стека и возвращает результирующее состояние стека stack_Item stack_top ( stack_T s ); // возвращает верхний элемент состояния стека
Многие современные языки программирования, такие как C ++ и Java, поставляются со стандартными библиотеками, которые реализуют несколько распространенных ADT, таких как перечисленные выше.
Спецификация некоторых языков программирования намеренно расплывчата в отношении представления определенных встроенных типов данных, определяя только те операции, которые могут быть выполнены над ними. Следовательно, эти типы можно рассматривать как «встроенные ADT». Примерами являются массивы во многих языках сценариев, таких как Awk , Lua и Perl , которые можно рассматривать как реализацию абстрактного списка.
Исследование, описанное в статье про абстрактный тип данных, подчеркивает ее значимость в современном мире. Надеюсь, что теперь ты понял что такое абстрактный тип данных, abstract data type, adt, атд, и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Структуры данных
Комментарии
Оставить комментарий
Структуры данных
Термины: Структуры данных