Лекция
Привет, Вы узнаете о том , что такое метод функциональных точек, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое метод функциональных точек, точки использования, ucp, function points, измерение производительности труда программистов, линейный подход для оценки производительности труда , настоятельно рекомендую прочитать все из категории Управление разработкой программных IT проектов.
Этот метод используется для измерения производительности взамен устаревшего линейного подхода, где производительность измерялась количеством строк программного кода. Впервые функциональные точки (function points) были предложены сотрудником IBM Аланом Альбрехтом в 1979 г. [58].
Преимуществом данного метода является то, что поскольку применение функциональных точек основано на изучении требований, то оценка необходимых трудозатрат может быть выполнена на самых ранних стадиях работы над проектом. Для поддержки и развития данного метода в 1986 г. была создана Международная группа пользователей функционального измерения (IFPUG — International Function Point User Group).
Методы измерения произвоительности труда не ИТ специальностей:
1. Объем производства продукции (работ, услуг):
2. Трудовые затраты:
Однако специфика ИТ професси и отрасли накладывает особенности для определения произвоительности труда программиста.
В простейшем случае определить стоимость разработки ПО можно исходя из количественной оценки трудозатрат Т (в неких единицах, например человеко-месяцах или человеко-часах) и их удельной стоимости Ц:
С = Т × Ц.
Цена одной единицы трудозатрат для индустрии разработки ПО формируется, в основном, исходя из заработной платы и связанных с ней начислений. Как правило, другие составляющие имеют гораздо меньший удельный вес, и ими зачастую можно пренебречь.
Что касается самих трудозатрат, то их достоверное вычисление в сфере интеллектуальной деятельности, к которой, несомненно, относится разработка ПО, выполнить достаточно сложно. Простейший подход может быть основан на следующей линейной формуле:
Т = Р × П,
где Р – размер исходного кода ПО; П – временнаóя производительность.
Эта примитивная формула активно применяется и по сей день, хотя ее несостоятельность была установлена довольно давно. Пожалуй, самой известной работой, в которой критикуется данный подход, является выдержавшая более двадцати изданий по-настоящему классическая книга Фредерика Брукса (Frederick Brooks) «Мифический человеко-месяц, или Как создаются программные системы», впервые увидевшая свет еще в 1977 г.
По мнению Брукса, «…наши методы оценки ошибочно путают достигнутый прогресс с затраченными усилиями…». В первую очередь, это утверждение касается способа, которым измеряется результат, – на заре программирования не было найдено ничего лучшего, чем использование в этих целях количества строк кода. Об абсурдности такого показателя для оценки программного проекта сказано очень много, что, впрочем, вовсе не означает, что он не применяется сегодня.
Продолжать дискуссии на эту тему нет смысла, достаточно лишь уяснить, что с ростом мастерства программист обычно делается «лаконичнее», т. е. выдаваемый им код для решения одних и тех же задач становится все компактнее, а это означает, что его проще и дешевле отлаживать и сопровождать. Однако вышеуказанная формула вовсе не стимулирует данного процесса…
В одной из своих мини-статей Джоэль Спольски (Joel Spolsky) – бывший менеджер команды разработчиков Microsoft Excel, автор нескольких книг по созданию ПО, основатель и бессменный руководитель компании Fog Creek Software – удачно подметил, что софтверные организации склонны вознаграждать программистов, которые: а) пишут много кода; б) исправляют много ошибок. Соответственно, наилучший способ отличиться в таких условиях – это создать большое количество некачественного кода, а потом героически устранять в нем собственные же промахи.
Подобное отношение со стороны персонала, а нередко и руководства, только способствует признанию ее несостоятельной – вместо совершенствования и поиска более эффективных альтернатив. Чаще всего это приводит к полному отказу от применения научного подхода: по данным Software Engineering Institute (SEI), около 80% всех внедренных систем количественной оценки процесса разработки ПО оказываются практически невостребованными на протяжении первых двух лет.
Для устранения этого недостатка были предложены методики на основе так называемых функциональных точек.
Метод функциональных точек заключается в следующем.
Сначала выделяются функции разрабатываемого программного обеспечения, причем на уровне пользователей, а не программного кода. Например, рассмотрим программный комплекс, реализующий различные методы сортировки одномерных массивов. Одной из функций пользователя данного комплекса будет выбор метода, ее мы и будем описывать в качестве примера [61].
Следующим шагом метода будет подсчет количества факторов, приведенных ниже:
• внешние входы. Различаются только те входы, которые по-разному влияют на функцию. Функция выбор метода имеет один внешний вход;
• внешние выходы. Различными считаются выходы для различных алгоритмов. Представим, что наша функция выдает сообщение — текстовое описание выбранного метода, и вызывает другую функцию, непосредственно реализующую выбранный алгоритм сортировки, следовательно, она имеет два выхода;
• внешние запросы. В нашем примере таковых нет;
• внутренние логические файлы — группа данных, которая создается или поддерживается функцией, считается за единицу. В качестве внутреннего логического файла для нашей функции примем текстовый файл, содержащий описания алгоритмов;
• внешние логические файлы — пользовательские данные, находящиеся во внешних по отношению к данной функции файлах. Каждая группа данных принимается за единицу. Внешним по отношению к нашей функции является файл с результатом обработки.
Далее полученные значения умножаются на коэффициенты сложности для каждого фактора (по данным 1РР1Ю) и суммируются для получения полного размера программного продукта. Значения этих коэффициентов приведены в табл. 9.1.
Таблица 9.1. Значения коэффициентов сложности
|
Параметр |
Просто |
Средне |
Сложно |
|
Внешние входы |
3 |
4 |
6 |
|
Внешние выходы |
4 |
5 |
7 |
|
Внешние запросы |
3 |
4 |
6 |
|
Внутренние логические файлы |
7 |
10 |
15 |
|
Внешние логические файлы |
5 |
7 |
10 |
Для рассматриваемого нами примера возьмем значения, приведенные в табл. 9.2.
Размер нашей функции составит:
ФР =1хЗ+1х4+1х5+1х7+1х7 = 26.
Это число является предварительной оценкой и нуждается в уточнении.
Таблица 9.2. Пример коэффициентов сложности
|
Параметр |
Просто |
Средне |
Сложно |
|||
|
Количе ство |
Коэф фициент |
Количе ство |
Коэф фициент |
Количе ство |
Коэф фициент |
|
|
Внешние входы |
1 |
3 |
0 |
4 |
0 |
6 |
|
Внешние выходы |
1 |
4 |
1 |
5 |
0 |
7 |
|
Внешние запросы |
0 |
3 |
0 |
4 |
0 |
6 |
|
Внутренние логические файлы |
1 |
7 |
0 |
10 |
0 |
15 |
|
Внешние логические файлы |
0 |
5 |
1 |
7 |
0 |
10 |
Следующим шагом в определении размера программного кода методом функциональных точек является присвоение веса (от 0 до 5) каждой характеристике проекта. Перечислим эти характеристики:
1. Требуется ли резервное копирование данных?
2. Требуется обмен данными?
3. Используются распределенные вычисления?
4. Важна ли производительность?
5. Программа выполняется на сильно загруженном оборудовании?
6. Требуется ли оперативный ввод данных?
7. Используется много форм для ввода данных?
8. Поля базы данных обновляются оперативно?
9. Ввод, вывод, запросы являются сложными?
10. Внутренние вычисления сложны?
11. Код предназначен для повторного использования?
12. Требуется преобразование данных и установка программы?
13. Требуется много установок в различных организациях?
14. Требуется поддерживать возможность настройки и простоту использования?
Значения для данных характеристик определяются следующим образом: 0 — никогда; 1 — иногда; 2 — редко; 3 — средне; 4 — часто; 5 — всегда.
Эти характеристики для примера функции сведены в табл. 9.3.
Таблица 9.3. Пример характеристик проектов
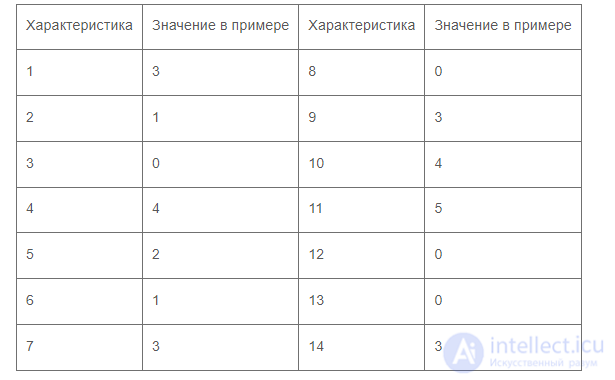
Определяется 5 — сумма всех весов.
И наконец, уточненный функциональный размер вычисляется по формуле
УФР = ФР X (0,65 + 0,01 X 5). (9.3)
Уточненный функциональный размер функции выбор метода будет следующим:
УФР = 26 х (0,65 + 0,01 х 29)= 17,19.
Получившийся результат показывает, что функция выбор метода достаточно проста и не требует больших трудозатрат. Полученные значения затем используются для оценки стоимости проекта.
В настоящее время существует несколько модификаций метода функциональных точек [57].
Точки свойств
В случае, если вышеописанные характеристики не отражают истинной сложности реализации (например, при разработке операционных систем), вместо метода функциональных точек применяют его усовершенствованный вариант, предложенный в 1988 г. Кейперсом Джонсом, — метод точек свойств. Этот метод корректирует оценки, полученные методом функциональных точек с учетом алгоритмической сложности программного продукта.
Метод Mark II
Метод Mark II был представлен Чарльзом Саймонсом также в 1988 г. Этот метод более пригоден для оценки сложных систем, чем классический метод функциональных точек. Он позволяет добиться одного и того же результата как при оценке системы в целом, так и при суммировании оценок, полученных для составляющих ее подсистем.
Трехмерные функциональные точки
В 1991 г. софтверным подразделением корпорации Boeing было предложено еще одно решение — метод трехмерных функциональных точек. Отличием от классического метода является то, что сложность программного продукта оценивается по трем направлениям — данные, функции и управление. Достоинством метода является его применимость не только к оценке программных проектов, но и к оценке трудоемкости задач в других сферах деятельности.
Объектные точки
Метод объектных точек адаптирует оригинальный метод функциональных точек к объектно-ориентированной технологии программирования.
Обзор метода функциональных точек
Анализ функциональных точек — стандартный метод измерения размера программного продукта с точки зрения пользователей системы. Метод разработан Аланом Альбрехтом (Alan Albrecht) в середине 70-х. Метод был впервые опубликован в 1979 году. В 1986 году была сформирована Международная Ассоциация Пользователей Функциональных Точек (International Function Point User Group — IFPUG), которая опубликовала несколько ревизий метода .
Метод предназначен для оценки на основе логической модели объема программного продукта количеством функционала, востребованного заказчиком и поставляемого разработчиком. Несомненным достоинством метода является то, что измерения не зависят от технологической платформы, на которой будет разрабатываться продукт, и он обеспечивает единообразный подход к оценке всех проектов в компании.
При анализе методом функциональных точек надо выполнить следующую последовательность шагов (Рисунок 37):
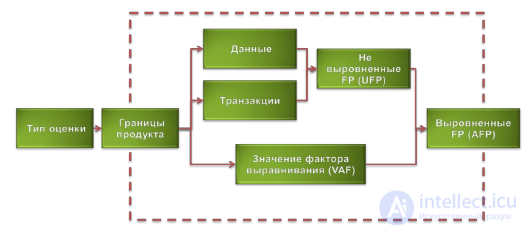
Рисунок 37. Процедура анализа по методу функциональных точек
Определение типа оценки
Первое, что необходимо сделать, это определить тип выполняемой оценки. Метод предусматривает оценки трех типов:
Определение области оценки и границ продукта
Второй шаг — это определение области оценки и границ продукта. В зависимости от типа область оценки может включать:
Третий шаг. Границы продукта (Рисунок 38) определяют:

Рисунок 38. Границы продукта в методе функциональных точек
К логическим данным системы относятся:
Примером логических данных (информационных объектов) могут служить: клиент, счет, тарифный план, услуга.
Подсчет функциональных точек, связанных с данными
Третий шаг — подсчет функциональных точек, связанных с данными. Сначала определяется сложность данных по следующим показателям:
Оценка количества не выровненных функциональных точек, зависит от сложности данных, которая определяется на основании матрицы сложности (Таблица 7).
Таблица 7. Матрица сложности данных
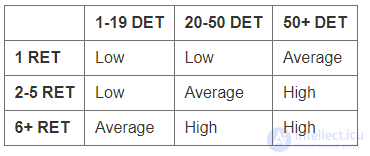
Оценка данных в не выровненных функциональных точках (UFP) подсчитывается по-разному для внутренних логических файлов (ILFs) и для внешних интерфейсных файлов (EIFs) (Таблица 8) в зависимости от их сложности.
Таблица 8. Оценка данных в не выровненных функциональных точках (UFP) для внутренних логических файлов (ILFs) и внешних интерфейсных файлов (EIFs)

Для иллюстрации рассмотрим пример оценки в не выровненных функциональных точках объекта данных «Клиент» (Рисунок 39).

Рисунок 39. Пример оценки в не выровненных функциональных точках объекта данных «Клиент».
Объект «Клиент» содержит четыре логических группы данных, которые в совокупности состоят из 15 неповторяемых уникальное полей данных. Согласно матрице (Таблица 7), нам следует оценить сложность этого объекта данных, как «Low». Теперь, если оцениваемый объект относится к внутренним логическим файлам, то согласно Таблица 8 его сложность будет 7 не выровненных функциональных точек (UPF). Если же объект является внешним интерфейсным файлом, то его сложность составит 5 UPF.
Подсчет функциональных точек, связанных с транзакциями
Подсчет функциональных точек, связанных с транзакциями — это четвертый шаг анализа по методу функциональных точек.
Транзакция — это элементарный неделимый замкнутый процесс, представляющий значение для пользователя и переводящий продукт из одного консистентного состояния в другое.
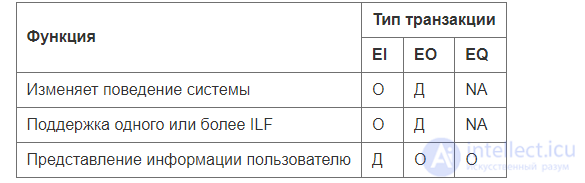
В методе различаются следующие типы транзакций (Таблица 9):
Таблица 9. Об этом говорит сайт https://intellect.icu . Основные отличия между типами транзакций. Легенда: О — основная; Д — дополнительная; NA — не применима.
Оценка сложности транзакции основывается на следующих ее характеристиках:
Для оценки сложности транзакций служат матрицы, которые представлены в Таблица 10 и Таблица 11.
Таблица 10. Матрица сложности внешних входных транзакций (EI)
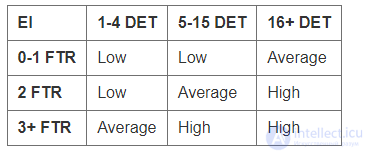
Таблица 11. Матрица сложности внешних выходных транзакций и внешних запросов (EO & EQ)
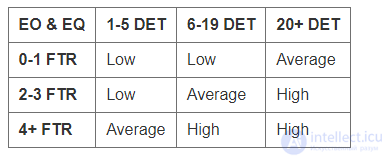
Оценка транзакций в не выровненных функциональных точках (UFP) может быть получена из матрицы (Таблица 12)
Таблица 12. Сложность транзакций в не выровненных функциональных точках (UFP)

В качестве примера, рассмотрим оценку управляющей транзакции (EI) для диалогового окна, задающего параметры проверки орфографии в MS Office Outlook (Рисунок 40).
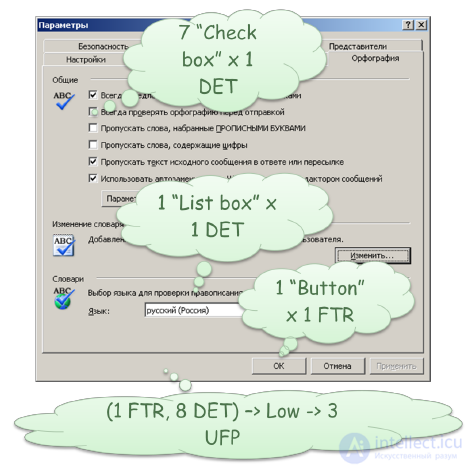
Рисунок 40. Диалоговое окно, управляющее проверкой орфографии в MS Office Outlook
Каждый "Check box" оценивается, как 1 DET. Выпадающий список — 1 DET. Каждая управляющая кнопка должна рассматриваться как отдельная транзакция. Например, если оценивать управляющую транзакцию по кнопке «OK», то, для данной транзакции мы имеем 1 FTR и 8 DET. Поэтому, согласно матрице (Таблица 10), мы можем оценить сложность транзакции, как Low. И, наконец, в соответствие с матрицей (Таблица 12), данная транзакция должна быть оценена в 3 не выровненных функциональных точек (UFP).
Определение суммарного количества не выровненных функциональных точек (UFP)
Общий объем продукта в не выровненных функциональных точках (UFP) определяется путем суммирования по всем информационным объектам (ILF, EIF) и элементарным операциям (транзакциям EI, EO, EQ).
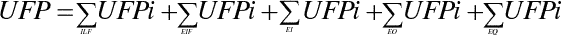
Определение значения фактора выравнивания (FAV)
Помимо функциональных требований на продукт накладываются общесистемные требования, которые ограничивают разработчиков в выборе решения и увеличивают сложность разработки. Для учета этой сложности применяется фактор выравнивания (VAF). Значение фактора VAF зависит от 14 параметров, которые определяют системные характеристики продукта:
14 системных параметров (degree of influence, DI) оцениваются по шкале от 0 до 5. Расчет суммарного эффекта 14 системных характеристик (total degree of influence, TDI) осуществляется простым суммированием:
TDI = ∑ DI
Расчет значения фактора выравнивания производится по формуле
VAF = (TDI *0.01) + 0.65
Например, если, каждый из 14 системных параметров получил оценку 3, то их суммарный эффект составит TDI = 3 * 14 = 42. В этом случае значение фактора выравнивания будет: VAF = (42 * 0.01) + 0.65 = 1.07
Расчет количества вьровненных функциональных точек (AFP)
Дальнейшая оценка в выровненных функциональных точках зависит от типа оценки. Начальное оценка количества выровненных функциональных точек для программного приложения определяется по следующей формуле:
AFP = UFP * VAF.
Она учитывает только новую функциональностсть, которая реализуется в продукте. Проект разработки продукта оценивается в DFP (development functional point) по формуле:
DFP = (UFP + CFP) * VAF,
где CFP (conversion functional point) — функциональные точки, подсчитанные для дополнительной функциональности, которая потребуется при установке продукта, например, миграции данных.
Проект доработки и совершенствования продукта оценивается в EFP (enhancement functional point) по формуле:
EFP = (ADD + CHGA + CFP) * VAFA + (DEL* VAFB),
где
Суммарное влияние процедуры выравнивания лежит в пределах ±35% относительно объема рассчитанного в UFP.
Метод анализа функциональных точек ничего не говорит о трудоемкости разработки оцененного продукта. Вопрос решается просто, если компания разработчик имеет собственную статистику трудозатрат на реализацию функциональных точек. Если такой статистики нет, то для оценки трудоемкости и сроков проекта можно использовать метод COCOMO II.
Наверное, наиболее удачной заменой количеству строк кода для измерения производительности стали функциональные точки (function points), впервые предложенные сотрудником IBM Аланом Альбрехтом (Allan Albrecht) в 1979 г. Данный подход имеет преимущества: поскольку применение функциональных точек основано на изучении требований, то оценка необходимых трудозатрат может быть выполнена на самых ранних стадиях работы над проектом и далее будет уточняться по ходу жизненного цикла, а явная связь между требованиями к создаваемой системе и получаемой оценкой позволяет заказчику понять, за что именно он платит, и во что выльется изменение первоначального задания.
Постепенно метод функциональных точек превратился в индустриальный стандарт, и в 1986 г. для его поддержки и развития была создана некоммерческая организация IFPUG (International Function Point User Group). Кроме того, он послужил основой для множества производных подходов.
Точки свойств. В условиях, когда сформулированные требования не отражают истинной сложности реализации (что особенно характерно для системного ПО, критически важных программных комплексов и пр.), метод функциональных точек себя не оправдывает. В этом случае на помощь приходит его модифицированный вариант, предложенный в 1988 г. Кейперсом Джонсом (Capers Jones), который учитывает не только требования к системе, но и внутренние особенности ее реализации – метод точек свойств (feature points). Он очень близок к методу функциональных точек, с тем лишь отличием, что предусматривает корректирование получаемой оценки с учетом алгоритмической сложности.
Метод Mark II. Еще одна примечательная модификация метода функциональных точек, представленная Чарльзом Саймонсом (Charles Symons) также в 1988 г. Автор стремился избавиться от многих известных его недостатков и сделать более пригодным для оценки сложных систем. В частности, Mark II позволяет добиться одного и того же результата как при оценке системы в целом, так и при суммировании оценок, полученных для составляющих ее подсистем.
Трехмерные функциональные точки. Еще одно логическое развитие оригинального подхода было предложено софтверным подразделением корпорации Boeing в 1991 г. В основу этого метода положена идея о том, что сложность задачи в программной среде можно представить в трех измерениях – данные (количество вводов/выводов), функции (сложность вычислений) и контроль (управляющая логика). Важно отметить, что он выходит за рамки исключительно программных проектов и позволяет оценивать трудоемкость решения задач в различных сферах – деловой, научной и т. д.
Объектные точки. Поскольку классическая интерпретация метода функциональных точек не предусматривает применения объектно-ориентированного подхода, в современных проектах используется его адаптированный вариант, оперирующий именно терминами ОО-технологии.
Несмотря на определенные достижения рассмотренных методов при оценке трудоемкости реализации программных проектов, опытный менеджер скажет, что лучший способ узнать длину пути – это пройти его. Действительно, ничто не вселяет в нас больше уверенности, чем прошлый опыт.
Wideband Delphi. Широко используемая в классическом менеджменте технология экспертной оценки по методу Delphi, созданная в Rand Corporation еще в 1966 г., нашла свое применение и в программных проектах. Часто используемая в софтверной индустрии его вариация получила название Wideband Delphi и отличается от традиционных «дельфийских» оценок ускоренной процедурой выработки решения.
Несмотря на то что экспертные оценки могут приводить к хорошим результатам при относительно невысоких затратах, их применение лежит больше в интуитивной, чем в научной плоскости, а потому не всегда способствует повышению прозрачности процесса принятия решений. Однако использование прошлого опыта вовсе не подразумевает отказа от применения математических выкладок в пользу интуиции профессионалов, скорее даже наоборот: в большинстве современных методов оценки стоимости разработки ПО с привлечением эмпирических данных используется адаптация параметрических моделей.
Метод ДеМарко. Относительно простой, но эффективный подход к оценке стоимости ПО на основе накопленного опыта был разработан Томом ДеМарко (Tom DeMarco) в 1982 г. Основан он на использовании так называемой «бэнг-метрики» (Bang Metric), близкой по своему содержанию к функциональным точкам. Но главная его особенность состоит в том, что оценки корректируются с учетом хронологических данных по выполненным ранее проектам, что позволяет получить не абстрактные показатели, а приближенные значения реальных затрат ресурсов и времени. Последовательное и систематическое применение данного метода позволяет постепенно повышать точность оценок и добиваться очень хороших результатов.
SLIM. Вернемся к нашей линейной формуле определения трудозатрат – как мы уже говорили, она была признана несостоятельной, но если ранее мы сомневались только в способе исчисления размера ПО, то теперь задумаемся о ее линейном характере.
О том, что трудоемкость и, соответственно, стоимость программного проекта нелинейно зависит от объема работ, было известно еще в 1970-х годах, когда появились первые научные публикации, подкрепленные результатами серьезных исследований.
Вероятно, первой нелинейной моделью, использующей эмпирические данные и нашедшей практическое применение при оценке стоимости ПО, стала SLIM (Software Life-cycle Model), предложенная в 1978 г. Лоуренсом Патнамом (Lawrence Putnam). Согласно ей трудоемкость вычисляется по следующей формуле:
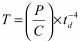
Размер проекта (P) чаще всего исчисляется в количестве строк кода, хотя известны случаи успешного применения модели и для других единиц, например функциональных точек. C – фактор среды, некая технологическая константа, учитывающая, помимо уровня технологий, также и производительность персонала, которая может различаться от команд к команде. td – ограничение на срок поставки (в годах).
SLIM была создана на базе реальных данных, собранных в Министерстве обороны США, и ориентирована в первую очередь на крупные проекты. Несмотря на возможность калибровки модели на основе хронологической информации, что несколько повышает качество результатов, она не приобрела широкой популярности, хотя существуют организации, успешно использующие ее в проектном менеджменте и сегодня (qsm.com).
COCOMO. Пожалуй, самой популярной моделью для оценки стоимости разработки ПО, которая де-факто стала стандартом, является COCOMO (COnstructive COst MOdel). Она была представлена в 1981 г. Барри Боэмом (Barry Boehm), известным ученым, внесшим огромный вклад в развитие научных подходов к управлению программными проектами – им разработаны спиральная модель проектирования ПО и Wideband Delphi, кроме того, когда-то именно он предсказал, что в будущем стоимость ПО превысит стоимость оборудования.
COCOMO создана на основе анализа статистических данных 63 проектов различных типов. Фактически под общим названием скрываются три уровня детализации: базовый, промежуточный и подробный. Также предусмотрено три режима использования модели в зависимости от размеров команды и проекта (табл. 1).
| Название режима | Размер проекта | Описание |
| Органичный | До 50 KLOC |
Некрупный проект разрабатывается небольшой командой, для которой нехарактерны нововведения, и среда остается стабильной |
| Сблокированный | 50–300 KLOC |
Относительно небольшая команда занимается проектом среднего размера, в процессе разработки необходимы определенные инновации, среда характеризуется незначительной нестабильностью |
| Внедренный | Более 300 KLOC |
Большая команда разработчиков трудится над крупным проектом, необходим значительный объем инноваций, среда состоит из множества элементов, которые не характеризуются стабильностью |
Для оценки трудозатрат на базовом уровне модели COCOMO применяется следующая формула:
Т = a × Р b,
где a и b – константы, которые зависят от режима использования модели.
В соответствии с этой формулой трудозатраты вообще нелинейно зависят от размера проекта и скачкообразно изменяются при смене режима (табл. 2). Другая интересная особенность COCOMO – рост трудозатрат при переходе к более высокому режиму не означает безусловного увеличения длительности (F) выполнения проекта, которая вычисляется по формуле:
F = 2,5 × Т k,
поскольку при этом изменяется значение константы k.
| Название режима | Значение коэффициента a | Значение коэффициента b | Значение коэффициента k |
| Органичный | 2,4 | 1,05 | 0,38 |
| Сблокированный | 3,0 | 1,12 | 0,35 |
| Внедренный | 3,6 | 1,20 | 0,32 |
На более высоких уровнях COCOMO рассмотренные формулы усложняются, они обрастают дополнительными коэффициентами, позволяющими повысить точность оценок. Также модель допускает калибровку на основе хронологических данных по выполненным проектам.
COCOMO II. Сегодня оригинальная COCOMO уже считается устаревшей, ей на смену пришла COCOMO II, представленная в 1997 г. Хотя она и имеет много общего со своей предшественницей, однако во многом основана на новых идеях, а также адаптирована к современным методологиям разработки ПО (в частности, если COCOMO подразумевала только каскадную модель жизненного цикла, то COCOMO II также пригодна для спиральной и итеративной).
При построении COCOMO II для обработки статистических данных использовался Байесовский анализ, который дает лучшие результаты для программных проектов, характеризующихся неполнотой и неоднозначностью, в отличие от многофакторного регрессионного, примененного в COCOMO. Также в ней допускается измерять размер проекта не только числом строк кода, но и более современными функциональными и объектными точками. Помимо прочего, при расчете показателей COCOMO II учитывает уровень зрелости процесса разработки в соответствии с моделями SEI CMM/CMMI.
Как и COCOMO, COCOMO II также имеет несколько вариантов использования, однако они отличаются не столько детализацией, сколько характером – фактически это разные модели для решения разных (хотя и схожих) задач, объединенные под одним общим названием (табл. 3). При этом формулы для вычисления различных показателей значительно усложнились, и мы не будем их здесь приводить, отметим лишь, что при сохранении основных принципов модель стала намного гибче и учитывает гораздо большее число факторов, влияющих на выполнение программного проекта.
| Название модели | Описание |
| Композиционная прикладная |
Ориентирована на проекты, создаваемые с применением современных инструментальных средств и UML, использует в качестве метрики объектные точки |
| Ранней разработки проекта |
Применяется для получения приближенных оценок по проекту до определения его архитектуры, использует в качестве метрик количество строк кода или функциональные точки |
| Постархитектурная модель |
Наиболее детализированная модель, используется после разработки архитектуры проекта и позволяет получить самые точные оценки, применяет в качестве метрик количество строк кода или функциональные точки |
Вариант использования — это серия взаимосвязанных взаимодействий между пользователем и системой, которая позволяет пользователю достичь цели.
Варианты использования — это способ отразить функциональные требования системы. Пользователь системы называется «Актер». Варианты использования в основном в текстовой форме.
Точки использования (UCP) — это метод оценки программного обеспечения, используемый для измерения размера программного обеспечения с использованием вариантов использования. Концепция UCP похожа на FP.
Количество UCP в проекте основано на следующем:
Различные нефункциональные требования (такие как переносимость, производительность, ремонтопригодность), которые не записаны как варианты использования.
Среда, в которой будет развиваться проект (например, язык, мотивация команды и т. Д.)
Различные нефункциональные требования (такие как переносимость, производительность, ремонтопригодность), которые не записаны как варианты использования.
Среда, в которой будет развиваться проект (например, язык, мотивация команды и т. Д.)
Оценка с использованием UCP требует, чтобы все варианты использования были написаны с целью и примерно на одном уровне, давая одинаковое количество деталей. Следовательно, перед оценкой команда проекта должна убедиться, что они написали свои варианты использования с определенными целями и на детальном уровне. Вариант использования обычно завершается в течение одного сеанса, и после достижения цели пользователь может перейти к какому-либо другому действию.
Метод оценки Точки Использования был введен Густавом Карнером в 1993 году. Позднее работа была лицензирована Rational Software, которая слилась с IBM.
Процесс подсчета баллов прецедентов состоит из следующих этапов:
Сначала вы вычисляете нескорректированные баллы прецедентов, выполнив следующие шаги:
Шаг 1.1. Определите нескорректированный вес варианта использования.
Шаг 1.1.1 — Найти количество транзакций в каждом сценарии использования.
Если варианты использования записаны с уровнями целей пользователя, транзакция эквивалентна шагу в сценарии использования. Найдите количество транзакций, посчитав шаги в прецеденте.
Шаг 1.1.2. Классифицируйте каждый вариант использования как простой, средний или сложный на основе количества транзакций в сценарии использования. Кроме того, присвойте Вес варианта использования, как показано в следующей таблице —
| Сложность варианта использования | Количество транзакций | Вес прецедента |
|---|---|---|
| просто | ≤3 | 5 |
| Средний | 4 до 7 | 10 |
| Сложный | > 7 | 15 |
Шаг 1.1.3 — Повторите для каждого варианта использования и получите все веса вариантов использования. Нескорректированный вес варианта использования (UUCW) представляет собой сумму всех весов варианта использования.
Шаг 1.1.4 — Найти нескорректированный вес варианта использования (UUCW), используя следующую таблицу —
| Сложность варианта использования | Вес прецедента | Количество вариантов использования | Товар |
|---|---|---|---|
| просто | 5 | NSUC | 5 × NSUC |
| Средний | 10 | NAUC | 10 × НАУК |
| Сложный | 15 | NCUC | 15 × NCUC |
| Нескорректированный вес варианта использования (UUCW) | 5 × NSUC + 10 × NAUC + 15 × NCUC | ||
Куда,
NSUC это нет. простых случаев использования.
НАУК это нет. средних случаев использования.
NCUC это нет. комплексных вариантов использования.
Шаг 1.2 — Определите нескорректированный вес актера.
Актором в прецеденте может быть человек, другая программа и т. Д. Некоторые действующие лица, такие как система с определенным API, имеют очень простые потребности и лишь незначительно увеличивают сложность прецедента.
Некоторые участники, такие как система, взаимодействующая через протокол, имеют больше потребностей и в определенной степени увеличивают сложность варианта использования.
Другие субъекты, такие как пользователь, взаимодействующий через GUI, оказывают значительное влияние на сложность варианта использования. Основываясь на этих различиях, вы можете классифицировать актеров как простых, средних и сложных.
Шаг 1.2.1 — Классифицировать актеров как простых, средних и сложных и назначить веса актеров, как показано в следующей таблице —
| Актер Сложность | пример | Актер Вес |
|---|---|---|
| просто | Система с определенным API | 1 |
| Средний | Система, взаимодействующая через протокол | 2 |
| Сложный | Пользователь, взаимодействующий через GUI | 3 |
Шаг 1.2.2 — Повторите для каждого актера и получите все веса актеров. Нескорректированный вес актера (UAW) — это сумма всех весов актера.
Шаг 1.2.3 — Найти нескорректированный вес актера (UAW), используя следующую таблицу —
| Актер Сложность | Актер Вес | Количество актеров | Товар |
|---|---|---|---|
| просто | 1 | NSA | 1 × АНБ |
| Средний | 2 | NAA | 2 × NAA |
| Сложный | 3 | NCA | 3 × NCA |
| Масса актера без корректировки (UAW) | 1 × АНБ + 2 × НАА + 3 × НКА | ||
Куда,
АНБ нет. простых актеров.
NAA это нет. средних актеров.
NCA это нет. комплексных актеров.
Шаг 1.3 — Расчет нескорректированных точек использования.
Нескорректированный вес прецедента (UUCW) и нескорректированный вес актера (UAW) вместе дают нескорректированный размер системы, называемый нескорректированными точками прецедента.
Нескорректированные точки использования (UUCP) = UUCW + UAW
Следующие шаги должны отрегулировать нескорректированные точки использования (UUCP) для технической сложности и экологической сложности.
Шаг 2.1. Рассмотрим 13 факторов, которые способствуют влиянию технической сложности проекта на точки использования и соответствующие им веса, как указано в следующей таблице.
| фактор | Описание | Вес |
|---|---|---|
| T1 | Распределенная Система | 2,0 |
| T2 | Время отклика или показатели производительности | 1,0 |
| T3 | Эффективность конечного пользователя | 1,0 |
| T4 | Комплексная внутренняя обработка | 1,0 |
| T5 | Код должен быть многоразовым | 1,0 |
| T6 | Прост в установке | 0,5 |
| T7 | Легко использовать | 0,5 |
| T8 | портативный | 2,0 |
| T9 | Легко изменить | 1,0 |
| T10 | параллельный | 1,0 |
| T11 | Включает в себя специальные цели безопасности | 1,0 |
| T12 | Предоставляет прямой доступ третьим лицам | 1,0 |
| T13 | Требуются специальные средства обучения пользователей | 1,0 |
Многие из этих факторов представляют нефункциональные требования проекта.
Шаг 2.2 — Для каждого из 13 факторов оцените проект и оцените его от 0 (не имеет значения) до 5 (очень важно).
Шаг 2.3 — Рассчитать влияние фактора из ударного веса фактора и номинального значения для проекта как
Влияние фактора = ударный вес × номинальное значение
Шаг (2.4) — Рассчитать сумму воздействия всех факторов. Это дает общий технический коэффициент (TFactor), как указано в таблице ниже —
| фактор | Описание | Вес (Вт) | Номинальная стоимость (от 0 до 5) (RV) | Воздействие (I = W × RV) |
|---|---|---|---|---|
| T1 | Распределенная Система | 2,0 | ||
| T2 | Время отклика или показатели производительности | 1,0 | ||
| T3 | Эффективность конечного пользователя | 1,0 | ||
| T4 | Комплексная внутренняя обработка | 1,0 | ||
| T5 | Код должен быть многоразовым | 1,0 | ||
| T6 | Прост в установке | 0,5 | ||
| T7 | Легко использовать | 0,5 | ||
| T8 | портативный | 2,0 | ||
| T9 | Легко изменить | 1,0 | ||
| T10 | параллельный | 1,0 | ||
| T11 | Включает в себя специальные цели безопасности | 1,0 | ||
| T12 | Предоставляет прямой доступ третьим лицам | 1,0 | ||
| T13 | Требуются специальные средства обучения пользователей | 1,0 | ||
| Общий технический фактор (TFactor) | ||||
Шаг 2.5 — Рассчитать коэффициент технической сложности (TCF) как —
TCF = 0,6 + (0,01 × TFactor)
Шаг 3.1. Рассмотрим 8 факторов окружающей среды, которые могут повлиять на выполнение проекта, и их соответствующие веса, приведенные в следующей таблице.
| фактор | Описание | Вес |
|---|---|---|
| F1 | Знаком с моделью проекта, которая используется | 1,5 |
| F2 | Опыт применения | 0,5 |
| F3 | Объектно-ориентированный опыт | 1,0 |
| F4 | Возможность ведущего аналитика | 0,5 |
| F5 | мотивация | 1,0 |
| F6 | Стабильные требования | 2,0 |
| F7 | Частичная занятость | -1,0 |
| F8 | Сложный язык программирования | -1,0 |
Шаг 3.2 — Для каждого из 8 факторов оцените проект и оцените его от 0 (не имеет значения) до 5 (очень важно).
Шаг 3.3. Рассчитать влияние фактора из ударного веса фактора и номинального значения для проекта как
Влияние фактора = ударный вес × номинальное значение
Шаг 3.4 — Рассчитайте сумму воздействия всех факторов. Это дает общий фактор среды (EFactor), как указано в следующей таблице:
| фактор | Описание | Вес (Вт) | Номинальная стоимость (от 0 до 5) (RV) | Воздействие (I = W × RV) |
|---|---|---|---|---|
| F1 | Знаком с моделью проекта, которая используется | 1,5 | ||
| F2 | Опыт применения | 0,5 | ||
| F3 | Объектно-ориентированный опыт | 1,0 | ||
| F4 | Возможность ведущего аналитика | 0,5 | ||
| F5 | мотивация | 1,0 | ||
| F6 | Стабильные требования | 2,0 | ||
| F7 | Частичная занятость | -1,0 | ||
| F8 | Сложный язык программирования | -1,0 | ||
| Общий фактор окружающей среды (EFactor) | ||||
Шаг 3.5 — Рассчитать фактор окружающей среды (EF) как —
1,4 + (-0,03 × EFactor)
Рассчитайте скорректированные точки использования (UCP) как —
UCP = UUCP × TCF × EF
UCP основаны на вариантах использования и могут быть измерены очень рано в жизненном цикле проекта.
UCP (оценка размера) не зависит от размера, навыков и опыта команды, которая реализует проект.
Оценки на основе UCP оказываются близкими к фактическим, когда оценка проводится опытными людьми.
UCP прост в использовании и не требует дополнительного анализа.
Варианты использования широко используются в качестве метода выбора для описания требований. В таких случаях UCP является наиболее подходящим методом оценки.
UCP может использоваться только тогда, когда требования написаны в форме вариантов использования.
Зависит от целенаправленных, хорошо написанных сценариев использования. Если варианты использования не хорошо или равномерно структурированы, результирующее UCP может быть неточным.
Технические факторы и факторы окружающей среды оказывают большое влияние на UCP. Необходимо соблюдать осторожность при назначении значений технических факторов и факторов окружающей среды.
UCP полезен для первоначальной оценки общего размера проекта, но он гораздо менее полезен для управления работой группы от итерации к итерации.
Анализ данных, представленных в статье про метод функциональных точек, подтверждает эффективность применения современных технологий для обеспечения инновационного развития и улучшения качества жизни в различных сферах. Надеюсь, что теперь ты понял что такое метод функциональных точек, точки использования, ucp, function points, измерение производительности труда программистов, линейный подход для оценки производительности труда и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Управление разработкой программных IT проектов
Комментарии
Оставить комментарий
Управление разработкой программных IT проектов
Термины: Управление разработкой программных IT проектов