Лекция
Привет, мой друг, тебе интересно узнать все про индексы, тогда с вдохновением прочти до конца. Для того чтобы лучше понимать что такое индексы, индексирование, некластеризованный индекс, кластеризованный индекс, poc-индекс, вторичный индекс, первичный индекс, разреженный индекс, плотный указатель , настоятельно рекомендую прочитать все из категории IBM System R — реляционная СУБД.
Индекс (англ. index) — объект базы данных, создаваемый с целью повышения производительности поиска данных. Таблицы в базе данных могут иметь большое количество строк, которые хранятся в произвольном порядке, и их поиск по заданному критерию путем последовательного просмотра таблицы строка за строкой может занимать много времени. Индекс формируется из значений одного или нескольких столбцов таблицы и указателей на соответствующие строки таблицы и, таким образом, позволяет искать строки, удовлетворяющие критерию поиска. Ускорение работы с использованием индексов достигается в первую очередь за счет того, что индекс имеет структуру, оптимизированную под поиск — например, сбалансированного дерева.
Некоторые СУБД расширяют возможности индексов введением возможности создания индексов по столбцам представлений или индексов по выражениям. Например, индекс может быть создан по выражению upper(last_name) и соответственно будет хранить ссылки, ключом к которым будет значение поля last_name в верхнем регистре. Кроме того,
индексы могут быть объявлены как уникальные и как неуникальные. Уникальный индекс реализует ограничение целостности на таблице, исключая возможность вставки повторяющихся значений.
Как бы не были организованы индексы в конкретной СУБД, их основное назначение состоит в обеспечении эффективного прямого доступа к кортежу отношения по ключу. Обычно индекс определяется для одного отношения, и ключом является значение атрибута (возможно, составного). Если ключом индекса является возможный ключ отношения, то индекс должен обладать свойством уникальности, т.е. не содержать дубликатов ключа. На практике ситуация выглядит обычно противоположно: при объявлении первичного ключа отношения автоматически заводится уникальный индекс, а единственным способом объявления возможного ключа, отличного от первичного, является явное создание уникального индекса. Это связано с тем, что для проверки сохранения свойства уникальности возможного ключа так или иначе требуется индексная поддержка.
Поскольку при выполнении многих операций языкового уровня требуется сортировка отношений в соответствии со значениями некоторых атрибутов, полезным свойством индекса является обеспечение последовательного просмотра кортежей отношения в диапазоне значений ключа в порядке возрастания или убывания значений ключа.
Наконец, одним из способов оптимизации выполнения эквисоединения отношений (наиболее распространенная из числа дорогостоящих операций) является организация так называемых мультииндексов для нескольких отношений, обладающих общими атрибутами. Любой из этих атрибутов (или их набор) может выступать в качестве ключа мультииндекса. Значению ключа сопоставляется набор кортежей всех связанных мультииндексом отношений, значения выделенных атрибутов которых совпадают со значением ключа.
Общей идеей любой организации индекса, поддерживающего прямой доступ по ключу и последовательный просмотр в порядке возрастания или убывания значений ключа является хранение упорядоченного списка значений ключа с привязкой к каждому значению ключа списка идентификаторов кортежей. Одна организация индекса отличается от другой главным образом в способе поиска ключа с заданным значением.
Существует два типа индексов: кластерные и некластерные. При наличии кластерного индекса строки таблицы упорядочены по значению ключа этого индекса. Если в таблице нет кластерного индекса, таблица называется кучей . Некластерный индекс, созданный для такой таблицы, содержит только указатели на записи таблицы. Кластерный индекс может быть только одним для каждой таблицы, но каждая таблица может иметь несколько различных некластерных индексов, каждый из которых определяет свой собственный порядок следования записей.
Индексы могут быть реализованы различными структурами. Наиболее часто употребимы B*-деревья, B+-деревья, B-деревья и хеши.
Данные представлены в произвольном порядке, но логический порядок определяется индексом. Строки данных могут быть распределены по таблице независимо от значения индексированного столбца или выражения. Дерево некластеризованного индекса содержит ключи индекса в отсортированном порядке, причем конечный уровень индекса содержит указатель на запись (страница и номер строки на странице данных в механизмах с организацией страниц; смещение строки в механизмах с файловой организацией ).
В некластеризованном индексе
В таблице базы данных может быть более одного некластеризованного индекса.
Кластеризация изменяет блок данных в определенном порядке в соответствии с индексом, в результате чего данные строк хранятся по порядку. Следовательно, для данной таблицы базы данных можно создать только один кластеризованный индекс. Кластеризованные индексы могут значительно повысить общую скорость поиска, но обычно только тогда, когда к данным осуществляется доступ последовательно в том же или обратном порядке кластеризованного индекса, или когда выбран диапазон элементов.
Поскольку физические записи находятся на диске в таком порядке сортировки, следующий элемент строки в последовательности находится непосредственно перед или после последнего, поэтому требуется меньшее количество операций чтения блока данных. Таким образом, основной функцией кластеризованного индекса является упорядочение строк физических данных в соответствии с индексными блоками, которые на них указывают. Некоторые базы данных разделяют блоки данных и индекса на отдельные файлы, другие помещают два совершенно разных блока данных в один и тот же физический файл (файлы).
Когда несколько баз данных и несколько таблиц объединяются, это называется кластером (не путать с кластеризованным индексом, описанным ранее). Записи для таблиц, совместно использующих значение ключа кластера, должны храниться вместе в одном и том же или соседних блоках данных. Это может улучшить объединение этих таблиц по ключу кластера, поскольку совпадающие записи хранятся вместе, и для их обнаружения требуется меньше операций ввода-вывода. Конфигурация кластера определяет структуру данных в таблицах, которые являются частями кластера. Кластер может быть снабжен индексом B-Tree или хеш-таблицей . Блок данных, в котором хранится запись таблицы, определяется значением ключа кластера.
Порядок, в котором определение индекса определяет столбцы, важен. Можно получить набор идентификаторов строк, используя только первый индексированный столбец. Однако невозможно или неэффективно (в большинстве баз данных) получить набор идентификаторов строк, используя только второй или больший индексированный столбец.
Например, в телефонной книге, организованной сначала по городам, затем по фамилии, а затем по имени, в конкретном городе можно легко извлечь список всех телефонных номеров. Однако было бы очень утомительно найти все номера телефонов для определенной фамилии. Нужно будет искать в разделе каждого города записи с этой фамилией. Некоторые базы данных могут это делать, другие просто не используют индекс.
В примере телефонной книги с составным индексом, созданным для столбцов ( shema, host, ip), если мы выполняем поиск, задавая точные значения для всех трех полей, время поиска будет минимальным, но если мы предоставим значения только для shema и host только, поиск будет использовать только shema поле для получения всех совпавших записей. Затем последовательный поиск проверяет соответствие с host . Итак, чтобы повысить производительность, необходимо убедиться, что индекс создается в порядке следования столбцов поиска.
Последовательность, в которой столбцы представлены в составном индексе, достаточно важна. Дело в том, что получить набор данных по запросу, затрагивающему только первый из проиндексированных столбцов, можно. Однако в большинстве СУБД невозможно или неэффективно получение данных только по второму и далее проиндексированным столбцам (без ограничений на первый столбец).
Например, представим себе телефонный справочник, отсортированный вначале по городу, затем по фамилии, и затем по имени. Если вы знаете город, вы можете легко найти все телефоны этого города. Однако в таком справочнике будет весьма трудоемко найти все телефоны, записанные на определенную фамилию — для этого необходимо посмотреть в секцию каждого города и поискать там нужную фамилию. Некоторые СУБД выполняют эту работу, остальные же просто не используют такой индекс.
Большинство программного обеспечения баз данных включает технологию индексирования, которая позволяет выполнять сублинейный поиск по времени для повышения производительности, поскольку линейный поиск неэффективен для больших баз данных.
Предположим, что база данных содержит N элементов данных, и один из них должен быть извлечен на основе значения одного из полей. Простая реализация извлекает и исследует каждый элемент в соответствии с тестом. Если есть только один совпадающий элемент, это может остановиться, когда он найдет этот единственный элемент, но если есть несколько совпадений, он должен проверить все. Это означает, что количество операций в среднем составляет O (N) или линейное время . Поскольку базы данных могут содержать много объектов, а поиск - обычная операция, часто бывает желательно повысить производительность.
Индекс - это любая структура данных, повышающая производительность поиска. Об этом говорит сайт https://intellect.icu . Для этого используется множество различных структур данных . При проектировании возникают сложные компромиссы, включающие производительность поиска, размер индекса и производительность обновления индекса. Многие конструкции индексов демонстрируют производительность логарифмического ( O (log (N))) поиска, а в некоторых приложениях можно достичь плоской ( O (1)) производительности.
Индексы используются для контроля ограничений базы данных , таких как UNIQUE, EXCLUSION, PRIMARY KEY и FOREIGN KEY . Индекс может быть объявлен как UNIQUE, что создает неявное ограничение для базовой таблицы. Системы баз данных обычно неявно создают индекс для набора столбцов, объявленных PRIMARY KEY, а некоторые из них могут использовать уже существующий индекс для контроля этого ограничения. Многие системы баз данных требуют, чтобы как ссылающиеся, так и ссылочные наборы столбцов в ограничении FOREIGN KEY индексировались, тем самым улучшая производительность вставок, обновлений и удалений для таблиц, участвующих в ограничении.
Некоторые системы баз данных поддерживают ограничение EXCLUSION, которое гарантирует, что для вновь вставленной или обновленной записи определенный предикат не выполняется ни для какой другой записи. Это можно использовать для реализации ограничения UNIQUE (с предикатом равенства) или более сложных ограничений, таких как обеспечение того, чтобы в таблице не сохранялись перекрывающиеся временные диапазоны или пересекающиеся геометрические объекты. Для контроля такого ограничения требуется индекс, поддерживающий быстрый поиск записей, удовлетворяющих предикату.
Индекс растрового изображения - это особый вид индексации, при котором большая часть данных хранится в виде битовых массивов (растровых изображений) и отвечает на большинство запросов, выполняя побитовые логические операции с этими растровыми изображениями. Наиболее часто используемые индексы, такие как деревья B + , наиболее эффективны, если значения, которые они индексируют, не повторяются или повторяются небольшое количество раз. Напротив, растровый индекс разработан для случаев, когда значения переменной очень часто повторяются. Например, поле пола в базе данных клиентов обычно содержит не более трех различных значений: мужской, женский или неизвестный (не регистрируется). Для таких переменных индекс битовой карты может иметь значительное преимущество в производительности по сравнению с обычно используемыми деревьями.
Плотный индекс в базах данных - это файл с парами ключей и указателей для каждой записи в файле данных. Каждый ключ в этом файле связан с определенным указателем на запись в файле отсортированных данных. В кластеризованных индексах с повторяющимися ключами плотный индекс указывает на первую запись с этим ключом.
Разреженный индекс в базах данных - это файл с парами ключей и указателей для каждого блока в файле данных. Каждый ключ в этом файле связан с определенным указателем на блок в файле отсортированных данных. В кластеризованных индексах с повторяющимися ключами разреженный индекс указывает на самый низкий ключ поиска в каждом блоке.Разреженный индекс (англ. sparse index) в базах данных — это файл с последовательностью пар ключей и указателей. Каждый ключ в разреженном индексе, в отличие от плотного индекса, ассоциируется с определенным указателем на блок в сортированном файле данных. Идея использования индексов пришла оттого, что современные базы данных слишком массивны и не помещаются в основную память. Мы обычно делим данные на блоки и размещаем данные в памяти поблочно. Однако поиск записи в БД может занять много времени. С другой стороны, файл индексов или блок индексов намного меньше блока данных и может поместиться в буфере основной памяти, что увеличивает скорость поиска записи. Поскольку ключи отсортированы, можно воспользоваться бинарным поиском. В кластерных индексах с дублированными ключами разреженный индекс указывает на наименьший ключ в каждом блоке.
Индекс с обратным ключом меняет значение ключа на противоположное перед его вводом в индекс. Например, значение 24538 становится в индексе 83542. Изменение значения ключа на обратное особенно полезно для индексирования данных, таких как порядковые номера, где новые значения ключа монотонно увеличиваются.
Первичный индекс содержит ключевые поля таблицы и указатель на неключевые поля таблицы. Первичный индекс создается автоматически при создании таблицы в базе данных.
Он используется для индексации полей, которые не являются ни упорядочивающими, ни ключевыми полями (нет гарантии, что файл организован по ключевому полю или полю первичного ключа). Одна запись индекса для каждого кортежа в файле данных (плотный индекс) содержит значение индексированного атрибута и указатель на блок / запись.
Общие рекомендации по поддержке оконных функций укладываются в концепцию, которую я называю POC — по начальным буквам слов partitioning (секционирование), ordering (упорядочение) и covering (покрытие). Иногда ее называют POCo. Ключами POC-индекса должны быть столбцы оконных секций, за которыми следуют столбцы упорядочения, в конце индекс должен включать остальные столбцы, которые используются в запросах. Это включение можно выполнить с помощью предложения явного включения INCLUDE в некластеризованном индексе или средствами кластеризации самого индекса — в последнем случае в конечные строки нужно включить все столбцы дерева.
В отсутствие POC-индекса в плане появляется итератор Sort, который может создавать серьезную нагрузку, если объем входных данных велик. Сложность сортировки пропорциональна произведению N * LOG(N), которое растет быстрее линейной функции. Это означает, что с ростом числа строк каждая последующая строка стоит дороже, чем предыдущая. Возьмем для примера значения 1000 * LOG(1000) = 3000 и 10000 * LOG(10000) = 40000. Это означает, что при увеличении числа строк на порядок объем работы увеличивается в 13 раз и ситуация ухудшается с увеличением числа строк. В качестве примера посмотрите на следующий запрос:
План этого запроса показан на рисунке:

В данный момент никакого POC-индекса нет. Просмотр кластеризованного индекса выполняется без требования упорядочения (свойство Ordered равно False), после чего для сортировки данных используется дорогой итератор Sort. На моей системе при наличии «горячего» кеша на выполнение этого запроса ушло четыре секунды, при этом результаты отбрасывались. (Чтобы отбросить результаты, в контекстном меню Query Options выберите Grid в разделе Results и установите флажок Discard Results After Execution.) Затем создайте POC-индекс таким кодом:
Как видите, первая часть содержит столбцы оконных секций (в нашем случае actid), за которыми следуют столбцы упорядочения окна (в нашем случае val), а затем указаны остальные столбцы, используемые в запросе (в данном случае tranid). Повторно выполните следующий запрос:
План этого запроса показан на рисунке:

Итератор Sort исчез. План выполняет упорядоченный просмотр POC-индекса, решая задачу упорядочения для итераторов, которые вычисляют результат оконной функции. На этот раз запрос выполнялся две секунды, несмотря на то, что использовался последовательный план, что отличается от предыдущего параллельного плана с сортировкой. В больших наборах разница больше.
Если в запросе присутствуют фильтры равенства, например WHERE col1 = 5 AND col2 = 'ABC' все потребности в фильтрации можно удовлетворить с помощью того же индекса, разместив фильтруемые столбцы первыми в списке ключей индекса. Это можно назвать FPOC-индексом, где FPO соответствует списку ключей, а C — списку включения.
Если в запросе много оконных функций, то если у них одинаковое определение окна, они могут использовать одни и те же упорядоченные данные без необходимости каждый раз добавлять итератор Sort. Заметьте также, что при указании множественных оконных функций с разным упорядочением окон (и, возможно, упорядочением представления), порядок их указания в списке SELECT может влиять на число сортировок, выполняемых в плане.
Для оптимальной производительности запросов индексы обычно создаются на тех столбцах таблицы, которые часто используются в запросах. Для одной таблицы может быть создано несколько индексов. Однако увеличение числа индексов замедляет операции добавления, обновления, удаления строк таблицы, поскольку при этом приходится обновлять сами индексы. Кроме того, индексы занимают дополнительный объем памяти, поэтому перед созданием индекса следует убедиться, что планируемый выигрыш в производительности запросов превысит дополнительную затрату ресурсов компьютера на сопровождение индекса.
Индексы полезны для многих приложений, однако на их использование накладываются ограничения. Возьмем такой запрос SQL:
SELECT first_name FROM people WHERE last_name = 'intellect';
Для выполнения такого запроса без индекса СУБД должна проверить поле last_name в каждой строке таблицы (этот механизм известен как «полный перебор» или «полное сканирование таблицы», в плане может отображаться словом NATURAL). При использовании индекса СУБД просто проходит по B-дереву, пока не найдет запись «intellect». Такой проход требует гораздо меньше ресурсов, чем полный перебор таблицы.
Теперь возьмем такой запрос:
SELECT email_address FROM customers WHERE email_address LIKE '%@intellect.com';
Этот запрос должен нам найти всех клиентов, у которых е-мейл заканчивается на @intellect.com, однако даже если по столбцу email_address есть индекс, СУБД все равно будет использовать полный перебор таблицы. Это связано с тем, что индексы строятся в предположении, что слова/символы идут слева направо. Использование символа подстановки в начале условия поиска исключает для СУБД возможность использования поиска по B-дереву. Эта проблема может быть решена созданием дополнительного индекса по выражению reverse(email_address) и формированием запроса вида:
SELECT email_address FROM customers WHERE reverse(email_address) LIKE reverse('%@intellect.com');
В данном случае символ подстановки окажется в самой правой позиции (office@%), что не исключает использование индекса по reverse(email_address).
Видимо, наиболее популярным подходом к организации индексов в базах данных является использование техники B-деревьев. С точки зрения внешнего логического представления B-дерево - это сбалансированное сильно ветвистое дерево во внешней памяти. Сбалансированность означает, что длина пути от корня дерева к любому его листу одна и та же. Ветвистость дерева - это свойство каждого узла дерева ссылаться но большое число узлов-потомков. С точки зрения физической организации B-дерево представляется как мультисписочная структура страниц внешней памяти, т.е. каждому узлу дерева соответствует блок внешней памяти (страница). Внутренние и листовые страницы обычно имеют разную структуру.
В типовом случае структура внутренней страницы выглядит следующим образом:
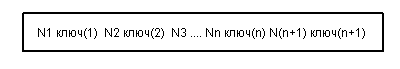
При этом выдерживаются следующие свойства:
Листовая страница обычно имеет следующую структуру:

Листовая страница обладает следующими свойствами:
Поиск в B-дереве - это прохождение от корня к листу в соответствии с заданным значением ключа. Заметим, что поскольку деревья сильно ветвистые и сбалансированные, то для выполнения поиска по любому значению ключа потребуется одно и то же (и обычно небольшое) число обменов с внешней памятью. Более точно, в сбалансированном дереве, где длины всех путей от корня к листу одни и те же, если во внутренней странице помещается n ключей, то при хранении m записей требуется дерево глубиной logn(m), где logn вычисляет логарифм по основанию n. Если n достаточно велико (обычный случай), то глубина дерева невелика, и производится быстрый поиск.
Основной "изюминкой" B-деревьев является автоматическое поддержание свойства сбалансированности. Рассмотрим, как это делается при выполнении операций занесения и удаления записей.
При занесение новой записи выполняется:
При удалении записи выполняются следующие действия:
Как видно, при выполнении операций вставки и удаления свойство сбалансированности B-дерева сохраняется, а внешняя память расходуется достаточно экономно.
Проблемой является то, что при выполнении операций модификации слишком часто могут возникать расщепления и слияния. Чтобы добиться эффективного использования внешней памяти с минимизацией числа расщеплений и слияний, применяются более сложные приемы, в том числе:
Следует заметить, что при организации мультидоступа к B-деревьям, характерного при их использовании в СУБД, приходится решать ряд нетривиальных проблем. Конечно, грубые решения очевидны, например монопольный захват B-дерева на все выполнение операции модификации. Но существуют и более тонкие решения, рассмотрение которых выходит за пределы нашего курса.
И последнее замечание относительно B-деревьев. В литературе вид рассмотренных нами деревьев принято называть B* или B+-деревьями.
Альтернативным и все более популярным подходом к организации индексов является использование техники хэширования. Это очень обширная тема, которая заслуживает отдельного рассмотрения. Мы ограничимся лишь несколькими замечаниями. Общей идеей методов хэширования является применение к значению ключа некоторой функции свертки (хэш-функции), вырабатывающей значение меньшего размера. Свертка значения ключа затем используется для доступа к записи.
В самом простом, классическом случае, свертка ключа используется как адрес в таблице, содержащей ключи и записи. Основным требованием к хэш-функции является равномерное распределение значение свертки. При возникновении коллизий (одна и та же свертка для нескольких значений ключа) образуются цепочки переполнения. Главным ограничением этого метода является фиксированный размер таблицы. Если таблица заполнена слишком сильно или переполнена, но возникнет слишком много цепочек переполнения, и главное преимущество хэширования - доступ к записи почти всегда за одно обращение к таблице - будет утрачено. Расширение таблицы требует ее полной переделки на основе новой хэш-функции (со значением свертки большего размера).
В случае баз данных такие действия являются абсолютно неприемлемыми. Поэтому обычно вводят промежуточные таблицы-справочники, содержащие значения ключей и адреса записей, а сами записи хранятся отдельно. Тогда при переполнении справочника требуется только его переделка, что вызывает меньше накладных расходов.
Чтобы избежать потребности в полной переделки справочников, при их организации часто используют технику B-деревьев с расщеплениями и слияниями. Хэш-функция при этом меняется динамически, в зависимости от глубины B-дерева. Путем дополнительных технических ухищрений удается добиться сохранения порядка записей в соответствии со значениями ключа. В целом методы B-деревьев и хэширования все более сближаются.
Понравилась статья про индексы? Откомментируйте её Надеюсь, что теперь ты понял что такое индексы, индексирование, некластеризованный индекс, кластеризованный индекс, poc-индекс, вторичный индекс, первичный индекс, разреженный индекс, плотный указатель и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории IBM System R — реляционная СУБД
Комментарии
Оставить комментарий
IBM System R — реляционная СУБД
Термины: IBM System R — реляционная СУБД