Лекция
Сразу хочу сказать, что здесь никакой воды про сайт, и только нужная информация. Для того чтобы лучше понимать что такое сайт, веб-сервер, event loop, dns, работа сайта, как работает сайт , настоятельно рекомендую прочитать все из категории Основы интернет и веб технологий.
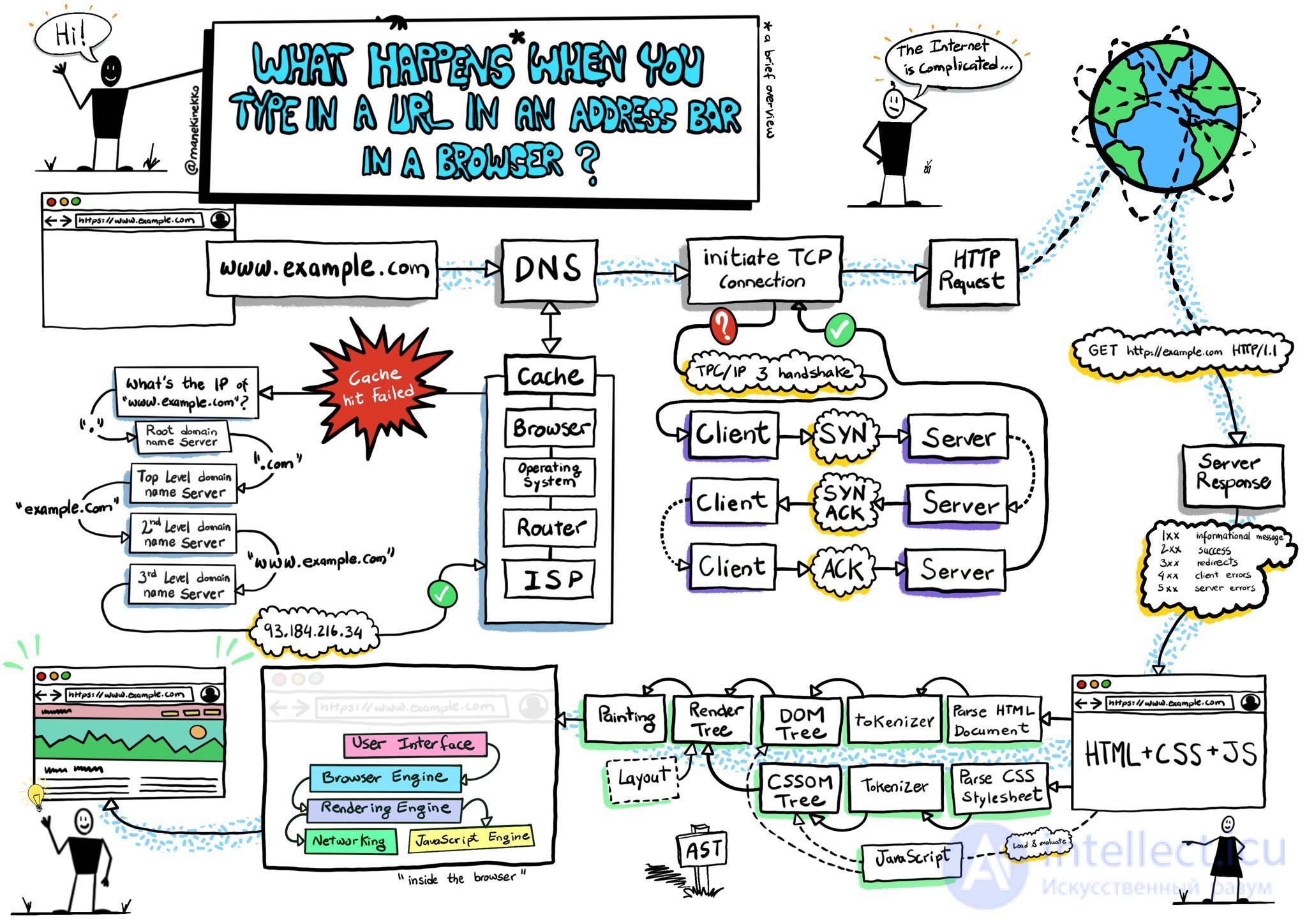
Рассмотрим под микроскопом все что происходит начина от нажатия кнопки на клавиаторе до получением и отображением браузером нужной вебстранице
Сначала вспомним, как работает интернет со стороны браузера
Что делает браузер?
Работа браузера состоит из следующих этапов
Этот процесс помогает браузеру узнать, к какому серверу он должен подключиться, когда пользователь вводит URL. Браузер связывается с DNS-сервером и обнаруживает, что google.com соответствует набору цифр 1.52.201.130 — IP-адресу, к которому может подключиться браузер.
Как только браузер определит, какой сервер будет обслуживать наш запрос, он установит с ним TCP-соединение и начнет HTTP-обмен. Это не что иное, как способ общения браузера с нужным ему сервером, а для сервера — способ отвечать на запросы браузера.
HTTP — это просто название самого популярного протокола для общения в сети, и браузеры в основном выбирают HTTP при общении с серверами. HTTP-обмен подразумевает, что клиент (наш браузер) отправляет запрос, а сервер присылает ответ.
Например, после того, как браузер успешно подключится к серверу, обслуживающему google.com, он отправит запрос, который выглядит следующим образом
GET / HTTP/1.1
Host: intellect.icu
Accept
Давайте разберем запрос построчно:
После того, как браузер, выступающий в роли клиента, завершит выполнение своего запроса, сервер отправит ответ. Вот как выглядит ответ:
HTTP/1.1 200 OK Cache-Control: private, max-age=0 Content-Type: text/html; charset=ISO-8859-1 Server: gws X-XSS-Protection: 1; mode=block X-Frame-Options: SAMEORIGIN Set-Cookie: NID=134; expires=Fri, 11-Jan-2022 11:22:07 GMT; path=/; domain=.intellect.icu; HttpOnly ... ...
Сервер сообщает нам, что запрос был выполнен успешно (200 OK) и добавляет к ответу несколько заголовков, из которых например, можно узнать, какой именно сервер обработал наш запрос (Server: gws), какова политика X-XSS-Protection этого ответа и так далее и тому подобное.
Прямо сейчас вам не нужно понимать каждую строку в ответе. Позже в этой серии публикации мы подробнее расскажем о протоколе HTTP, его заголовках и т. д.
На данный момент все, что вам нужно знать — это то, что клиент и сервер обмениваются информацией и что они делают это через HTTP-протокол.
Последним по счету, но не последним по значению идет процесс рендеринга. Насколько хорош браузер, если единственное, что он покажет пользователю, это список забавных символов?
... ...
В теле ответа сервер включает представление запрашиваемого документа в соответствии с заголовком Content-Type. В нашем случае тип содержимого был установлен на text/html, поэтому мы ожидаем HTML-разметку в ответе — и именно ее мы и находим в теле документа.
Это как раз тот момент, где браузер действительно проявляет свои способности. Он считывает и анализирует HTML-код, загружает дополнительные ресурсы, включенные в разметку (например, там могут быть указаны для подгрузки JavaScript-файлы или CSS-документы) и представляет их пользователю как можно скорее.
Еще раз, конечным результатом должно стать то, что доступно для восприятия для обычного пользователя.
Если вам нужно более детально объяснение того, что действительно происходит, когда мы нажимаем клавишу ввода в адресной строке браузера, я бы предложил прочитать статью «Что происходит, когда…», очень дотошную попытку объяснить механизмы, лежащие в основе этого процесса.
Поскольку это серия посвящена безопасности, я собираюсь дать подсказку о том, что мы только что узнали: злоумышленники легко зарабатывают на жизнь уязвимостями в части HTTP-обмена и рендеринга. Уязвимости, злонамеренные пользователи и прочие фантастические твари встречаются и в других местах, но более эффективный подход к обеспечению защиты именно на упомянутых уровнях уже позволяет вам добиваться успехов в улучшении вашего состояния безопасности.
Помимо борьбы друг с другом, чтобы увеличить свое проникновение на рынок, поставщики также взаимодействуют друг с другом, чтобы улучшить веб-стандарты, которые являются своего рода «минимальными требованиями» для браузеров.
W3C является краеугольным камнем разработки стандартов, но браузеры нередко разрабатывают свои собственные функции, которые в конечном итоге превращаются в веб-стандарты, и безопасность тут не является исключением.
Например, в Chrome 51 были введены файлы cookie SameSite — функция, которая позволила веб-приложениям избавиться от определенного типа уязвимости, известной как CSRF . Другие производители решили, что это хорошая идея, и последовали ее примеру, что привело к тому, что подход SameSite стал веб-стандартом: на данный момент Safari является единственным крупным браузером без поддержки файлов cookie SameSite.
4. Концепция жизненного цикла JS
. Современные JavaScript движки внедряют/имплементируют и существенно оптимизируют этот процесс.

Для лучшего визуального представления работы Event loop,

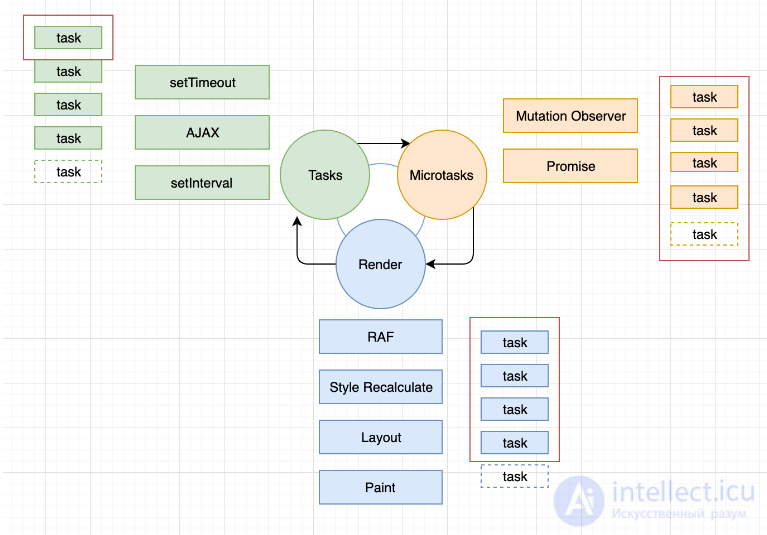
Вызов любой функции создает контекст выполнения (Execution Context). При вызове вложенной функции создается новый контекст, а старый сохраняется в специальной структуре данных - стеке вызовов (Call Stack).
function f(b) {
var a = 12;
return a + b + 35;
}
function g(x) {
var m = 4;
return f(m * x);
}
g(21);
Когда вызывается функция g, создается первый контекст выполнения, содержащий аргументы функции g и локальные переменные. Когда g вызывает f, создается второй контекст с аргументами f и ее локальными переменными. И этот контекст выполнения f помещается в стек вызовов выше первого. Когда f возвращает результат, верхний элемент из стека удаляется. Когда g возвращает результат, ее контекст также удалится, и стек становится пустым.
Объекты размещаются в куче. Куча — это просто имя для обозначения большой неструктурированной области памяти.
Среда выполнения JavaScript содержит очередь задач. Эта очередь — список задач, подлежащих обработке. Каждая задача ассоциируется с некоторой функцией, которая будет вызвана, чтобы обработать эту задачу.
Когда стек полностью освобождается, самая первая задача извлекается из очереди и обрабатывается. Обработка задачи состоит в вызове ассоциированной с ней функции с параметрами, записанными в этой задаче. Как обычно, вызов функции создает новый контекст выполнения и заносится в стек вызовов.
Обработка задачи заканчивается, когда стек снова становится пустым. Следующая задача извлекается из очереди и начинается ее обработка.
Модель событийного цикла (event loop) называется так потому, что отслеживает новые события в цикле:
while(queue.waitForMessage()){
queue.processNextMessage();
}
queue.waitForMessage ожидает поступления задач, если очередь пуста.
Каждая задача выполняется полностью, прежде чем начнет обрабатываться следующая. Благодаря этому мы точно знаем: когда выполняется текущая функция – она не может быть приостановлена и будет целиком завершена до начала выполнения другого кода (который может изменить данные, с которыми работает текущая функция). Это отличает JavaScript от такого языка программирования как C. Поскольку в С функция, запущенная в отдельном потоке, в любой момент может быть остановлена, чтобы выполнить какой-то другой код в другом потоке.
У данного подхода есть и минусы. Если задача занимает слишком много времени, то веб-приложение не может обрабатывать действия пользователя в это время (например, скролл или клик). Браузер старается смягчить проблему и выводит сообщение "скрипт выполняется слишком долго" ("a script is taking too long to run") и предлагает остановить его. Хорошей практикой является создание задач, которые исполняются быстро, и если возможно, разбиение одной задачи на несколько мелких.
В браузерах события добавляются в очередь в любое время, если событие произошло, а так же если у него есть обработчик. В случае, если обработчика нет – событие потеряно. Так, клик по элементу, имеющему обработчик события по событию click , добавит событие в очередь, а если обработчика нет – то и событие в очередь не попадет.
Вызов setTimeout добавит событие в очередь по прошествии времени, указанного во втором аргументе вызова. Если очередь событий на тот момент будет пуста, то событие обработается сразу же, в противном случае событию функции setTimeout придется ожидать завершения обработки остальных событий в очереди. Именно поэтому второй аргумент setTimeout корректно считать не временем, через которое выполнится функция из первого аргумента, а минимальное время, через которое она сможет выполниться.
Нулевая задержка не дает гарантии, что обработчик выполнится через ноль миллисекунд. Вызов setTimeout с аргументом 0 (ноль) не завершится за указанное время. Выполнение зависит от количества ожидающих задач в очереди. Например, сообщение ''this is just a message'' из примера ниже будет выведено на консоль раньше, чем произойдет выполнение обработчика сb1. Это произойдет, потому что задержка – это минимальное время, которое требуется среде выполнения на обработку запроса.
(function () {
console.log('this is the start');
setTimeout(function cb() {
console.log('this is a msg from call back');
});
console.log('this is just a message');
setTimeout(function cb1() {
console.log('this is a msg from call back1');
}, 0);
console.log('this is the end');
})();
// "this is the start"
// "this is just a message"
// "this is the end"
// "this is a msg from call back"
// "this is a msg from call back1"
Web Worker или кросс-доменный фрейм имеют свой собственный стек, кучу и очередь событий. Два отдельных событийных потока могут связываться друг с другом, только через отправку сообщений с помощью метода postMessage. Этот метод добавляет сообщение в очередь другого, если он конечно принимает их.
Очень интересное свойство цикла событий в JavaScript, что в отличие от множества других языков, поток выполнения никогда не блокируется. Обработка I/O обычно осуществляется с помощью событий и функций обратного вызова, поэтому даже когда приложение ожидает запрос от IndexedDB или ответ от XHR, оно может обрабатывать другие процессы, например пользовательский ввод.
Существуют хорошо известные исключения как alert или синхронный XHR, но считается хорошей практикой избегать их использования.
В следующих разделах объясняются действия физической клавиатуры и прерывания ОС. Когда вы нажимаете клавишу «g», браузер получает событие, и включаются функции автозаполнения. В зависимости от алгоритма вашего браузера, если вы находитесь в частном режиме / режиме инкогнито или нет, вам будут представлены различные предложения в раскрывающемся списке под Панель URL. Большинство этих алгоритмов сортируют и определяют приоритеты результатов на основе истории поиска, закладок, файлов cookie и популярных поисковых запросов в Интернете в целом. По мере того как вы набираете "google.com", запускается множество блоков кода, и предложения будут уточняться при каждом нажатии клавиши. Он может даже предложить "google.com", прежде чем вы закончите вводить его.
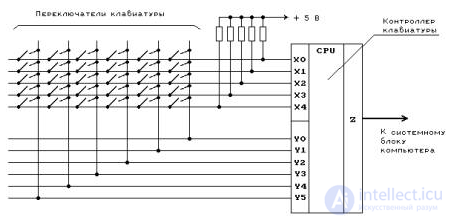
Рис.2.1. Упрощенная схема клавиатуры
Чтобы выбрать нулевую точку, давайте нажмем клавишу Enter на клавиатуре, нажав нижнюю часть ее диапазона. В этот момент электрическая цепь, специфичная для клавиши ввода, замыкается (напрямую или емкостным образом). Это позволяет небольшому количеству тока течь в логическую схему клавиатуры, которая сканирует состояние каждого клавишного переключателя, устраняет электрические помехи быстрого прерывистого замыкания переключателя и преобразует его в целое число кода клавиши, в данном случае 13. Затем контроллер клавиатуры кодирует код клавиши для передачи на компьютер. В настоящее время это почти повсеместно осуществляется через соединение через универсальную последовательную шину (USB) или Bluetooth, но исторически оно осуществляется через соединения PS / 2 или ADB.
В случае USB-клавиатуры:
В случае виртуальной клавиатуры (как в устройствах с сенсорным экраном):
Клавиатура отправляет сигналы в своей строке запроса прерывания (IRQ), которая преобразуется в interrupt vector(целое число) контроллером прерывания. ЦП использует Interrupt Descriptor Table(IDT) для отображения векторов прерываний на функции ( interrupt handlers), которые предоставляются ядром. Когда поступает прерывание, ЦП индексирует IDT с помощью вектора прерывания и запускает соответствующий обработчик. Таким образом, ядро введено.
Транспортный HID передает событие нажатия клавиши KBDHID.sysдрайверу, который преобразует использование HID в скан-код. В этом случае скан-код VK_RETURN( 0x0D). Эти KBDHID.sysинтерфейсы драйверов с KBDCLASS.sys(драйвер клавиатуры класса). Этот драйвер отвечает за безопасную обработку всего ввода с клавиатуры и клавиатуры. Затем он вызывает Win32K.sys(после потенциальной передачи сообщения через установленные сторонние фильтры клавиатуры). Все это происходит в режиме ядра.
Win32K.sysвыясняет, какое окно является активным окном через GetForegroundWindow()API. Этот API предоставляет дескриптор окна адресного поля браузера. Затем звонит главный Windows "насос сообщений" SendMessage(hWnd, WM_KEYDOWN, VK_RETURN, lParam). lParam- это битовая маска, которая указывает дополнительную информацию о нажатии клавиш: количество повторов (в данном случае 0), фактический код сканирования (может зависеть от OEM, но обычно не для VK_RETURN), расширенные клавиши (например, alt, shift, ctrl) тоже давили (их не было) и еще какое-то состояние.
Windows SendMessageAPI - это простая функция, которая добавляет сообщение в очередь для определенного дескриптора окна ( hWnd). Позже для обработки каждого сообщения в очереди вызывается основная функция обработки сообщений (называемая a WindowProc), назначенная для hWnd.
hWndАктивное окно window ( ) на самом деле является элементом управления для редактирования, и WindowProcв этом случае он имеет обработчик сообщений для WM_KEYDOWNсообщений. Этот код просматривает 3-й параметр, который был передан в SendMessage ( wParam), и, поскольку он VK_RETURNзнает, что пользователь нажал клавишу ENTER.
Сигнал прерывания запускает событие прерывания в драйвере клавиатуры kext набора ввода-вывода. Драйвер преобразует сигнал в ключевой код, который передается WindowServerпроцессу OS X. В результате он WindowServerотправляет событие любым подходящим (например, активным или слушающим) приложениям через их порт Mach, где оно помещается в очередь событий. Затем события могут быть прочитаны из этой очереди потоками с достаточными привилегиями, вызывающими mach_ipc_dispatchфункцию. Чаще всего это происходит и обрабатывается в NSApplicationосновном цикле событий с помощью NSEventобъекта of NSEventType KeyDown.
Когда используется графический интерфейс X server, для получения нажатия клавиши Xбудет использоваться общий драйвер событий evdev. Повторное сопоставление кодов клавиш с кодами сканирования выполняется с помощью X serverопределенных раскладок клавиш и правил. Когда отображение скан-кода нажатой клавиши завершено, он X server отправляет символ в window manager(DWM, metacity, i3 и т. Д.), Поэтому, window managerв свою очередь, отправляет символ в сфокусированное окно. Графический API окна, которое принимает символ, печатает соответствующий символ шрифта в соответствующем поле с фокусом.
Сегодня сетевые стеки работают так, чтобы всю тяжелую работу брало на себя ядро. Он начинается с драйверов ядра для карт Ethernet, которые передают пакеты в стек TCP / IP ядра. После приема пакет должен совершить трудный подъем по сетевому стеку, пока, наконец, не перейдет в пользовательский режим. (В пользовательском режиме запускаются приложения).
Вы можете видеть, что у пакета непростая передача.
Если протокол или действительное доменное имя не заданы, браузер переходит к подаче текста, указанного в поле адреса, в поисковую систему браузера по умолчанию. Во многих случаях URL-адрес имеет специальный фрагмент текста, добавленный к нему, чтобы сообщить поисковой системе, что он пришел из строки URL-адреса определенного браузера.

Для отправки широковещательной передачи ARP (протокола разрешения адресов) библиотеке сетевого стека требуется целевой IP-адрес для поиска. Ему также необходимо знать MAC-адрес интерфейса, который он будет использовать для отправки широковещательной передачи ARP.
Кэш ARP сначала проверяется на наличие записи ARP для нашего целевого IP. Если он находится в кэше, библиотечная функция возвращает результат: Target IP = MAC.
Если записи нет в кэше ARP:
ARP Request:
MAC отправителя: интерфейс: mac: адрес: здесь IP отправителя: interface.ip.goes.here Целевой MAC: FF: FF: FF: FF: FF: FF (широковещательный) Целевой IP: target.ip.goes.here
В зависимости от типа оборудования между компьютером и маршрутизатором:
Прямое подключение:
Концентратор:
Коммутатор:
ARP Reply:
MAC-адрес отправителя: target: mac: address: здесь IP отправителя: target.ip.goes.here Целевой MAC: интерфейс: mac: адрес: здесь Целевой IP: interface.ip.goes.here
Теперь, когда сетевая библиотека имеет IP-адрес либо нашего DNS-сервера, либо шлюза по умолчанию, она может возобновить процесс DNS:
Как только браузер получает IP-адрес целевого сервера, он берет его и заданный номер порта из URL-адреса (протокол HTTP по умолчанию - порт 80, а HTTPS - порт 443) и выполняет вызов функции системной библиотеки с именем socketи запрашивает поток сокета TCP - AF_INET/AF_INET6и SOCK_STREAM.
На данный момент пакет готов к передаче через:
Для большинства домашних или малых бизнес-подключений к Интернету пакет будет проходить с вашего компьютера, возможно, через локальную сеть, а затем через модем (MOdulator / DEModulator), который преобразует цифровые единицы и нули в аналоговый сигнал, подходящий для передачи по телефону, кабелю и т. Д. или подключения к беспроводной телефонии. На другом конце соединения находится другой модем, который преобразует аналоговый сигнал обратно в цифровые данные, которые будут обрабатываться следующим сетевым узлом, где адреса отправителя и получателя будут анализироваться дальше.
Большинство крупных предприятий и некоторые новые жилые соединения будут иметь оптоволоконные или прямые соединения Ethernet, и в этом случае данные остаются цифровыми и передаются непосредственно следующему сетевому узлу для обработки.
В конце концов, пакет достигнет маршрутизатора, управляющего локальной подсетью. Оттуда он продолжит движение к пограничным маршрутизаторам автономной системы (AS), другим AS и, наконец, к целевому серверу. Каждый маршрутизатор по пути извлекает адрес назначения из IP-заголовка и направляет его на соответствующий следующий переход. Поле времени жизни (TTL) в заголовке IP уменьшается на единицу для каждого проходящего маршрутизатора. Пакет будет отброшен, если поле TTL достигнет нуля или если у текущего маршрутизатора нет места в очереди (возможно, из-за перегрузки сети).
Эта отправка и получение происходит несколько раз после потока TCP-соединения:
Сервер получает SYN и, если он в хорошем настроении:
Клиент подтверждает соединение, отправляя пакет:
Данные передаются следующим образом:
Чтобы закрыть соединение:
Если используемый веб-браузер был написан Google, вместо отправки HTTP-запроса для получения страницы он отправит запрос, чтобы попытаться согласовать с сервером «обновление» с HTTP до протокола SPDY.
Если клиент использует протокол HTTP и не поддерживает SPDY, он отправляет запрос на сервер формы:
GET / HTTP / 1.1 Хост: intellect.icu
Подключение: закрыть [другие заголовки]
где [other headers]относится к серии пар ключ-значение, разделенных двоеточиями, отформатированных в соответствии со спецификацией HTTP и разделенных одной новой строкой. (Это предполагает , что веб - браузер используется не имеет ошибок , нарушающие HTTP спецификация. Это также предполагает , что веб - браузер использует HTTP/1.1, в противном случае он не может включать в себя Hostзаголовок в запросе и версию , указанном в GETзапросе или будет HTTP/1.0или HTTP/0.9.)
HTTP / 1.1 определяет опцию «закрыть» соединение для отправителя, чтобы сообщить, что соединение будет закрыто после завершения ответа. Например,
Подключение: закрыть
Приложения HTTP / 1.1, которые не поддерживают постоянные соединения, ДОЛЖНЫ включать опцию «закрыть» соединение в каждое сообщение.
После отправки запроса и заголовков веб-браузер отправляет на сервер одну пустую новую строку, указывающую, что содержимое запроса выполнено.
Сервер отвечает кодом ответа, обозначающим статус запроса, и отвечает ответом в форме:
200 ОК [заголовки ответов]
За ним следует один символ новой строки, а затем отправляется полезная нагрузка HTML-содержимого www.google.com. Затем сервер может либо закрыть соединение, либо, если заголовки, отправленные клиентом, запросили его, оставить соединение открытым для повторного использования для дальнейших запросов.
Если заголовки HTTP, отправленные веб-браузером, включали достаточно информации для веб-сервер а, чтобы определить, не изменилась ли версия файла, кэшированного веб-браузером, с момента последнего извлечения (т. Е. Если веб-браузер включил ETagзаголовок), он может вместо этого ответьте запросом в форме:
304 Не изменено [заголовки ответов]
и никакой полезной нагрузки, и вместо этого веб-браузер извлекает HTML из своего кеша.
После анализа HTML веб-браузер (и сервер) повторяет этот процесс для каждого ресурса (изображения, CSS, favicon.ico и т. Д.), На который ссылается HTML-страница, за исключением того, что вместо GET / HTTP/1.1запроса будет GET /$(URL relative to www.google.com) HTTP/1.1.
Если HTML ссылается на ресурс в другом домене www.google.com, веб-браузер возвращается к шагам, связанным с разрешением другого домена, и выполняет все шаги до этого момента для этого домена. В Hostзаголовке запроса будет указано соответствующее имя сервера, а не google.com.
Сервер HTTPD (HTTP Daemon) - это сервер, обрабатывающий запросы / ответы на стороне сервера. Наиболее распространенными серверами HTTPD являются Apache или nginx для Linux и IIS для Windows.
Сервер разбивает запрос на следующие параметры:

После того, как сервер предоставит браузеру ресурсы (HTML, CSS, JS, изображения и т. Д.), Он проходит следующий процесс:
Функциональность браузера заключается в том, чтобы представить выбранный вами веб-ресурс, запросив его с сервера и отобразив в окне браузера. Ресурс обычно представляет собой HTML-документ, но также может быть PDF-файлом, изображением или каким-либо другим типом содержимого. Расположение ресурса указывается пользователем с помощью URI (унифицированного идентификатора ресурса).
То, как браузер интерпретирует и отображает файлы HTML, указано в спецификациях HTML и CSS. Эти спецификации поддерживаются организацией W3C (Консорциум всемирной паутины), которая является организацией по стандартизации Интернета.
Пользовательские интерфейсы браузера имеют много общего друг с другом. Среди общих элементов пользовательского интерфейса:
Структура верхнего уровня браузера
Компоненты браузеров:
Механизм визуализации начинает получать содержимое запрошенного документа с сетевого уровня. Обычно это делается кусками по 8 КБ.
Основная задача парсера HTML - преобразовать разметку HTML в дерево синтаксического анализа.
Выходное дерево («дерево синтаксического анализа») представляет собой дерево элементов DOM и узлов атрибутов. DOM - это сокращение от Document Object Model. Это объектное представление HTML-документа и интерфейс элементов HTML для внешнего мира, например JavaScript. Корнем дерева является объект «Документ». До каких-либо манипуляций с помощью скриптов DOM имеет почти однозначное отношение к разметке.
Алгоритм разбора
HTML нельзя проанализировать с помощью обычных нисходящих или восходящих парсеров.
Причины:
Невозможно использовать обычные методы синтаксического анализа, браузер использует специальный синтаксический анализатор для анализа HTML. Алгоритм парсинга подробно описан в спецификации HTML5.
Алгоритм состоит из двух этапов: токенизации и построения дерева.
Действия после завершения разбора
Браузер начинает получать внешние ресурсы, связанные со страницей (CSS, изображения, файлы JavaScript и т. Д.).
На этом этапе браузер помечает документ как интерактивный и начинает анализировать сценарии, находящиеся в «отложенном» режиме: те, которые должны быть выполнены после анализа документа. Состояние документа устанавливается на «завершено», и запускается событие «загрузка».
Обратите внимание, что на странице HTML никогда не бывает ошибки «Недопустимый синтаксис». Браузеры исправляют любой недопустимый контент и продолжают.
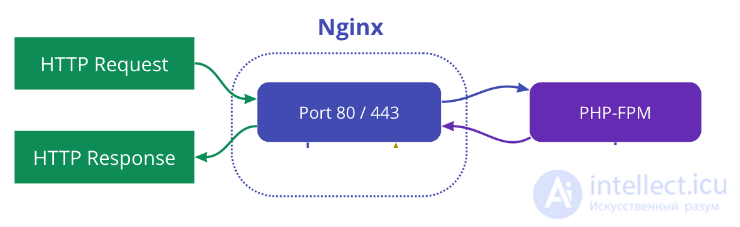
Если на сервер Nginx пришел HTTP-запрос , то Nginx станет передавать данный запрос на выполнение PHP-FPM, Nginx вернет результат полученный из PHP-FPM.
Выполнение PHP - это четырехэтапный процесс:
На следующем изображении показано визуальное представление основного процесса выполнения PHP.
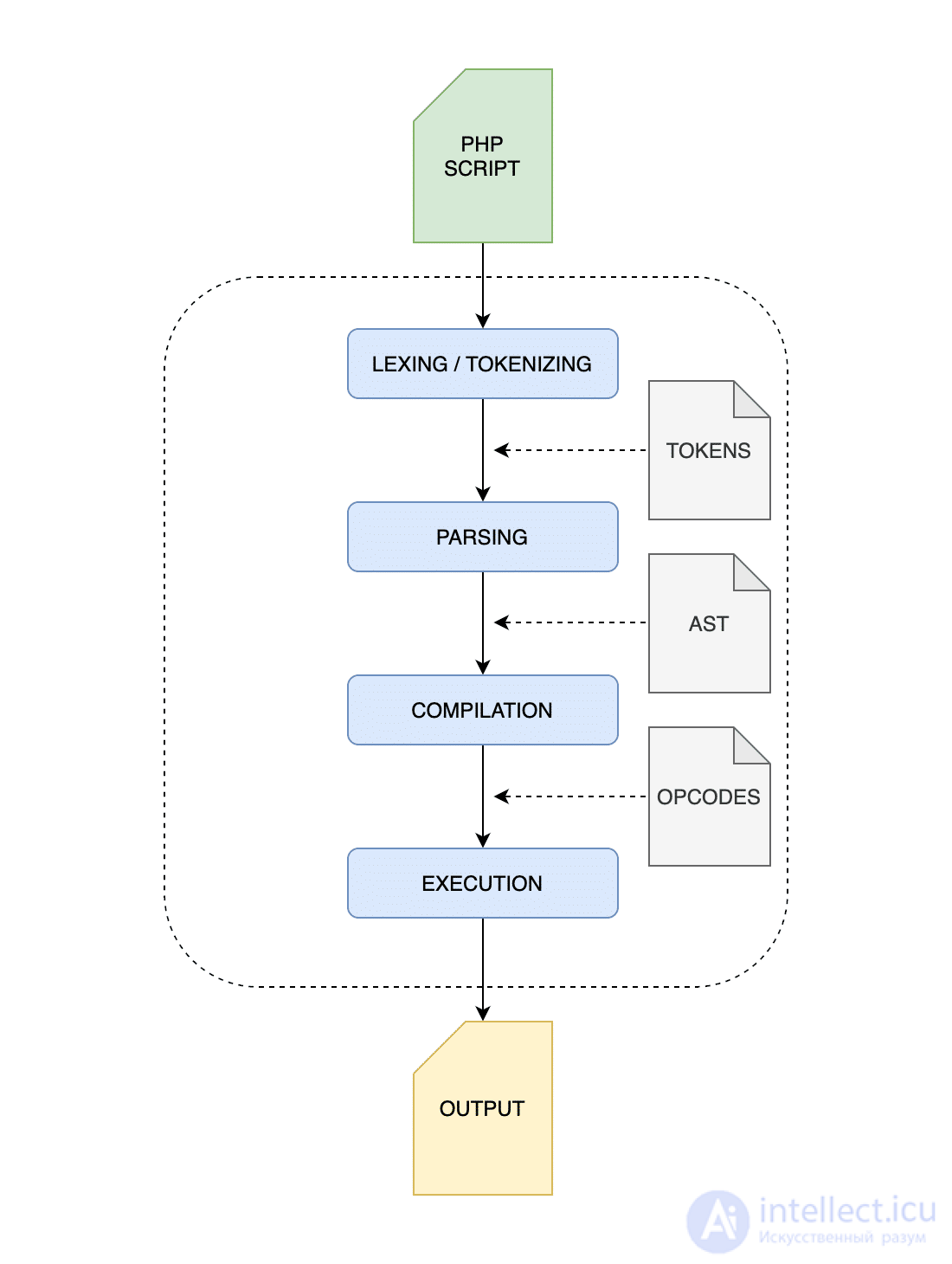
Базовый процесс выполнения PHP
Итак, как OPcache делает PHP быстрее? А что изменится в процессе выполнения с JIT?
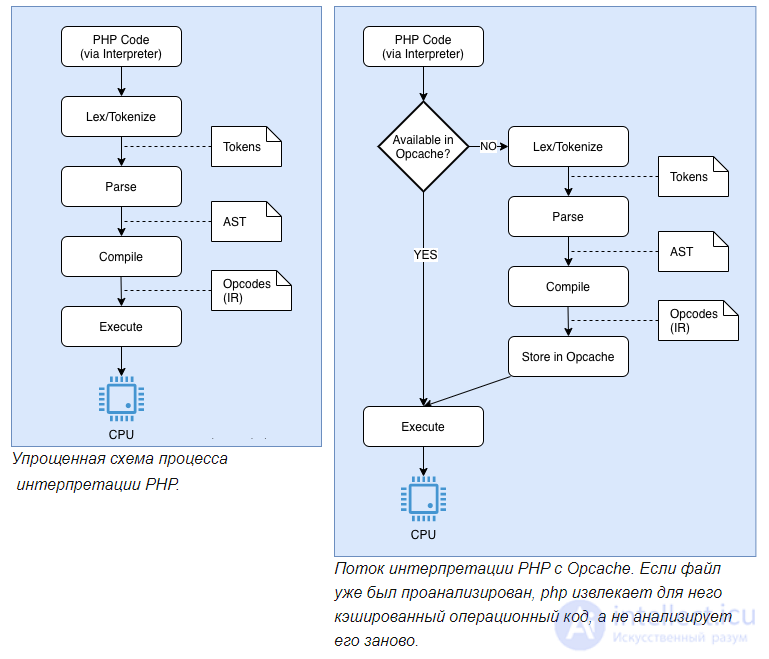
PHP - это интерпретируемый язык. Это означает, что при запуске сценария PHP интерпретатор анализирует, компилирует и выполняет код снова и снова при каждом запросе. Это может привести к потере ресурсов ЦП и дополнительному времени.
Здесь на помощь приходит расширение OPcache :
«OPcache повышает производительность PHP, сохраняя байт-код предварительно скомпилированного сценария в общей памяти, тем самым устраняя необходимость для PHP загружать и анализировать сценарии при каждом запросе».
При включенном OPcache интерпретатор PHP проходит через упомянутый выше четырехэтапный процесс только при первом запуске скрипта. Поскольку байт-коды PHP хранятся в общей памяти, они сразу же доступны как низкоуровневое промежуточное представление и могут быть сразу выполнены на виртуальной машине Zend.
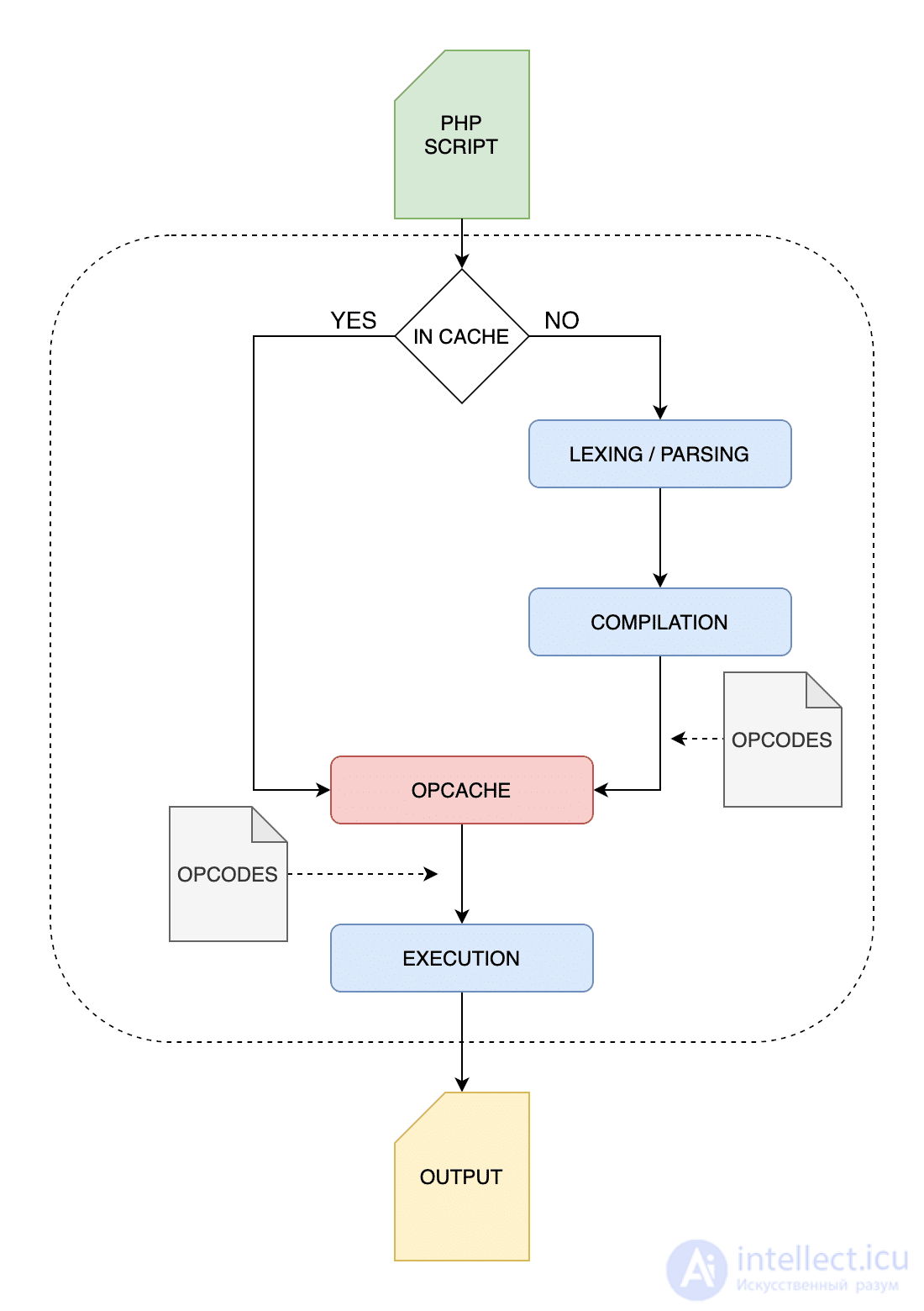
Процесс выполнения PHP с включенным OPcache
Начиная с PHP 5.5, расширение Zend OPcache доступно по умолчанию, и вы можете проверить, правильно ли оно настроено, просто вызвав phpinfo() из скрипта на вашем сервере или проверив файл php.ini
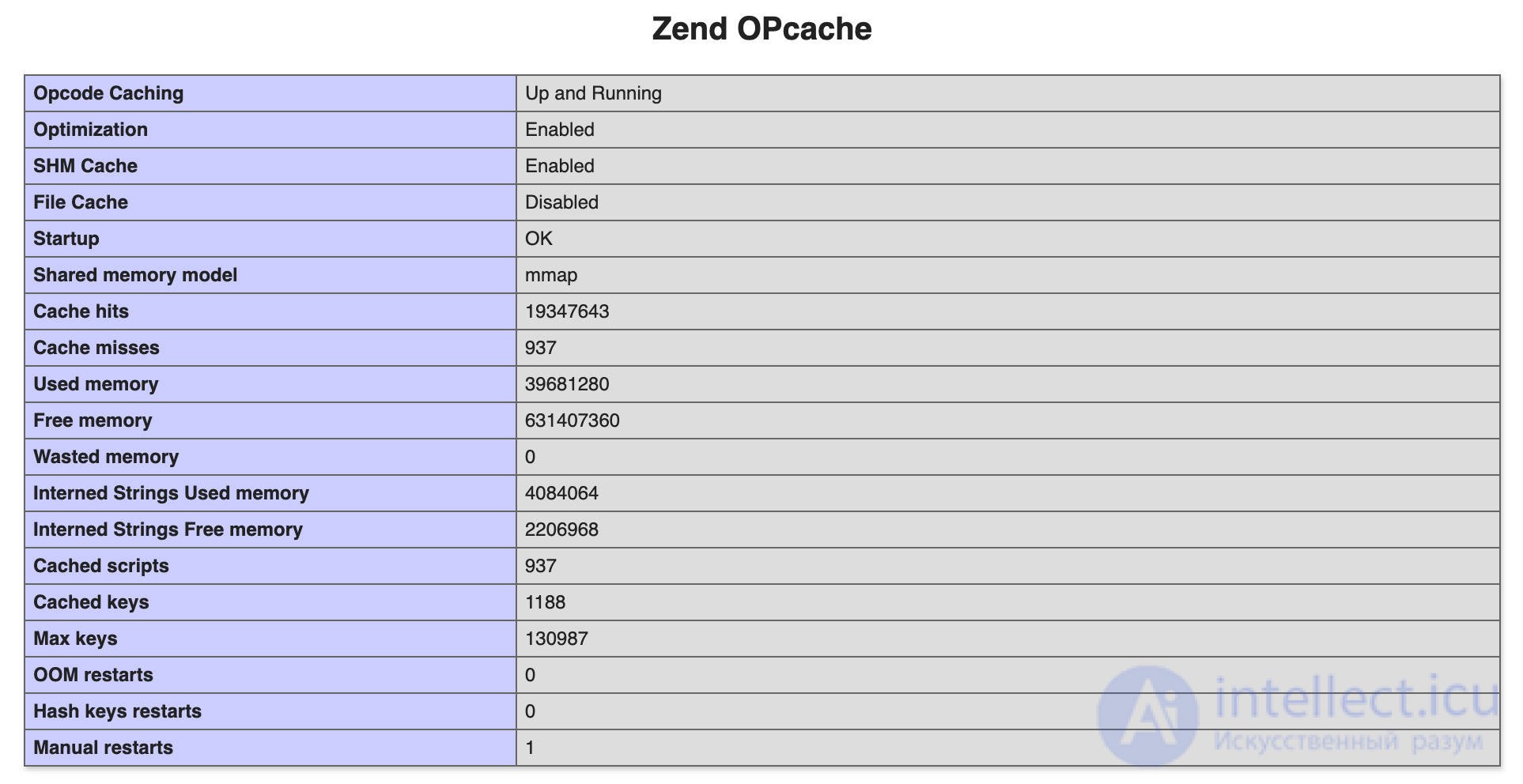
Раздел Zend OPcache на странице phpinfo
OPcache был недавно улучшен за счет реализации предварительной загрузки , новой функции OPcache, добавленной в PHP 7.4 . Предварительная загрузка предоставляет способ сохранить указанный набор сценариев в памяти OPcache « до запуска любого кода приложения. Тем не менее, это не приносит ощутимого улучшения производительности для типичных веб-приложений.
Вы можете узнать больше о предварительной загрузке во введении в PHP 7.4 .
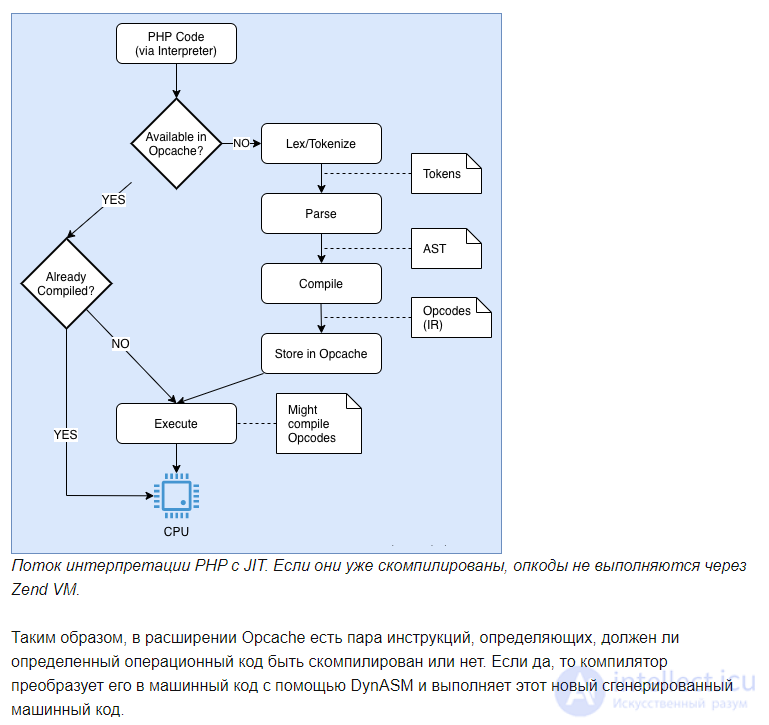
Благодаря JIT PHP делает шаг вперед.
Даже если коды операций представляют собой низкоуровневое промежуточное представление, они все равно должны быть скомпилированы в машинный код. JIT «не вводит дополнительную форму IR (промежуточное представление)», но использует DynASM (динамический ассемблер для механизмов генерации кода) для генерации собственного кода непосредственно из байт-кода PHP.
Короче говоря, JIT переводит горячие части промежуточного кода в машинный код . В обход компиляции можно было бы значительно улучшить производительность и использование памяти.

Структура и логика работы элементарного веб-приложения (написанного на PHP, Java (Servlet) и C# (MVC)) с использованием шаблонизации

А как ты думаешь, при улучшении сайт, будет лучше нам? Надеюсь, что теперь ты понял что такое сайт, веб-сервер, event loop, dns, работа сайта, как работает сайт и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Основы интернет и веб технологий
Комментарии
Оставить комментарий
Основы интернет и веб технологий
Термины: Основы интернет и веб технологий